CNN+ELM(基于python,TensorFlow)及对比(附带自己数据)
1.结果对比:CNN,ELM,untrainCNN+ELM(卷积神经网络不经过训练),trainCNN+ELM(卷积神经网络经过训练)
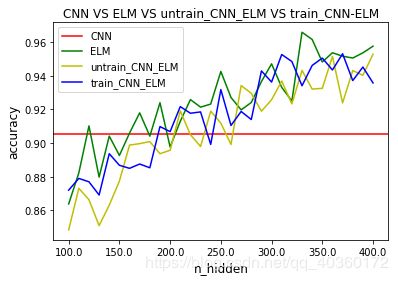
2.ELM主程序来源:参考@QuantumEntanglement
3.可参考方法,结合的方法不一定是最好的,需要自己调试(参数,网络结构等)。
4.近段时间可能不更博了(要努力好好专研啦!),疫情期间利用一点零碎空余时间总结了一部分知识点和代码,希望可以帮到需要的人。自己也是一个人一步步过来的,很理解孤立无援的感觉,祝愿同样在奋斗、在苦苦挣扎的我们都加油,都学有所成!!!最后:致敬英雄,感谢他们的付出,愿山河无恙,国泰民安。
主程序
数据:参考之前博文
(总结的所有程序用的几乎都是一个数据及mnist)
建议:RELM_HiddenLayer,CNN_model可以单独存为一个文件再导入使用,这样方便也更加美观,我这样只是为了博文写的方便,新手比较容易上手。
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 7 21:08:39 2020
@author: 小小飞在路上
"""
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
import warnings
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
import tensorflow as tf
warnings.filterwarnings('ignore')
class RELM_HiddenLayer:
def __init__(self,x,num):
row = x.shape[0]
columns = x.shape[1]
rnd = np.random.RandomState(4444)
self.w = rnd.uniform(-1,1,(columns,num))
self.b = np.zeros([row,num],dtype=float)
for i in range(num):
rand_b = rnd.uniform(-0.4,0.4)
for j in range(row):
self.b[j,i] = rand_b
self.h = self.sigmoid(np.dot(x,self.w)+self.b)
# print(self.H_.shape)
def sigmoid(self,x):
return 1.0 / (1 + np.exp(-x))
def classifisor_train(self,T):
# en_one = OneHotEncoder()
# T = en_one.fit_transform(T.reshape(-1,1)).toarray() #独热编码之后一定要用toarray()转换成正常的数组
if len(T.shape) > 1:
pass
else:
self.en_one = OneHotEncoder()
T = self.en_one.fit_transform(T.reshape(-1, 1)).toarray()
pass
C = 3
I = len(T)
sub_former = np.dot(np.transpose(self.h), self.h) + I / C
all_m = np.dot(np.linalg.pinv(sub_former), np.transpose(self.h))
self.beta = np.dot(all_m, T)
return self.beta
def classifisor_test(self,test_x):
b_row = test_x.shape[0]
h = self.sigmoid(np.dot(test_x,self.w)+self.b[:b_row,:])
result = np.dot(h,self.beta)
result =np.argmax(result,axis=1)
return result
def weight_variables(shape):
"""偏置"""
w=tf.Variable(tf.random_normal(shape=shape,mean=0.0,stddev=1.0,seed=1))
# w=tf.Variable(tf.truncated_normal(shape=shape,mean=0.0,stddev=1.0,seed=1))
return w
def bias_variables(shape):
"""偏置"""
b=tf.Variable(tf.constant(0.0,shape=shape))
return b
def CNN_model(n_future,n_class,n_hidden,n_fc1,future_out):
"""模型结构"""
with tf.variable_scope("data"):
x=tf.placeholder(tf.float32,[None,n_future])
y_true=tf.placeholder(tf.int32,[None,n_class])
keep_prob = tf.placeholder(tf.float32)
with tf.variable_scope("cov1"):
w_conv1=weight_variables([1,3,1,n_hidden])
b_conv1=bias_variables([n_hidden])
x_reshape = tf.reshape(x,[-1,1,n_future,1])
#卷积、激活
x_relu1=tf.nn.relu(tf.nn.conv2d(x_reshape,w_conv1,strides=[1,1,1,1],padding="SAME")+b_conv1)
#池化
x_pool1=tf.nn.max_pool(x_relu1,ksize=[1,1,2,1],strides=[1,1,2,1],padding="SAME")
with tf.variable_scope("conv_fc"):
#全连接
w_fc1=weight_variables([1*future_out*n_hidden,n_fc1])
b_fc1=bias_variables([n_fc1])
x_fc_reshape=tf.reshape(x_pool1,[-1,1*future_out*n_hidden])
y_fc1=tf.matmul(x_fc_reshape,w_fc1)+b_fc1
h_fc1_drop = tf.nn.dropout(y_fc1, keep_prob)
w_fc2=weight_variables([n_fc1,n_class])
b_fc2=bias_variables([n_class])
y_predict=tf.matmul(h_fc1_drop,w_fc2)+b_fc2
with tf.variable_scope("soft_cross"):
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,logits=y_predict))
