基于Jsoup的Java爬虫-爬取必应壁纸网站的壁纸(Java静态壁纸爬虫实例)
准备阶段
1、必应壁纸网站:https://bing.ioliu.cn(爬取对象网站)
2、Jsoup包下载地址:https://jsoup.org/download(以下代码需要用到该包,记得导入包)
编写工具类
为什么要编写工具类?
答:我之后可能还要写其他类型网站的爬虫,在这里编写个工具类方便以后的开发进行,以及实现代码复用,提高编程效率。
工具类代码如下:
(工具类中有些方法这个爬虫实例可以不会用到,以后可能有机会用到,工具类方法暂且这些,以后我还会继续写上一些使用的方法)
package com.yf.utils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
public class SpiderUtil {
private static String UserAgent = "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)";
private static int TIMEOUT = 30000;//设置访问超时时间(ms)
/**
* 在桌面创建一个名为directoryName的文件夹
*
* @param directoryName
*/
public static File createDirectoryOnDesktop(String directoryName) {
javax.swing.filechooser.FileSystemView fsv = javax.swing.filechooser.FileSystemView.getFileSystemView();
File home = fsv.getHomeDirectory();
File file = new File(home + "/" + directoryName);
if (!file.exists())
file.mkdir();//创建文件夹
return file;
}
/**
* 创建文件夹
*
* @param path
* @return
*/
public static File createDirectory(String path) {
File file = new File(path);
if (!file.exists()) {
file.mkdirs();
}
return file;
}
/**
* 在指定路径下创建一个名为directoryName的文件夹
*
* @param path
* @param directoryName
* @return
*/
public static File createDirectory(String path, String directoryName) {
File file = new File(path, directoryName);
if (!file.exists()) {
file.mkdirs();
}
return file;
}
/**
* 在指定路径下创建一个名为directoryName的文件夹
*
* @param path
* @param directoryName
* @return
*/
public static File createDirectory(File path, String directoryName) {
File file = new File(path, directoryName);
if (!file.exists()) {
file.mkdirs();
}
return file;
}
/**
* 根据url以及xpath获取页面的Elements并将其返回
*
* @param url
* @param xpath
* @return
*/
public static Elements getElementsbyURL(String url, String xpath) {
try {
Document document = Jsoup.parse(new URL(url), TIMEOUT);
Elements elements = document.select(xpath);
return elements;
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
System.out.println("访问" + url.toString() + "超时");
}
return null;
}
/**
* 获取URL的输入流
*
* @param url
* @return
*/
public static InputStream getInpuStream(String url) {
URL imgurl = null;
try {
imgurl = new URL(url);
//通过URL获取URLConnection对象
URLConnection imgconnect = imgurl.openConnection();
//然后添加请求头信息(模糊网站对爬虫的识别,将爬虫看作浏览器访问处理)
imgconnect.setRequestProperty("User-Agent", UserAgent);
//返回URLConnection输入流
return imgconnect.getInputStream();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 下载文件
*
* @param is
* @param os
