Tensorflow2.0 医学图像分类(X光胸片肺炎图像诊断)
1.数据集
数据集采用的是kaggle上的X光胸片数据集,分为3个文件夹(训练,测试,验证),并包含每个图像类别(肺炎/正常)的子文件夹。共有5,863张X射线图像(JPEG格式)。数据集的所有胸部X射线图像均来自广州市妇女儿童医疗中心的1至5岁的患者。
百度网盘地址:
链接:https://pan.baidu.com/s/1rvev6AWv3yC_5Zn_Kg0k2w
提取码:7591
图片样本:
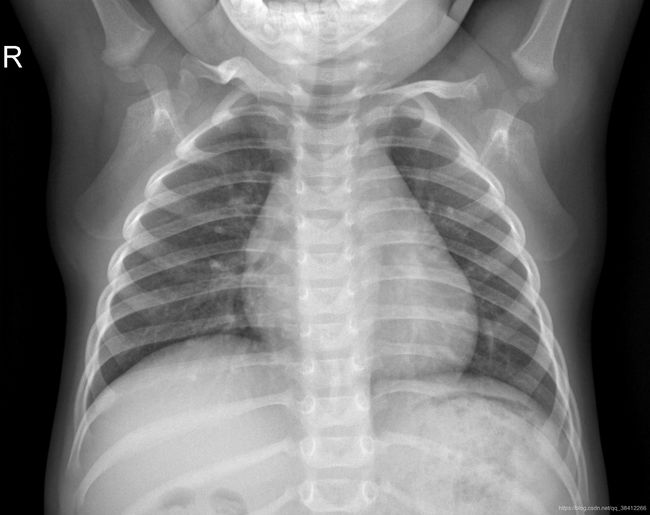
1.正常的肺:
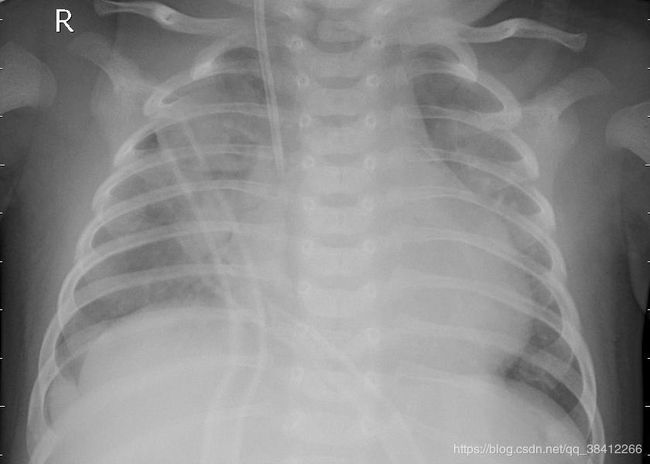
2.细菌性肺炎:
3.病毒性肺炎:

通过以上三张图片可以看出:正常人的肺部X光照片很通透的,没有什么杂质,细菌性肺炎的肺部X光照片不是很清晰,而且有一种被絮状物遮盖的感觉,病毒性肺炎的肺部X光照片也不是很清晰,最突出的特点是左边有一些类似于弹簧的物体。为了简单起见这次实验只分两个种类,一类是正常人的,一类是感染肺炎的(将细菌性肺炎和病毒性肺炎归为一个种类)
2.代码
2.1 导入相应的库
from tensorflow.keras.callbacks import ReduceLROnPlateau,ModelCheckpoint
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import tensorflow as tf
from PIL import Image
import numpy as np
import itertools
import os
2.2 初始设置
图片的宽和高都设置为512,batch_size设置为32,总共训练10个epoch,还有设置模型保存路径,训练集,验证集,测试集路径,由于数据集中valid文件夹下的图片较少,所以将test文件夹里的图片作为验证集,valid文件夹里的图片作为测试集
im_height = 512
im_width = 512
batch_size = 32
epochs = 10
if not os.path.exists("save_weights"):
os.makedirs("save_weights")
image_path = "../input/chest-xray-pneumonia/chest_xray/"
train_dir = image_path + "train"
validation_dir = image_path + "test"
test_dir = image_path + "valid"
2.3 数据预处理
对训练集图片做数据增强,验证集和测试集只做归一化处理
train_image_generator = ImageDataGenerator( rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
validation_image_generator = ImageDataGenerator(rescale=1./255)
test_image_generator = ImageDataGenerator(rescale=1./255)
2.4 生成数据
将训练集数据打乱,训练集和验证集数据不打乱,均采用one-hot编码模式
train_data_gen = train_image_generator.flow_from_directory(directory=train_dir,
batch_size=batch_size,
shuffle=True,
target_size=(im_height, im_width),
class_mode='categorical')
total_train = train_data_gen.n
val_data_gen = validation_image_generator.flow_from_directory(directory=validation_dir,
batch_size=batch_size,
shuffle=False,
target_size=(im_height, im_width),
class_mode='categorical')
total_val = val_data_gen.n
test_data_gen = test_image_generator.flow_from_directory( directory=test_dir,
batch_size=batch_size,
shuffle=False,
target_size=(im_height, im_width),
class_mode='categorical')
total_test = test_data_gen.n
结果:
Found 5216 images belonging to 2 classes.
