经典遗传算法(SGA)解01背包问题的原理及其python(python3.6)代码实现
1.背包问题
背包问题(knapsack problem)是指从多种物品(项目)中选择几件物品转满背包。假设存在n个不同的物品,对于物品j,其重量为 w j w_j wj,价值为 c j c_j cj,W是背包承受的最大重量,背包问题就是要在不超过背包承受重量的前提下,使装入背包的物品的价值最大。
1.1简单约束的背包问题
背包问题是理论上的NP-Hard问题,目前还没有可求最优解的多项式时间算法。但很多情况下,采用遗传算法在短时间内可以求的较好的解,定义 x j x_j xj为0-1决策变量,如果项目j被选择,则 x j = 1 x_j=1 xj=1,否则 x j = 0 x_j=0 xj=0。下面描述一个简单的带有约束条件的背包问题模型。
编号:
j:物品编号(j=1,2,…,n)
参数:
n:物品个数
W:背包承受的最大重量
w j w_j wj:物品j的重量
c j c_j cj:物品j的价值
决策变量:
x j x_j xj:物品j的决策变量,若物品j被选择放入背包,则 x j = 1 x_j=1 xj=1,否则 x j = 0 x_j=0 xj=0。
数学模型为:
s . t . m a x f ( x ) = ∑ j = 1 n c j x j g ( x ) = ∑ j = 1 n w j x j ⩽ W x j = 0 / 1 , j = 1 , 2 , . . . , n s.t. \begin{matrix} max f(x)=\sum_{j=1}^{n}c_jx_j \\g(x)=\sum_{j=1}^{n}w_jx_j\leqslant W \\x_j=0/1,j=1,2,...,n \end{matrix} s.t.maxf(x)=∑j=1ncjxjg(x)=∑j=1nwjxj⩽Wxj=0/1,j=1,2,...,n
1.2多选择的背包问题
该问题描述为在若干类物品中有约束地选择不同物品放入背包使总价值最大,其数学模型如下:
编号:
i:类的编号(i=1,2,…,m)
j:物品编号(j=1,2,…, n i n_i ni)
参数:
m:类的数量
n i n_i ni:第i类中物品的数量
W:背包承受的最大重量
w i j w_{ij} wij:第i类中第j个物品的重量
c i j c_{ij} cij:第i类中第j个物品的价值
决策变量:
x i j x_{ij} xij:第i类中第j个物品的决策变量,若第i类中第j个物品被选择放入背包,则 x i j = 1 x_{ij}=1 xij=1,否则 x i j = 0 x_{ij}=0 xij=0。
数学模型为:
s . t . m a x f ( x ) = ∑ i = 1 m ∑ j = 1 n i c i j x i j g w ( x ) = ∑ i = 1 m ∑ j = 1 n i w i j x i j ⩽ W g i ( x ) = ∑ j = 1 n i x i j = 1 , ∀ i x j = 0 / 1 , ∀ i , j s.t. \begin{matrix} max f(x)=\sum_{i=1}^{m}\sum_{j=1}^{n_i}c_{ij}x_{ij} \\g_w(x)=\sum_{i=1}^{m}\sum_{j=1}^{n_i}w_{ij}x_{ij}\leqslant W \\g_i(x)=\sum_{j=1}^{n_i}x_{ij}=1,\forall i \\x_j=0/1,\forall i,j \end{matrix} s.t.maxf(x)=∑i=1m∑j=1nicijxijgw(x)=∑i=1m∑j=1niwijxij⩽Wgi(x)=∑j=1nixij=1,∀ixj=0/1,∀i,j
1.3多约束的背包问题
这个问题是从多个类别中选择物品,放入多个背包中,在确保满足背包承重条件的前提下,使放入背包的物品的总价值最大。表达式如下所示。
编号:
i:类的编号(i=1,2,…,m)
j:物品编号(j=1,2,…, n i n_i ni)
参数:
m:类的数量
n i n_i ni:第i类中物品的数量
W i W_i Wi:背包i承受的最大重量
w i j w_{ij} wij:第i类中第j个物品的重量
c i j c_{ij} cij:第i类中第j个物品的价值
决策变量:
x i j x_{ij} xij:第i类中第j个物品的决策变量,若第i类中第j个物品被选择放入背包i,则 x i j = 1 x_{ij}=1 xij=1,否则 x i j = 0 x_{ij}=0 xij=0。
数学模型为:
s . t . m a x f ( x ) = ∑ i = 1 m ∑ j = 1 n i c i j x i j ∑ j = 1 n i w i j x i j ⩽ W i , i = 1 , 2 , . . . , m x j = 0 / 1 , ∀ i , j s.t. \begin{matrix} max f(x)=\sum_{i=1}^{m}\sum_{j=1}^{n_i}c_{ij}x_{ij} \\\sum_{j=1}^{n_i}w_{ij}x_{ij}\leqslant W_i,i=1,2,...,m \\x_j=0/1,\forall i,j \end{matrix} s.t.maxf(x)=∑i=1m∑j=1nicijxij∑j=1niwijxij⩽Wi,i=1,2,...,mxj=0/1,∀i,j
本次实验我们解决1.1问题,其它的问题读者借鉴1.1问题的解决思路即可。
下面我们根据此问题介绍经典的遗传算法。
2. 经典遗传算法
2.1 遗传算法概述