* @return true下载成功 false下载失败
*/
public static boolean downloadFile(InputStream is, OutputStream os) {
try {
byte[] b = new byte[2048];
int len = 0;
while ((len = is.read(b)) != -1) {
//写入
os.write(b, 0, len);
}
return true;
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭流
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (os != null) {
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return false;
}
}
介绍Jsoup包的方法:
Jsoup.parse(URL url,int timeout)(该实例主要用到该方法)
该方法通过访问url返回Document对象,访问超时会抛出异常,timeout为毫秒级的。
其他有趣的方法请自行百度
爬虫分析
1、观察必应壁纸网站的地址栏,第一页壁纸的url为https://bing.ioliu.cn/ranking?p=1,第二页壁纸的url为https://bing.ioliu.cn/ranking?p=2,必应壁纸网站的每一页的url都是规律的(一般大多数静态网站页面都会有个规律,除非是动态页面用JavaScript实现就需要通过另外一种手段爬取)
2、每一页网站下的壁纸标签以及内容都装在类名为item的div下。
打开类名为item的div的标签

获取图中a标签链接,得到图片次页面链接
进一步爬取
例如:https://bing.ioliu.cn/photo/ChefchaouenMorocco_ZH-CN6127993429?force=ranking_1
public static void main(String[] args) throws IOException {
URL url=new URL("https://bing.ioliu.cn/photo/ChefchaouenMorocco_ZH-CN6127993429?force=ranking_1");
Document document = Jsoup.parse(url, 30000);
//System.out.println(document.toString());
Element element = document.select(".progressive--not-loaded").get(0);
System.out.println(document);
}用Java代码测试输出静态html代码可以看到图片真实url路径在下面的
.progressive--not-loaded类的img标签下

图片路径为:
http://h1.ioliu.cn/bing/LuciolaCruciata_ZH-CN9063767400_1920x1080.jpg
这样就可以设置爬取的规则
主页(.item 一页一共12个item)->获取图片次页面链接
图片次页面(.progressive--not-loaded)获取图片的真实url路径
3、可以看到壁纸图片的源地址(主要爬取对象),图片的描述(爬取用来当文件名),图片拍摄日期,图片浏览量。这些都是可以爬取的内容,用Java写一个嵌套的循环就能够将整个网站的壁纸都爬取下来。
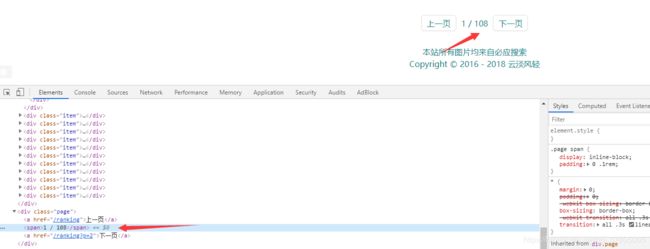
4、怎么获取必应壁纸网站的总页数?
代码实现
package com.yf.spider;
import com.yf.utils.SpiderUtil;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
/**
*必应壁纸爬虫
*/
public class Reptile {
public static void main(String[] args){
//调用工具类在桌面创建一个文件夹
String directoryName="photo";
File photo=SpiderUtil.createDirectoryOnDesktop(directoryName);
//必应壁纸网站
String url="https://bing.ioliu.cn/ranking?p=1";
//获取装在页数内容的页面标签
Elements span=SpiderUtil.getElementsbyURL(url,"span");
//通过字符串操作得到总页数
//装在页数内容的页面标签在最后一个span标签中(观察可知)
String p=span.get(span.size()-1).text();
int intp=Integer.parseInt(p.substring(p.lastIndexOf("/")+2));//总页数
System.out.println("图片总页数为:"+intp);
for(int i=1;i<=intp;i++){
URL tempurl= null;
try {
//通过for循环将页面
tempurl = new URL("https://bing.ioliu.cn/ranking?p="+i);
Document tempdocument=Jsoup.parse(tempurl,Integer.MAX_VALUE);//获取html
//获取当前页面装有图片类名为card的div容器