Found 624 images belonging to 2 classes.
Found 16 images belonging to 2 classes.
训练集一共有5216张图片,验证集一共有624张图片,测试集一共有16张图片,总共2个类别
2.5 构建模型
这里使用的是tensorflow内置的DenseNet201模型,然后将预训练模型冻结,加入全局平均池化层,Dropout层和输出层
covn_base = tf.keras.applications.DenseNet201(weights='imagenet', include_top = False,input_shape=(im_height,im_width,3))
covn_base.trainable = False
model = tf.keras.Sequential()
model.add(covn_base)
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dropout(rate=0.2))
model.add(tf.keras.layers.Dense(2, activation='softmax'))
model.summary()
结果:
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/densenet/densenet201_weights_tf_dim_ordering_tf_kernels_notop.h5
74842112/74836368 [==============================] - 1s 0us/step
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
densenet201 (Model) (None, 16, 16, 1920) 18321984
_________________________________________________________________
flatten (Flatten) (None, 491520) 0
_________________________________________________________________
dropout (Dropout) (None, 491520) 0
_________________________________________________________________
dense (Dense) (None, 2) 983042
=================================================================
Total params: 19,305,026
Trainable params: 983,042
Non-trainable params: 18,321,984
_________________________________________________________________
可以看出,Densenet201模型总共有19,305,026个参数,然而我们只需要训练983,042个参数即可
2.6 编译模型
选用的是adam优化器,初始学习率设置为0.0001,损失函数为交叉熵损失函数
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
loss = 'categorical_crossentropy',
metrics=['accuracy']
)
2.7 开始训练
checkpoint:设置模型保存路径,且根据val_acc保存最优模型
reduce_lr:监视’val_loss’的变化,如果两个轮次不变学习率衰减为原来 的1/10
reduce_lr = ReduceLROnPlateau(
monitor='val_loss',
factor=0.1,
patience=2,
mode='auto',
verbose=1
)
checkpoint = ModelCheckpoint(
filepath='./save_weights/DenseNet201.ckpt',
monitor='val_acc',
save_weights_only=False,
save_best_only=True,
mode='auto',
period=1
)
history = model.fit(x=train_data_gen,
steps_per_epoch=total_train // batch_size,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=total_val // batch_size,
callbacks=[checkpoint, reduce_lr])
结果:
Epoch 1/10
163/163 [==============================] - 479s 3s/step - loss: 0.2023 - accuracy: 0.9408 - val_loss: 0.4601 - val_accuracy: 0.9079 - lr: 1.0000e-04
Epoch 2/10
163/163 [==============================] - 447s 3s/step - loss: 0.1367 - accuracy: 0.9638 - val_loss: 0.3181 - val_accuracy: 0.9293 - lr: 1.0000e-04
Epoch 3/10
163/163 [==============================] - 443s 3s/step - loss: 0.0801 - accuracy: 0.9766 - val_loss: 0.5200 - val_accuracy: 0.9243 - lr: 1.0000e-04
Epoch 4/10
163/163 [==============================] - ETA: 0s - loss: 0.0823 - accuracy: 0.9785
Epoch 00004: ReduceLROnPlateau reducing learning rate to 9.999999747378752e-06.
163/163 [==============================] - 441s 3s/step - loss: 0.0823 - accuracy: 0.9785 - val_loss: 0.7227 - val_accuracy: 0.8914 - lr: 1.0000e-04
Epoch 5/10
163/163 [==============================] - 440s 3s/step - loss: 0.0413 - accuracy: 0.9873 - val_loss: 0.3969 - val_accuracy: 0.9260 - lr: 1.0000e-05
Epoch 6/10
163/163 [==============================] - ETA: 0s - loss: 0.0387 - accuracy: 0.9883
Epoch 00006: ReduceLROnPlateau reducing learning rate to 9.999999747378752e-07.