遗传算法是一种基于生物遗传机理,即生物进化(自然淘汰,交叉,变异等)现象的随机搜索算法,它通过计算机模拟生物进化过程来进行搜索和进化,最后寻求最优解,是一种超启发式算法,其中被称为个体的染色体(即研究对象的候选解)的集合能适应外部环境(研究对象的评价函数),并基于下面的规则在每代中生成新个体集合:
(1)越是适应性强的个体,其生存几率越高(自然选择);
(2)以原有个体为基础通过遗传操作生成新个体(遗传现象)。
其中(1)可看做是概率搜索法,(2)是经验搜索法。
2.2 染色体设计(编码和解码)
背包问题的候选解的编码可采用一串长度为物品个数的二进制列来表示,列中的每位表示物品的选择情况,1表示物品被选择,0表示物品未被选中。这样一个一位二进制列即为一个染色体(个体)。以下是算法的伪代码,random[0,1]表示在[0,1]区间内随机产生0或者1。
procedure:binary-string encoding
input:no.of item n
output:chromosome vk
begin
for i=1 to n
vk(i)<--random[0,1];
output:chromosome vk;
end
编码(种群初始化)的python代码如下:
#初始化种群
def init(popsize,n):
population=[]
for i in range(popsize):
pop=''
for j in range(n):
pop=pop+str(np.random.randint(0,2))
population.append(pop)
return population
将编码表现为候选解,就是使1对应的物体被选择,因此解码的伪代码如下:
procedure:binary-string decoding
input:KP data set
chromosome vk
output:profit f(vk),items in knapsack Sk
begin
g<--0;
f<--0;
S<--0;
for i=1 to n
if vk=1 then
if g+wi<=W then
g<--g+wi;
f<--f+ci;
S<--S+{i};
else
break;
end
output:profit f(vk),items in knapsack Sk;
end
解码和适应度函数计算的python代码如下:
#解码1
def decode1(x,n,w,c,W):
s=[]#储存被选择物体的下标集合
g=0
f=0
for i in range(n):
if (x[i] == '1'):
if g+w[i] <= W:
g = g+w[i]
f = f+c[i]
s.append(i)
else:
break
return f,s
#适应度函数1
def fitnessfun1(population,n,w,c,W):
value=[]
ss=[]
for i in range(len(population)):
[f,s]= decode1(population[i],n,w,c,W)
value.append(f)
ss.append(s)
return value,ss
除了上述的解码方式外,我额外提供一种带惩罚函数的解码以及适应度计算的方式,请读者自行思考参阅。
这种带有惩罚项的适应度计算方法如下:
e v a l ( v k ) = { ∑ j ∈ S k c j , ∑ j ∈ S k w j ⩽ W − M ∑ j ∈ S k c j , ∑ j ∈ S k w j > W eval(v_k)=\left \{ \begin{matrix} \sum_{j\in S_k}c_j,\sum_{j\in S_k}w_j\leqslant W \\-M\sum_{j\in S_k}c_j,\sum_{j\in S_k}w_j> W \end{matrix} \right . eval(vk)={∑j∈Skcj,∑j∈Skwj⩽W−M∑j∈Skcj,∑j∈Skwj>W
此方法的解码和适应度函数计算的python代码如下:
#解码2
def decode2(x,n,w,c):
s=[]#储存被选择物体的下标集合
g=0
f=0
for i in range(n):
if (x[i] == '1'):
g = g+w[i]
f = f+c[i]
s.append(i)
return g,f,s
#适应度函数2
def fitnessfun2(population,n,w,c,W,M):
value=[]
ss=[]
for i in range(len(population)):
[g,f,s]= decode2(population[i],n,w,c)
if g>W:
f = -M*f#惩罚
value.append(f)
ss.append(s)
minvalue=min(value)
value=[(i-minvalue+1) for i in value]
return value,ss
2.3 遗传操作
2.3.1轮盘赌模型
轮盘赌模型的基本原理是根据每个染色体的适值比例来确定该个体的选择概率或生存概率。如下面的伪代码那样,个体适应度按比例转换为轮盘的面积并旋转轮盘,最后选择球落点位置所对应的个体。(此处输入可以为父代加子代,也可直接输入子代,具体区别见后面的2.4算法流程)
这里有一些参数说明:
l:染色体索引号
F:所有染色体的适值和
vk:第k个染色体
pk:第k个染色体的选择概率
qk:前k个染色体的累计概率
procedure:roulette wheel selection
input:chromosome Pk,k=1,2,...,popsize+offsize
output:chromosome Pk in next generation
begin
计算适应度函数值eval(Pk);