with tf.variable_scope("opmizer"):
# train_op=tf.train.AdamOptimizer(0.01).minimize(loss)
train_op=tf.train.RMSPropOptimizer(0.001, 0.9).minimize(loss)
with tf.variable_scope("acc"):
Y_truelable=tf.argmax(y_true,1)
Y_predictlable=tf.argmax(y_predict,1)
equal_list=tf.equal(Y_truelable,Y_predictlable)
#equal_list None个样本
accuracy=tf.reduce_mean(tf.cast(equal_list,tf.float32))
return x,y_true,keep_prob,y_fc1,train_op,accuracy
url = 'C:/Users/weixifei/Desktop/TensorFlow程序/data.csv'
data = pd. read_csv(url, sep=',',header=None)
data=np.array(data)
X_data=data[:,:23]
Y=data[:,23]
labels=np.asarray(pd.get_dummies(Y),dtype=np.int8)
X_train,X_,Y_train,Y_=train_test_split(X_data,labels,test_size=0.3,random_state=20)
X_test,X_vld,Y_test,Y_vld=train_test_split(X_,Y_,test_size=0.95,random_state=20)
# In[]
#数据标准化处理
stdsc = StandardScaler()
X_train=stdsc.fit_transform(X_train)
X_test=stdsc.fit_transform(X_test)
X_vld=stdsc.fit_transform(X_vld)
Y_train_1=np.argmax(Y_train,axis=1)
Y_test_1=np.argmax(Y_test,axis=1)
Y_vld_1=np.argmax(Y_vld,axis=1)
# In[]
n_future=23
n_class=12
n_hidden=16
n_fc1=256
if n_future % 2==0:
future_out=n_future//2
else:
future_out=n_future//2+1
#模型调用
x,y_true,keep_prob,y_fc1,train_op,accuracy=CNN_model(n_future,n_class,n_hidden,n_fc1,future_out)
init_op=tf.global_variables_initializer()
training_epochs=1
batch_size = 64
total_batches=X_train.shape[0]//batch_size
ELM_acc=[]
untrain_CNN_ELM_acc=[]
train_CNN_ELM_acc=[]
# In[]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
x_temp1=sess.run(y_fc1,feed_dict={x:X_vld})
x_temp2=sess.run(y_fc1,feed_dict={x:X_test})
for epoch in range(training_epochs):
for i in range(total_batches):
start=(i*batch_size)%X_train.shape[0] #
end=start+batch_size
sess.run(train_op,feed_dict={x:X_train[start:end],y_true:Y_train[start:end],keep_prob:0.5})
if i % 50==0:
print("Epoch %d,Steps %d,validation accuracy:%f"%(epoch+1,i,sess.run(accuracy,feed_dict={x:X_vld,y_true:Y_vld,keep_prob:1})))
CNN_acc=sess.run(accuracy,feed_dict={x:X_test,y_true:Y_test,keep_prob:1})
print("CNN test accuracy:",CNN_acc)
x_temp3=sess.run(y_fc1,feed_dict={x:X_vld})
x_temp4=sess.run(y_fc1,feed_dict={x:X_test})
for j in range(100,401,10):
a= RELM_HiddenLayer(X_vld,j)
a.classifisor_train(Y_vld)
y_predict_1 = a.classifisor_test(X_test)
ELM_acc.append(metrics.precision_score(y_predict_1, Y_test_1, average='macro'))
b = RELM_HiddenLayer(x_temp1,j)
b.classifisor_train(Y_vld)
y_predict_2= b.classifisor_test(x_temp2)
untrain_CNN_ELM_acc.append(metrics.precision_score(y_predict_2, Y_test_1, average='macro'))
c = RELM_HiddenLayer(x_temp3,j)
c.classifisor_train(Y_vld)
y_predict_3= c.classifisor_test(x_temp4)
train_CNN_ELM_acc.append(metrics.precision_score(y_predict_3, Y_test_1, average='macro'))
x=np.linspace(0,30,7)
x_tick=np.linspace(100,400,7)
plt.xticks(x,x_tick)
plt.axhline(CNN_acc,c='r')
plt.plot(ELM_acc,'g')
plt.plot(untrain_CNN_ELM_acc,'y')
plt.plot(train_CNN_ELM_acc,'b')
plt.legend(["CNN","ELM","untrain_CNN_ELM","train_CNN_ELM"])
plt.xlabel('n_hidden',fontsize=12)
plt.ylabel("accuracy",fontsize=12)
plt.title("CNN VS ELM VS untrain_CNN_ELM VS train_CNN-ELM")
# print("CNN-ELM(train)test accuracy:",CNN_ELM_acc)
#