python爬虫----网易云音乐歌曲爬取并存入Excel
因为数据要存入Excel中,所以首要目标是找个办法将数据能够存入excel中
经过在网上一番搜索后,发现用python里的xlwt模块可以比较容易的解决
一、准备工作
1、安装xlwt模块:
可以看http://blog.csdn.net/junli_chen/article/details/53666309这篇文章
不过好像也可以直接在cmd里用 pip install xlwt 命令安装。不过保险一点就是按链接的文章来操作
2、xlwt的操作:
基本操作:http://www.cnblogs.com/wind-wang/p/5663539.html
xlwt模块列宽、行高heights详解:http://www.bkjia.com/Pythonjc/1073801.html
这两篇文章都写的比较详细了,我就不在赘述了。在这里还是要感谢这些文章的作者
能够分享资料和经验
二、爬虫目的
写这个爬虫的目的主要是抓取在网易云音乐里,华语男歌手top10的歌手的热门歌曲信息。
信息包括歌曲名称,歌曲所属专辑和歌曲的网页链接
三、网页分析
1、首先先打开http://music.163.com/#/discover/artist/cat?id=1001,这个是华语男歌手的页面
然后我们查看下源代码,发现看不到我们想要的信息
这时我们再次右击网页发现有个查看框架的源代码

点进去后就发现了想要的内容

其实还有一种办法,就是点击审查元素,找到一个叫做cat?id=1001的文件

在Response里可以看到代码,然后在Headers里可以看到request URL
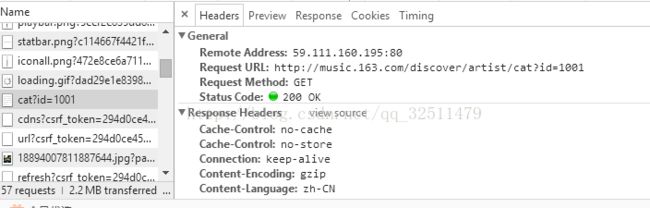
到现在我们可以发现http://music.163.com/#/discover/artist/cat?id=1001这个url不能看到页面的源码,
而http://music.163.com/discover/artist/cat?id=1001这个可以,其实就是有一个"#"的区别
现在点进一个歌手的界面

同样的用查看框架源代码的方法,可以获取到这个页面的源码,接下来就可以爬取了
四、代码思路
0、这2个网页好像并没有弄什么反爬的手段,所以直接爬就行
1、抓取到每个歌手的url和名字,名字可以用在文件存储的时候
2、进入到歌手的界面中可以看到50首热门歌曲,我们要做的就是爬取
这些歌曲的名称,歌曲所属专辑和歌曲链接。期间要用到BeautifulSoup和正则表达式。
3、通过xlwt模块将数据存入Excel
代码:
import xlwt
import requests
from bs4 import BeautifulSoup
import re
def get_url(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('wrong!!!!!!!!!!!!!')
def singer_url(url):
#只抓取前10位的歌手
html = get_url(url)
soup = BeautifulSoup(html,'html.parser')
top_10 = soup.find_all('div',attrs = {'class':'u-cover u-cover-5'})
singers = []
for i in top_10:
singers.append(re.findall(r'.*?.*?',str(i))[0])#问号有问题
#解析的代码和源代码的顺序不同,在用正则表达式的时候要注意
song_info(singers)
def song_info(singers):
url = 'http://music.163.com'
for singer in singers:
try:
new_url = url + str(singer[0])
songs = get_url(new_url)
soup = BeautifulSoup(songs,'html.parser')
Info = soup.find_all('textarea',attrs = {'style':'display:none;'})[0]
songs_url_and_name = soup.find_all('ul',attrs = {'class':'f-hide'})[0]
#print(songs_url_and_name)
datas = []
data1 = re.findall(r'"album".*?"name":"(.*?)".*?',str(Info.text))
data2 = re.findall(r'.*?(.*?) .*?',str(songs_url_and_name))
for i in range(len(data2)):
datas.append([data2[i][1],data1[i],'http://music.163.com/#'+ str(data2[i][0])])
# print(datas)
save_excel(singer,datas)
except:
continue
def save_excel(singer,datas):
fpath = 'E:/python/网易云音乐数据/'
book = xlwt.Workbook()
sheet1 = book.add_sheet('sheet1',cell_overwrite_ok = True)
sheet1.col(0).width = (25*256)
sheet1.col(1).width = (30*256)
sheet1.col(2).width = (40*256)
#xlwt中列宽的值表示方法:默认字体0的1/256为衡量单位。
#xlwt创建时使用的默认宽度为2960,既11个字符0的宽度
#所以我们在设置列宽时可以用如下方法:
#width = 256 * 20 256为衡量单位,20表示20个字符宽度
heads = ['歌曲名称','专辑','歌曲链接']
count = 0
print('正在存入文件......')
for head in heads:
sheet1.write(0,count,head)
count += 1
i = 1
for data in datas:
j = 0
for k in data:
sheet1.write(i,j,k)
j += 1
i += 1
book.save(fpath + str(singer[1]) + '.xls')#括号里写存入的地址
print('OK!')
def main():
url = 'http://music.163.com/discover/artist/cat?id=1001'#华语男歌手页面
singer_url(url)
main()五、问题分析
1、在用BeautifulSoup解析第一个页面时,发现解析出来的数据和源码的顺序不同
例如:
明显的顺序不同,所以在用正则表达式匹配的时候要按解析的数据来匹配
还有这个行代码
singers.append(re.findall(r'.*?.*?',str(i))[0])
artist\?id=\d+2、在获取歌曲信息的时候,textarea标签那段,我用正则表达式不能够很好的获取,每个歌手都有不同的情况。
所以我就在ul标签里获取歌曲链接和名称,在textarea里获取专辑名称

3、最后在看表格文件的时候发现字段太长,实在太难看了。就去搜了下能不能操作下表格中的单元格,
网上的资料还是挺多的,这个操作也不难,就把这个功能加了进去
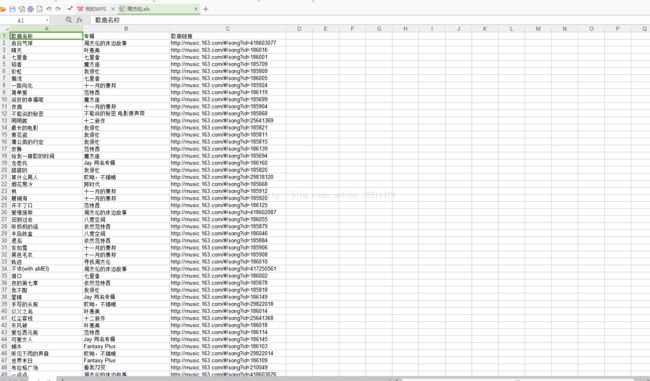
六、结果