用Python实现朴素贝叶斯分类器(MNIST数据集)代码解析
Python 实现朴素贝叶斯分类器代码解析
最近在学李航博士的《统计学习方法》,wds2006sdo在自己的博客中给出了具体实现的算法,但是由于相关改动,代码放到python3中会有很多地方报错,本篇文章将修改正确后的代码pow出来,并且给与详细的解析。
代码解析
首先给出原代码链接:raw_code
下文首先会给出修改后的正确代码和代码的详细解释,最后给出具体的修改细节说明
数据读取
print ('Start read data')
time_1 = time.time()
raw_data = pd.read_csv('resouce/data/train.csv',header=0)
data = raw_data.values
imgs = data[0::,1::]
labels = data[::,0]
# 选取 2/3 数据作为训练集, 1/3 数据作为测试集
train_features, test_features, train_labels, test_labels = train_test_split(imgs, labels, test_size=0.33, random_state=23323)
# print train_features.shape
# print train_features.shape
time_2 = time.time()
print ('read data cost ',time_2 - time_1,' second','\n')
print ('Start training')
prior_probability,conditional_probability = Train(train_features,train_labels)
使用 pd.read_csv 函数读取相对路径 ‘resouce/data/train.csv’ 的数据文件 train.csv,读取到的数据存储在data中,并分离出图像数据和标签数据,分别保存与 imgs 和 labels 变量中。
用 print 查看imgs和labels的具体shape,可得 imgs 和 labels 个数为42000个,imgs的特征(feature)有784个。
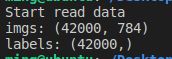
使用 train_test_split 将数据集,标签集分为训练集和测试集,其中 2/3 数据作为训练集, 1/3 数据作为测试集
训练数据
def Train(trainset,train_labels):
prior_probability = np.zeros(class_num) # 先验概率
conditional_probability = np.zeros((class_num,feature_len,2)) # 条件概率
# 计算先验概率及条件概率
for i in range(len(train_labels)):
img = binaryzation(trainset[i]) # 图片二值化
label = train_labels[i]
prior_probability[label] += 1 #统计label标签,对应值的prior_probability[label]加一(用作统计)
for j in range(feature_len):
conditional_probability[label][j][img[j]] += 1#统计特征的个数,在标签为label的条件下,第j个特征(j属于0~784)的[img[j]]取值加一(用作统计)
# 将概率归到[1.10001]
for i in range(class_num):
for j in range(feature_len):
# 经过二值化后图像只有0,1两种取值
pix_0 = conditional_probability[i][j][0] #在标签为i的情况下(label取值0~9),第j个特征(feature取值0~784)为0的个数为pix_0
pix_1 = cdef Train(trainset,train_labels):
prior_probability = np.zeros(class_num) # 先验概率
conditional_probability = np.zeros((class_num,feature_len,2)) # 条件概率
# 计算先验概率及条件概率
for i in range(len(train_labels)):
img = binaryzation(trainset[i]) # 图片二值化
label = train_labels[i]
prior_probability[label] += 1 #统计label标签,对应值的prior_probability[label]加一(用作统计)
for j in range(feature_len):
conditional_probability[label][j][img[j]] += 1#统计特征的个数,在标签为label的条件下,第j个特征(j属于0~784)的[img[j]]取值加一(用作统计)
# 将概率归到[1.10001]
for i in range(class_num):
for j in range(feature_len):
像素点对应的条件概率
probalility_0 = (float(pix_0)/float(pix_0+pix_1))*1000000 + 1
probalility_1 = (float(pix_1)/float(pix_0+pix_1))*1000000 + 1
conditional_probability[i][j][0] = probalility_0
conditional_probability[i][j][1] = probalility_1
return prior_probability,conditional_probability
其中 prior_probability 和 conditional_probability 保存先验概率和后验概率。
binaryzation() 函数将 img 二值化,具体的函数定义如下:
def binaryzation(img):
cv_img = img.astype(np.uint8)
cv2.threshold(cv_img,50,1,cv2.THRESH_BINARY_INV,cv_img)#这个地方python3应该使用cv2.THRESH_BINARY_INV
#处理后在每个img中(784个特征),value大于50的特征判断为0,小于50的为1
return cv_img
其中 threshold 的函数为图像阈值处理函数,具体函数细节见博客:图像阈值处理
这里有一处需要修改的地方:
图像阈值修改
原代码为:
def binaryzation(img):
cv_img = img.astype(np.uint8)
cv2.threshold(cv_img,50,1,cv2.cv.CV_THRESH_BINARY_INV,cv_img)
return cv_img
其中 cv2.cv.CV_THRESH_BINARY_INV 报错
修改为 cv2.THRESH_BINARY_INV即可
预测数据
def Predict(testset,prior_probability,conditional_probability):
predict = []
for img in testset:
# 图像二值化
img = binaryzation(img)
max_label = 0
max_probability = calculate_probability(img,0)
for j in range(1,10):
probability = calculate_probability(img,j)
if max_probability < probability:
max_label = j
max_probability = probability
predict.append(max_label)
return np.array(predict)
预测函数比较简单,因为img的标签label的取值为1到9,因此用一个for循环跑range(1,10)然后用max_label存储概率最高的标签,max_probability 保存计算出的后验概率。其中calculate_probability()是计算后验概率。
计算后验概率
def calculate_probability(img,label):
probability = int(prior_probability[label])
for i in range(len(img)):
probability *= int(conditional_probability[label][i][img[i]])
return probability
这里使用联乘基于以下公式
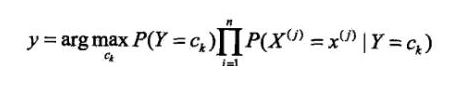
库文件修改
在python3.6中sklearn已弃用train_test_split,导致导入报错
因此若使用raw_code的你可能会遇到这种问题:

此处将代码修改为:
import pandas as pd
import numpy as np
import cv2
import random
import time
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
即用sklearn.model_selection 代替原来的cross_validation
总结:整体还是很好理解的,代码也很好,但是由于没有注解,撸代码的时候有点吃力,也是为了帮帮需要的人吧,写了这篇blog。当然还有最后一个修改,所有的print要带括号