163/163 [==============================] - 450s 3s/step - loss: 0.0387 - accuracy: 0.9883 - val_loss: 0.4794 - val_accuracy: 0.9112 - lr: 1.0000e-05
Epoch 7/10
163/163 [==============================] - 462s 3s/step - loss: 0.0328 - accuracy: 0.9883 - val_loss: 0.4039 - val_accuracy: 0.9260 - lr: 1.0000e-06
Epoch 8/10
163/163 [==============================] - ETA: 0s - loss: 0.0288 - accuracy: 0.9912
Epoch 00008: ReduceLROnPlateau reducing learning rate to 9.999999974752428e-08.
163/163 [==============================] - 466s 3s/step - loss: 0.0288 - accuracy: 0.9912 - val_loss: 0.3938 - val_accuracy: 0.9309 - lr: 1.0000e-06
Epoch 9/10
163/163 [==============================] - 464s 3s/step - loss: 0.0259 - accuracy: 0.9919 - val_loss: 0.3957 - val_accuracy: 0.9309 - lr: 1.0000e-07
Epoch 10/10
163/163 [==============================] - ETA: 0s - loss: 0.0314 - accuracy: 0.9889
Epoch 00010: ReduceLROnPlateau reducing learning rate to 1.0000000116860975e-08.
163/163 [==============================] - 443s 3s/step - loss: 0.0314 - accuracy: 0.9889 - val_loss: 0.3935 - val_accuracy: 0.9309 - lr: 1.0000e-07
从训练过程可以看出,采用迁移学习模型训练的收敛速度很快,当训练了10个epoch之后已经达到了93%的准确率
2.8 保存模型
将模型保存为.ckpt格式的,且只保存权重
model.save_weights('./save_weights/DenseNet201.ckpt',save_format='tf')
2.9 绘制准确率和损失值曲线
history_dict = history.history
train_loss = history_dict["loss"]
train_accuracy = history_dict["accuracy"]
val_loss = history_dict["val_loss"]
val_accuracy = history_dict["val_accuracy"]
#损失值
plt.figure()
plt.plot(range(epochs), train_loss, label='train_loss')
plt.plot(range(epochs), val_loss, label='val_loss')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('loss')
# 准确率
plt.figure()
plt.plot(range(epochs), train_accuracy, label='train_accuracy')
plt.plot(range(epochs), val_accuracy, label='val_accuracy')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
损失值曲线
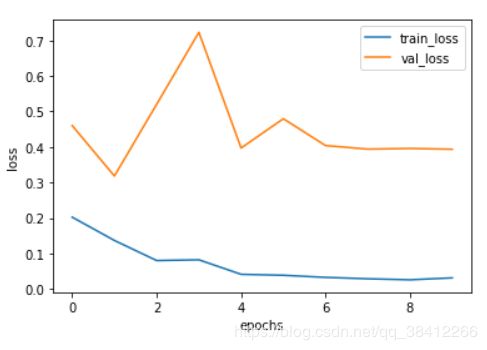
准确率曲线
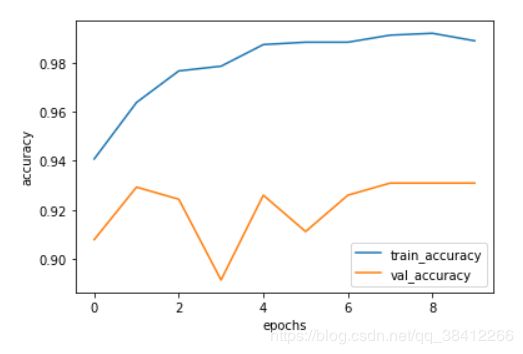
从训练的效果来看,还是存在一些过拟合的现象
2.10 评估模型
2.10.1 在测试集上测试
scores = model.evaluate(test_data_gen, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
结果:
1/1 [==============================] - 0s 1ms/step - loss: 0.0073 - accuracy: 1.0000
Test loss: 0.007296066265553236
Test accuracy: 1.0
在测试集上的准确率为100%,损失值为0.00729
2.10.2 绘制混淆矩阵
def plot_confusion_matrix(cm, target_names,title='Confusion matrix',cmap=None,normalize=False):