计算累计适应度F=sum_{k=1->popsize+offsize}eval(Pk);
计算选择概率pk=eval(Pk)/F(k=1,2,...,popsize+offsize);
计算累计概率qk=sum_{i=1->k}pi(k=1,2,...,popsize+offsize);
for k=1 to popsize
r<--random[0,1]
if r<=q1 then
Pl'<--Pk;
else if qk-1轮盘赌的python代码如下;
#轮盘赌选择
def roulettewheel(population,value,pop_num):
fitness_sum=[]
value_sum=sum(value)
fitness=[i/value_sum for i in value]
for i in range(len(population)):##
if i==0:
fitness_sum.append(fitness[i])
else:
fitness_sum.append(fitness_sum[i-1]+fitness[i])
population_new=[]
for j in range(pop_num):###
r=np.random.uniform(0,1)
for i in range(len(fitness_sum)):###
if i==0:
if r>=0 and r<=fitness_sum[i]:
population_new.append(population[i])
else:
if r>=fitness_sum[i-1] and r<=fitness_sum[i]:
population_new.append(population[i])
return population_new
2.3.2两点交叉
两点交叉即在染色体中随机产生两个断点,将这两个断点的中间部位进行交换的交叉方法。此算法父代的双亲个体有可能被多次选择,也可能一次都未选到,即不满足完备性(父代中的个体不是所有都被选择)。此算法也可以让父代的双亲个体都被选择,即满足完备性。以下的算法伪代码为前者,实现的python代码为后者。
参数说明:
pc:交叉概率
p:交叉点
L:为染色体长度
input: pc, parent Pk, k=1, 2, ..., popsize
output: offspring Ck
begin
for k <-- 1 to popsize/2 do
if pc≥random[0,1] then
i<--0;
j<--0;
repeat
i<--random[1,popsize];
j<--random[1,popsize];
until(i≠j)
p<--random[1,L-1];
q<--random[p,L];
Ck<--Pi[1:p]//Pj[p:q]//Pi[q:L];
C(k+popsize/2)<--Pj[1:p]//Pi[p:q]//Pj[q:L];
end
end
output:offspring Ck;
end
两点交叉的python代码如下:
#两点交叉
def crossover(population_new,pc,ncross):
a=int(len(population_new)/2)
parents_one=population_new[:a]
parents_two=population_new[a:]
np.random.shuffle(parents_one)
np.random.shuffle(parents_two)
offspring=[]
for i in range(a):
r=np.random.uniform(0,1)
if r<=pc:
point1=np.random.randint(0,(len(parents_one[i])-1))
point2=np.random.randint(point1,len(parents_one[i]))
off_one=parents_one[i][:point1]+parents_two[i][point1:point2]+parents_one[i][point2:]
off_two=parents_two[i][:point1]+parents_one[i][point1:point2]+parents_two[i][point2:]
ncross = ncross+1
else:
off_one=parents_one[i]
off_two=parents_two[i]
offspring.append(off_one)
offspring.append(off_two)
return offspring
2.3.3反转变异(单点变异)
实现单点变异算子的常用方法1为每条染色体随机生成一个数,此数指示该染色体是否需要变异。如果该染色体需要变异,为其生成一个随机变量,此随机变量指示修改该染色体的哪一位。其算法的伪代码如下:
procedure:mutation1
input: pm, parent Pk, k=1, 2, ..., popsize // pm:变异概率
output: offspring Ck
begin
for k <-- 1 to popsize do
if pm <-- random [0, 1] then
point<--random[0,L-1] // L: 染色体长度
if point = 0
Pk <-- 1-Pk [ 0 ] // Pk[ 1: L ];
else
Pk <-- Pk [1: point-1] // 1-Pk [ point ] // Pk[ point+1: L ];
end
end
Ck =Pk;
end
output:offspring Ck;
end
反转变异1的python代码如下:
#单点变异1
