《Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction》阿里妈妈MLR模型与python代码
MLR 模型可以用于点击率CTR预估(二分类)。
可以先看一下原文下载地址 https://arxiv.org/pdf/1704.05194.pdf 。
数学模型写成了如下形式:
![]()
文中, σ ( x ) σ(x) σ(x)采用Softmax函数, η ( x ) η(x) η(x)采用sigmoid函数,同时, g ( x ) = x g(x)=x g(x)=x,那么上式可以转换成:
![]()
模型的损失函数为包含三部分:交叉熵损失,L2正则化,L1正则化。
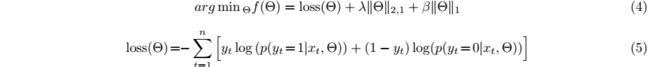
代码部分如下:
import tensorflow as tf
from sklearn.metrics import roc_auc_score
from data import get_data
train_x,train_y,test_x,test_y = get_data()
import pandas as pd
x = tf.placeholder(tf.float32,shape=[None,108])
y = tf.placeholder(tf.float32,shape=[None])
m = 2
learning_rate = 0.3
# 计算Softmax部分
u = tf.Variable(tf.random_normal([108,m],0.0,0.5),name='u')
U = tf.matmul(x,u)
p1 = tf.nn.softmax(U)
# 计算sigmoid部分
w = tf.Variable(tf.random_normal([108,m],0.0,0.5),name='w')
W = tf.matmul(x,w)
p2 = tf.nn.sigmoid(W)
# 预测结果
pred = tf.reduce_sum(tf.multiply(p1,p2),1)
# 损失函数
cost1=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=pred, labels=y))
cost=tf.add_n([cost1])
# 训练器,FtrlOptimizer作为优化器,可以给我们的损失函数加上正则项:
train_op = tf.train.FtrlOptimizer(learning_rate).minimize(cost)
"""
tf.train.FtrlOptimizer
更新方法主要用于广告点击预测,广告点击预测通常千万级别的维度,因此有巨量的稀疏权重.其主要特点是将接近0 的权重直接置0,
这样计算时可以直接跳过,从而简化计算.这个方法已经验证过在股票数据上较有效。
"""
result = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(0, 10000):
f_dict = {x: train_x, y: train_y}
_, cost_, predict_ = sess.run([train_op, cost, pred], feed_dict=f_dict)
auc = roc_auc_score(train_y, predict_)
if epoch % 100 == 0:
f_dict = {x: test_x, y: test_y}
_, cost_, predict_test = sess.run([train_op, cost, pred], feed_dict=f_dict)
test_auc = roc_auc_score(test_y, predict_test)
print("%d cost:%f,train_auc:%f,test_auc:%f" % (epoch, cost_, auc, test_auc))
result.append([epoch,auc,test_auc])