accuracy = np.trace(cm) / float(np.sum(cm)) #计算准确率
misclass = 1 - accuracy #计算错误率
if cmap is None:
cmap = plt.get_cmap('Blues') #颜色设置成蓝色
plt.figure(figsize=(10, 8)) #设置窗口尺寸
plt.imshow(cm, interpolation='nearest', cmap=cmap) #显示图片
plt.title(title) #显示标题
plt.colorbar() #绘制颜色条
if target_names is not None:
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45) #x坐标标签旋转45度
plt.yticks(tick_marks, target_names) #y坐标
if normalize:
cm = cm.astype('float32') / cm.sum(axis=1)
cm = np.round(cm,2) #对数字保留两位小数
thresh = cm.max() / 1.5 if normalize else cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): #将cm.shape[0]、cm.shape[1]中的元素组成元组,遍历元组中每一个数字
if normalize: #标准化
plt.text(j, i, "{:0.2f}".format(cm[i, j]), #保留两位小数
horizontalalignment="center", #数字在方框中间
color="white" if cm[i, j] > thresh else "black") #设置字体颜色
else: #非标准化
plt.text(j, i, "{:,}".format(cm[i, j]),
horizontalalignment="center", #数字在方框中间
color="white" if cm[i, j] > thresh else "black") #设置字体颜色
plt.tight_layout() #自动调整子图参数,使之填充整个图像区域
plt.ylabel('True label') #y方向上的标签
plt.xlabel("Predicted label\naccuracy={:0.4f}\n misclass={:0.4f}".format(accuracy, misclass)) #x方向上的标签
plt.show() #显示图片
labels = ['NORMAL','PNEUMONIA']
# 预测验证集数据整体准确率
Y_pred = model.predict_generator(test_data_gen, total_test // batch_size + 1)
# 将预测的结果转化为one hit向量
Y_pred_classes = np.argmax(Y_pred, axis = 1)
# 计算混淆矩阵
confusion_mtx = confusion_matrix(y_true = test_data_gen.classes,y_pred = Y_pred_classes)
# 绘制混淆矩阵
plot_confusion_matrix(confusion_mtx, normalize=True, target_names=labels)
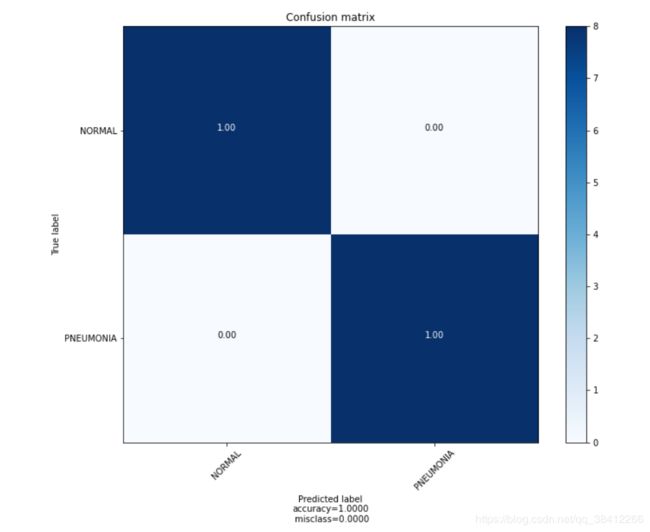
测试集中正常和肺炎预测的准确率均为100%,整体预测的准确率为100%,说明效果还是不错的
2.11 测试模型
抽取出一张测试集图片进行预测
#获取数据集的类别编码
class_indices = train_data_gen.class_indices
#将编码和对应的类别存入字典
inverse_dict = dict((val, key) for key, val in class_indices.items())
#加载测试图片
img = Image.open("../input/chest-xray-pneumonia/chest_xray/val/NORMAL/NORMAL2-IM-1430-0001.jpeg")
# 将图片resize到224x224大小
img = img.resize((im_width, im_height))
#将灰度图转化为RGB模式
img = img.convert("RGB")
# 归一化
img1 = np.array(img) / 255.
# 将图片增加一个维度,目的是匹配网络模型
img1 = (np.expand_dims(img1, 0))
#将预测结果转化为概率值
result = np.squeeze(model.predict(img1))
predict_class = np.argmax(result)
#print(inverse_dict[int(predict_class)],result[predict_class])
#将预测的结果打印在图片上面
plt.title([inverse_dict[int(predict_class)],result[predict_class]])
#显示图片
plt.imshow(img)
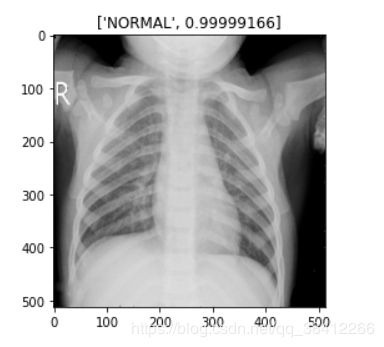
预测结果正确,大功告成!