Elements cards = tempdocument.select("body > div.container > div > div.card");
System.out.println("---------------第"+i+"页开始下载---------------");
System.out.println("------------当前页共有:"+cards.size()+"张图片------------");
for(Element e:cards){
//获取图片链接地址
//获取类名为card的div容器下的第一个a标签的属性href值
String img_href=e.selectFirst("a").attr("href");// photo/LuciolaCruciata_ZH-CN9063767400?force=ranking_1
// 获取img_href页面中的.progressive--not-loaded标签
Elements elements = SpiderUtil.getElementsbyURL("https://bing.ioliu.cn/"+img_href,".progressive--not-loaded");
//http://h1.ioliu.cn/bing/ChefchaouenMorocco_ZH-CN6127993429_1920x1080.jpg?imageslim
String temp = elements.get(0).attr("data-progressive");
//处理后 http://h1.ioliu.cn/bing/ChefchaouenMorocco_ZH-CN6127993429_1920x1080.jpg
String imgsrc = temp.substring(0,temp.lastIndexOf("?"));
System.out.println(imgsrc);
//获取图片名称
//例如:舍夫沙万的蓝色墙壁,摩洛哥 (© Tatsuya Ohinata/Getty Images)
//字符串操作
String str=e.selectFirst("div.description>h3").text().split(" ")[0];//舍夫沙万的蓝色墙壁,摩洛哥
//将字符串中的,和,全部换成---
////舍夫沙万的蓝色墙壁,摩洛哥 --> 舍夫沙万的蓝色墙壁---摩洛哥
String imgname=str.replaceAll(",","---").replaceAll(",","---");
//字符串操作,获取图片链接文件的后缀名(jpg);
String fileType=imgsrc.substring(imgsrc.lastIndexOf("."));
//通过图片链接获取输入流
InputStream is=SpiderUtil.getInpuStream(imgsrc);
OutputStream os=new FileOutputStream(new File(photo,imgname+fileType));//PATH为存储路径
//下载文件
boolean b=SpiderUtil.downloadFile(is,os);
if(b){
System.out.println(imgname+" 下载完成");
}else{
System.out.println(imgname+" 下载失败");
}
// 休眠3秒 防反爬
Thread.sleep(3000);
}
System.out.println("--------------第"+i+"页已下载完成--------------");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
介绍一下谷歌浏览器中的开发者工具中的一个好用的功能,可以用来方便找页面标签
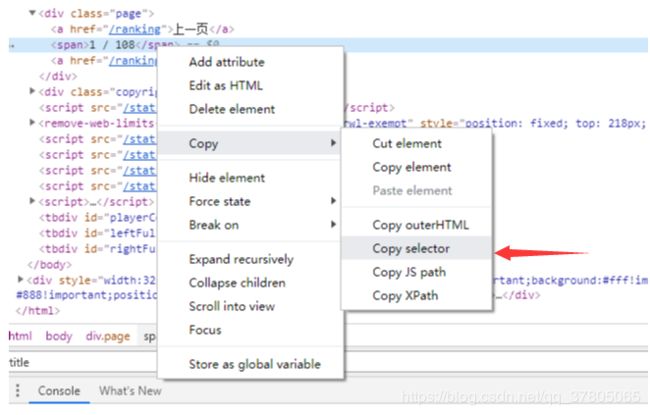
copy的选择器路径是这样的:body > div.page > span,实现代码中有些也是这么做的,不过也不要太过依赖工具。
运行结果
图片总页数为:108
---------------第1页开始下载---------------
------------当前页共有:12张图片------------
舍夫沙万的蓝色墙壁---摩洛哥 下载完成
淡水和盐水在埃斯塔蒂特附近的三河河口交汇---西班牙 下载完成
黄山---中国安徽省 下载完成
哈尔施塔特---奥地利 下载完成
巴扎鲁托群岛---莫桑比克 下载完成
从太空中拍摄到的地球 下载完成
埃特勒塔小镇---法国诺曼底 下载完成
雷尼尔山上空的璀璨银河--- 下载完成
新西兰南岛的塔斯曼湖 下载完成
被萤火虫照亮的小树林---日本四国岛 下载完成
基约夫附近的南摩拉维亚风景---捷克共和国 下载完成
马他奴思卡冰川里的冰隧道---阿拉斯加州 下载完成
--------------第1页已下载完成--------------
---------------第2页开始下载---------------
------------当前页共有:12张图片------------
金塔马尼小镇---巴厘岛---印度尼西亚 下载完成
希腊扎金索斯的沉船湾 下载完成
阿德温山谷的Hallwylfjellet山峰---挪威 下载完成
锡内莫雷茨村上空的英仙座流星雨---保加利亚 下载完成
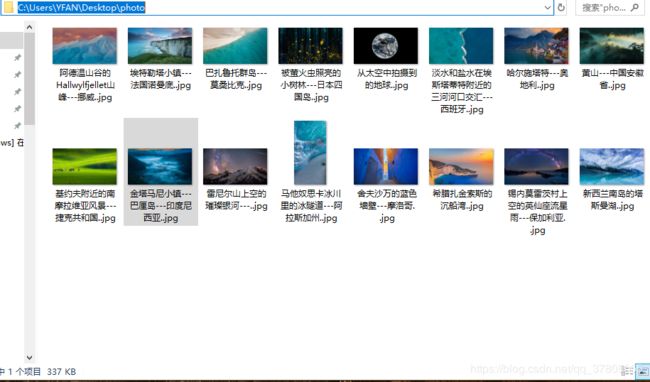
爬取得到的图片:

补充:休眠时间间隔一定要设置,并且设置长一些,不要给人家服务器带来压力!!!