def mutation1(offspring,pm,nmut):
for i in range(len(offspring)):
r=np.random.uniform(0,1)
if r<=pm:
point=np.random.randint(0,len(offspring[i]))
if point==0:
if offspring[i][point]=='1':
offspring[i]='0'+offspring[i][1:]
else:
offspring[i]='1'+offspring[i][1:]
else:
if offspring[i][point]=='1':
offspring[i]=offspring[i][:(point-1)]+'0'+offspring[i][point:]
else:
offspring[i]=offspring[i][:(point-1)]+'1'+offspring[i][point:]
nmut = nmut+1
return offspring
实现单点变异算子的常用方法2为染色体数组中的每个位生成随机变量。此随机变量指示是否将修改特定位。其算法的伪代码如下:
procedure:mutation2
input: pm, parent Pk, k=1, 2, ..., popsize // pm:变异概率
output: offspring Ck
begin
for k <-- 1 to popsize do
for j <-- 1 to L do(基因串长度) // L: 染色体长度
if pm <-- random [0, 1] then
Pk <-- Pk [1: j-1] // 1-Pk [ j ] // Pk[ j+1: L ];
end
end
Ck =Pk;
end
output:offspring Ck;
end
反转变异2的python代码如下:
#单点变异2
def mutation2(offspring,pm,nmut):
for i in range(len(offspring)):
for j in range(len(offspring[i])):
r=np.random.uniform(0,1)
if r<=pm:
if j==0:
if offspring[i][j]=='1':
offspring[i]='0'+offspring[i][1:]
else:
offspring[i]='1'+offspring[i][1:]
else:
if offspring[i][j]=='1':
offspring[i]=offspring[i][:(j-1)]+'0'+offspring[i][j:]
else:
offspring[i]=offspring[i][:(j-1)]+'1'+offspring[i][j:]
nmut = nmut+1
return offspring
2.4 算法流程
应用经典遗传算法对01背包问题求解的总体流程伪代码如下:(此处由于对轮盘赌操作的输入种群不同,因此列出两种python代码,请读者加以区别。)
GA的算法流程为伪代码如下:
procedure:GA for Knapsack Problem(KP)
input: KP data set, GA parameters
output: the best solution
begin
t<-- 0 // t:遗传代数
initialize P(t) by encoding routine; //P(t):染色体种群
fitness eval(P) by decoding routine;
while (not termination condition) do
crossover P(t) to yield C(t); //C(t):offspring
mutation P(t) to yield C(t);
fitness eval(C) by decoding routine;
select P(t+1) from P(t) and C(t);
t<--t+1;
end
output:the best solution;
end
GA的python代码1如下(轮盘赌的输入为父代加子代):
import numpy as np
import matplotlib.pyplot as plt
#主程序----------------------------------------------------------------------------------------------------------------------------------
#参数设置-----------------------------------------------------------------------
gen=1000#迭代次数
pc=0.25#交叉概率
pm=0.02#变异概率
popsize=10#种群大小
n = 20#物品数,即染色体长度n
w = [2,5,18,3,2,5,10,4,8,12,5,10,7,15,11,2,8,10,5,9]#每个物品的重量列表
c = [5,10,12,4,3,11,13,10,7,15,8,19,1,17,12,9,15,20,2,6]#每个物品的代价列表
W = 40#背包容量
M = 5#惩罚值
fun = 1#1-第一种解码方式,2-第二种解码方式(惩罚项)
#初始化-------------------------------------------------------------------------
#初始化种群(编码)
population=init(popsize,n)
#适应度评价(解码)
if fun==1:
