java集合整理 Set源码解析
Set存储基本数据类型:
由以下代码我们可以看到Set是存取基本数据类型无序,但是如果基于java8的strean流来说却是有序的。普通的增强for循环打印的结果却是无序的,但是可以保证的是都不可以存储相同的元素。
public static void main(String[] args) throws InterruptedException {
HashSet hs = new HashSet();
hs.add("a");
hs.add("a");
hs.add("b");
hs.add("c");
hs.add("d");
hs.parallelStream().forEach(x -> System.out.println(x));
Thread.sleep(1000);
for (Object object : hs) {
System.err.println(object);
}
}第一次java8遍历结果:
d
a
b
c
第二次普通循环遍历结果:
a
b
c
dSet存储自定义数据类型保证元素的唯一性:
package com.ucap.pojo;
public class Student {
private String name;
private String age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
public Student(String name, String age) {
super();
this.name = name;
this.age = age;
}
}
public static void main(String[] args) throws InterruptedException {
HashSet hs = new HashSet();
Student st1 =new Student("张三","18");
Student st2 =new Student("张三","18");
Student st3 =new Student("李四","33");
Student st4 =new Student("李四","33");
Student st5 =new Student("李四","33");
hs.add(st1);
hs.add(st2);
hs.add(st3);
hs.add(st4);
hs.add(st5);
hs.parallelStream().forEach(x -> System.out.println(x));
Thread.sleep(1000);
for (Object object : hs) {
System.err.println(object);
}
}
结果:
Student [name=李四, age=33]
Student [name=张三, age=18]
Student [name=李四, age=33]
Student [name=张三, age=18]
Student [name=李四, age=33]
Student [name=李四, age=33]
Student [name=李四, age=33]
Student [name=张三, age=18]
Student [name=张三, age=18]
Student [name=李四, age=33]可以看到不管是java 8 的stream还是普通的循环都不能保证HashSet元素的唯一性,相投的元素还是存在相同的
我们再来重写其equals方法
@Override
public boolean equals(Object obj) {
System.out.println("执行否!");
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass()) //字节码对象的比较
return false;
Student other = (Student) obj;//向下转型
if (age == null) {
if (other.age != null)
return false;
} else if (!age.equals(other.age))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}继续遍历:
结果:
Student [name=李四, age=33]
Student [name=张三, age=18]
Student [name=李四, age=33]
Student [name=张三, age=18]
Student [name=李四, age=33]
Student [name=李四, age=33]
Student [name=李四, age=33]
Student [name=张三, age=18]
Student [name=张三, age=18]
Student [name=李四, age=33]依旧是重复的!因为equals根本都没执行。HashSet肯定跟hash值有关,我们从写其hashCode方法
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((age == null) ? 0 : age.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}执行否!
执行否!
执行否!
Student [name=张三, age=18]
Student [name=李四, age=33]
Student [name=李四, age=33]
Student [name=张三, age=18]去重成功。
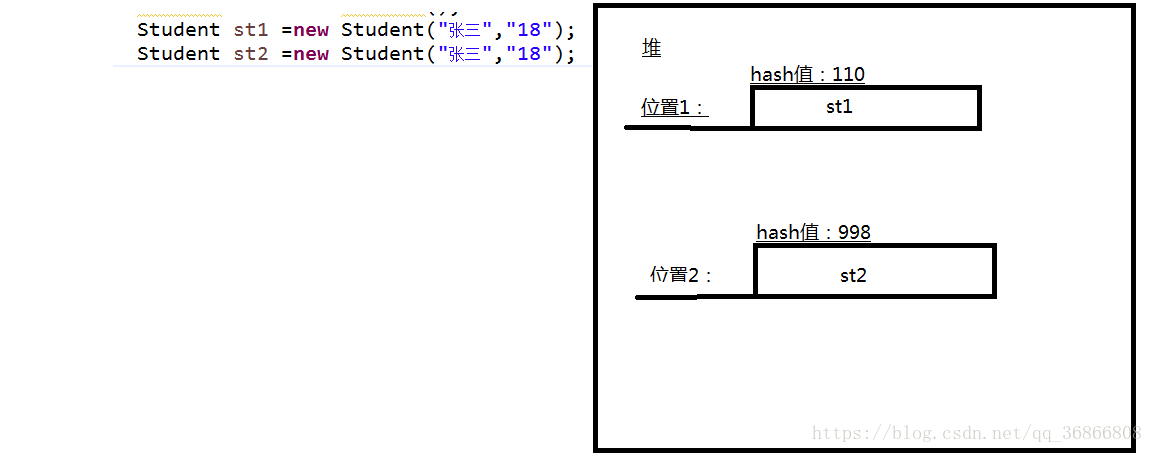
没重写equals之前去重无效的原因是,HashSet中采用的hash来确定是否是唯一元素,比如我们上体中的两个name,age对象虽然都是张三,18但由于他们存储的位置不同,所以就会程序就会判断为不同对象,没有必要进行比较,之后就不会去执行equals方法了。所以我们需要来重写hashCode来让其hashcode值相同,这样才能后续的equals逐级的比较。
所以我们想要让Set保证自定义元素的唯一性,就必须重写其hashCode和equals方法。也就是hashcode相同时,才会去调用equals.
这样就延伸出了HashSet添加元素了,肯定会为添加的当前元素赋hash值,我们来看看HashSet是如何添加元素的:
//HashSet自定义的Map类型的引用
private transient HashMap map;
// 添加双列集合时的value是个固定的Object类,也就是说map的value是固定的,我们新增set时添加的key.因此我们发现,单列集合Set底层是双列集合Map实现的。
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;//为true的话,表名元素不重复,否则重复。我在List源码的add方法提过。
}
我大概解释下关键代码
/**
*默认定义的容器大小
*/
transient Entry[] table = (Entry[]) EMPTY_TABLE;
//进入到map的put方法,我们传入的value是固定的
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key); //计算传入元素的hash
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) { //遍历容器中的存在的元素
Object k;
//若容器中存在的元素与当前元素的hash相同,我们就进行equals方法,如果当前元素对象没重写equals,则执行默认Object中的equals 。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue; //返回原容器存在的值。
}
}
//hash不同的话,添加entry并返回true,保存成功。
modCount++;
addEntry(hash, key, value, i);
return null;
}
LinkedHashSet是HashSet的子类,所以其保证元素的唯一性与父类一致,只不过实现方式是链表方式所以可以保证,存取的顺序一致。我们重点来看下TreeSet.
TreeSet存储String和基本数据类型的
TreeSet hs = new TreeSet();
hs.add("a");
hs.add("a");
hs.add("d");
hs.add("b");
hs.add("c");
for (Object object : hs) {
System.err.println(object);
}
}
结果:
a
b
c
d
自定义类的排序和元素唯一性的保证我这里用的无参构造器!!!(标红):
package com.ucap.pojo;
//实现Comparable并声明泛型!
public class Student implements Comparable{
private String name;
private String age;
public String getName() {
return name;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((age == null) ? 0 : age.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
public Student(String name, String age) {
super();
this.name = name;
this.age = age;
}
//重写方法,返回0说明所有值都重复,后面会贴源码会详解。
@Override
public int compareTo(Student o) {
// TODO Auto-generated method stub
return 0;
}
}
TreeSet hs = new TreeSet();
Student s1 =new Student("赵比","12");
Student s2 =new Student("王比","88");
Student s3 =new Student("赵比","12");
Student s4 =new Student("李比","18");
hs.add(s1);
hs.add(s2);
hs.add(s3);
hs.add(s4);
for (Object object : hs) {
System.err.println(object);
}
} 下面贴的两种构造器是为后面的TreeMap中的put做铺垫
/**
* Constructs a new, empty tree set, sorted according to the
* natural ordering of its elements. All elements inserted into
* the set must implement the {@link Comparable} interface.
* Furthermore, all such elements must be mutually
* comparable: {@code e1.compareTo(e2)} must not throw a
* {@code ClassCastException} for any elements {@code e1} and
* {@code e2} in the set. If the user attempts to add an element
* to the set that violates this constraint (for example, the user
* attempts to add a string element to a set whose elements are
* integers), the {@code add} call will throw a
* {@code ClassCastException}.
*/
public TreeSet() {
//构造方式传入map
this(new TreeMap());
}
/**
* Constructs a new, empty tree set, sorted according to the specified
* comparator. All elements inserted into the set must be mutually
* comparable by the specified comparator: {@code comparator.compare(e1,
* e2)} must not throw a {@code ClassCastException} for any elements
* {@code e1} and {@code e2} in the set. If the user attempts to add
* an element to the set that violates this constraint, the
* {@code add} call will throw a {@code ClassCastException}.
*
* @param comparator the comparator that will be used to order this set.
* If {@code null}, the {@linkplain Comparable natural
* ordering} of the elements will be used.
*/
public TreeSet(Comparatorsuper E> comparator) {
//构造方式传入map
this(new TreeMap<>(comparator));
}
TreeSet可以保证元素的唯一性,和保证排序
/**
* The backing map.
*/
private transient NavigableMap m;
//添加元素
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
NavigableMap连put方法都没我擦,找它的父类看看,依次SortedMap,Map。还是毛都没有。来看看他们的实现类
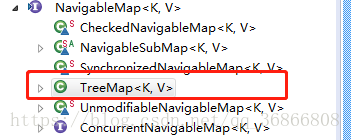
最后在TreeMap中找到了put方法,其他类都没实现put,所以肯定是TreeMap无疑了
//map中定义的root根元素
private transient Entry root;
public V put(K key, V value) {
Entry t = root;
//根是否存在,不存在则将当前元素作为根,用于排序。
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry parent;
// split comparator and comparable paths
Comparator cpr = comparator; //判断当前构造comparator
if (cpr != null) { //如果当前构造不为空,则使用传入对象实现的的compare(key, t.key)方法,也就是我们自定义对象比较需要构造比较器;
do {
//记录当前元素父节点
parent = t;
//当前key,父级节点t比较 (也就是我们重写的compare)
cmp = cpr.compare(key, t.key);
if (cmp < 0) //红黑树比较,当前元素
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value); //等于0的情况就返回原存储数据。
} while (t != null);
}
else { //如果没有传入构造(也就是我们示例的方式),则向上转型使用父类的compareTo,也就是我们在定义Student时声明的泛型:public class Student implements Comparable e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
//红黑树调整
fixAfterInsertion(e);
size++;
modCount++;
return null;
} 以上就是对TreeSet源码的一些简单认识。