value,s = fitnessfun1(population,n,w,c,W)
else:
value,s = fitnessfun2(population,n,w,c,W,M)
#初始化交叉个数
ncross=0
#初始化变异个数
nmut=0
#储存每代种群的最优值及其对应的个体
t=[]
best_ind=[]
last=[]#储存最后一代个体的适应度值
realvalue=[]#储存最后一代解码后的值
#循环---------------------------------------------------------------------------
for i in range(gen):
print("迭代次数:")
print(i)
#交叉
offspring_c=crossover(population,pc,ncross)
#变异
#offspring_m=mutation1(offspring,pm,nmut)
offspring_m=mutation2(offspring_c,pm,nmut)
mixpopulation=population+offspring_m
#适应度函数计算
if fun==1:
value,s = fitnessfun1(mixpopulation,n,w,c,W)
else:
value,s = fitnessfun2(mixpopulation,n,w,c,W,M)
#轮盘赌选择
population=roulettewheel(mixpopulation,value,popsize)
#储存当代的最优解
result=[]
if i==gen-1:
if fun==1:
value1,s1 = fitnessfun1(population,n,w,c,W)
realvalue=s1
result=value1
last=value1
else:
for j in range(len(population)):
g1,f1,s1 = decode2(population[j],n,w,c)
result.append(f1)
realvalue.append(s1)
last=result
else:
if fun==1:
value1,s1 = fitnessfun1(population,n,w,c,W)
result=value1
else:
for j in range(len(population)):
g1,f1,s1 = decode2(population[j],n,w,c)
result.append(f1)
maxre=max(result)
h=result.index(max(result))
#将每代的最优解加入结果种群
t.append(maxre)
best_ind.append(population[h])
#输出结果-----------------------------------------------------------------------
if fun==1:
best_value=max(t)
hh=t.index(max(t))
f2,s2 = decode1(best_ind[hh],n,w,c,W)
print("最优组合为:")
print(s2)
print("最优解为:")
print(f2)
print("最优解出现的代数:")
print(hh)
#画出收敛曲线
plt.plot(t)
plt.title('The curve of the optimal function value of each generation with the number of iterations',color='#123456')
plt.xlabel('the number of iterations')
plt.ylabel('the optimal function value of each generation')
else:
best_value=max(result)
hh=result.index(max(result))
s2 = realvalue[hh]
print("最优组合为:")
print(s2)
print("最优解为:")
print(f2)
GA的python代码2如下(轮盘赌的输入为子代):
import numpy as np
import matplotlib.pyplot as plt
#主程序----------------------------------------------------------------------------------------------------------------------------------
#参数设置-----------------------------------------------------------------------
gen=1000#迭代次数
pc=0.25#交叉概率
pm=0.02#变异概率
popsize=20#种群大小
n = 20#物品数,即染色体长度n
w = [2,5,18,3,2,5,10,4,8,12,5,10,7,15,11,2,8,10,5,9]#每个物品的重量列表
c = [5,10,12,4,3,11,13,10,7,15,8,19,1,17,12,9,15,20,2,6]#每个物品的代价列表
W = 40#背包容量
M = 5#惩罚值
fun = 1#1-第一种解码方式,2-第二种解码方式(惩罚项)
#初始化-------------------------------------------------------------------------
#初始化种群(编码)
population=init(popsize,n)
#适应度评价(解码)
if fun==1:
value,s = fitnessfun1(population,n,w,c,W)
else:
value,s = fitnessfun2(population,n,w,c,W,M)
#初始化交叉个数
ncross=0
#初始化变异个数
nmut=0
#储存每代种群的最优值及其对应的个体
t=[]
best_ind=[]
last=[]#储存最后一代个体的适应度值
realvalue=[]#储存最后一代解码后的值
#循环---------------------------------------------------------------------------
for i in range(gen):
print("迭代次数:")
print(i)
#适应度函数计算
if fun==1:
value,s = fitnessfun1(population,n,w,c,W)
else:
value,s = fitnessfun2(population,n,w,c,W,M)
#轮盘赌选择
population=roulettewheel(population,value,popsize)
#交叉
offspring_c=crossover(population,pc,ncross)
#变异
#offspring_m=mutation1(offspring,pm,nmut)
offspring_m=mutation2(offspring_c,pm,nmut)
population=offspring_m
#储存当代的最优解
result=[]
if i==gen-1:
if fun==1:
value1,s1 = fitnessfun1(population,n,w,c,W)
realvalue=s1
result=value1
last=value1
else:
for j in range(len(population)):
g1,f1,s1 = decode2(population[j],n,w,c)
result.append(f1)
realvalue.append(s1)
last=result
else:
if fun==1:
value1,s1 = fitnessfun1(population,n,w,c,W)
result=value1
else:
for j in range(len(population)):
g1,f1,s1 = decode2(population[j],n,w,c)
result.append(f1)
maxre=max(result)
h=result.index(max(result))
#将每代的最优解加入结果种群
t.append(maxre)
best_ind.append(population[h])
#输出结果-----------------------------------------------------------------------
if fun==1:
best_value=max(t)
hh=t.index(max(t))
f2,s2 = decode1(best_ind[hh],n,w,c,W)
print("最有组合为:")
print(s2)
print("最优解为:")
print(f2)
print("最优解出现的代数:")
print(hh)
#画出收敛曲线
plt.plot(t)
plt.title('The curve of the optimal function value of each generation with the number of iterations',color='#123456')
plt.xlabel('the number of iterations')
plt.ylabel('the optimal function value of each generation')
else:
best_value=max(result)
hh=result.index(max(result))
s2 = realvalue[hh]
print("最优组合为:")
print(s2)
print("最优解为:")
print(f2)
3. 实验结果
本实验参数设置如下:
1.gen=1000#迭代次数
2.pc=0.25#交叉概率
3.pm=0.02#变异概率
4.popsize=20#种群大小
5.n = 20#物品数,即染色体长度n,要与6,7的列表维度保持一致
6.w = [2,5,18,3,2,5,10,4,8,12,5,10,7,15,11,2,8,10,5,9]#每个物品的重量列表
7.c = [5,10,12,4,3,11,13,10,7,15,8,19,1,17,12,9,15,20,2,6]#每个物品的代价列表
8.W = 40#背包容量
9.M = 5#惩罚值
根据上述参数设置和原理分析,我们编程得到每代最优的函数值随进化代数的变化如下图所示。由于两种不同的解码和适应度计算的方式,最后二者的结果呈现方式不同。换句话说,这个图是第一种解码和适应度计算的方式得到的图,请思考为什么第二种方法没有画这个曲线?(提示:带惩罚值的方法每代最优解的适应度值并非背包问题的函数值。)
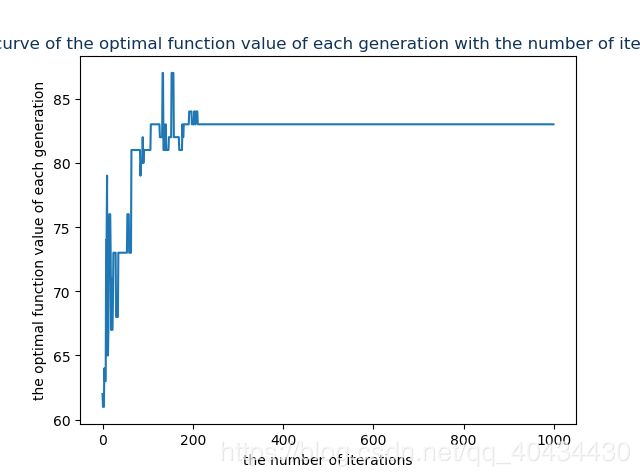
完整的python代码如下:https://download.csdn.net/download/qq_40434430/10743582
由于作者水平有限,以上内容难免有错误之处,如果读者有所发现,请在下面留言告知我,鄙人将不胜感激!
[1]:(日)玄光男, 林林等著. 网络模型与多目标遗传算法[M]. 于歆杰, 梁承姬译. 北京: 清华大学出版社, 2017