数据挖掘之航空公司客户价值分析——K-Means
本文主要包括以下几部分:
1:对航空公司的数据分析去掉无关特征,去掉有误的数据(例如:一年票价为0,第二年票价也是0)
2:根据LCRFM模型选取有关特征,对特征数据进行标准化
3:使用k-means算法模型对特征聚类分析,比较不同类客户的客户价值
4:对不同类客户提供不同的个性化服务,提供不同的营销策略
一 数据探索:
拿到航空公司的数据之后熟悉数据的特征属性,打印一下数据的最大值,最小值与空值
import csv
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples,silhouette_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from datetime import datetime
df = pd.read_csv("air_data.csv",encoding="utf-8")
exp1 = df["SUM_YR_1"].notnull()
exp2 = df["SUM_YR_2"].notnull()
exp = exp1&exp2
new_df = df.loc[exp,:]
explore = df.describe(include="all").T
explore["null"] = len(df)-explore["count"]
print(explore[["null","max","min"]])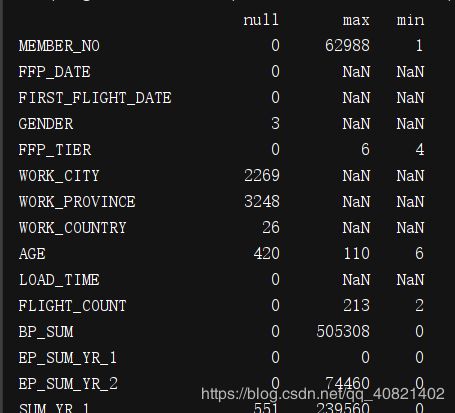
票价不能为空,所以筛选出票价不为空的df,之后票价不能为0,把票价为0或者平均折扣率与飞行总公里数同时为0的的记录去掉。如下代码:
df = df[df["SUM_YR_1"].notnull()*df["SUM_YR_2"].notnull()]# 删除掉SUM_YR_1,SUM_YR_2其中有一个或者都为0的情况
exp1 = df["SUM_YR_1"]!=0
exp2 = df["SUM_YR_2"]!=0
exp3 = (df["SEG_KM_SUM"] ==0) & (df["avg_discount"] ==0)
exp = df[exp1|exp2|exp3]
二 选取有关特征并进行建模分析:
之后我们就得到了相对干净的数据,根据航空公司的业务来看,从所有的属性中删选出几个最有价值的属性,根据航空公司的LRFMC模型,分别代表:会员入会时间距观测窗口结束的月数,客户最近一次乘坐公司飞机距观测窗口结束的月数,客户在观测窗口内乘坐公司飞机的次数,客户在观测时间内在公司累计的飞行里程,客户在观测时间内乘坐舱位所对应的折扣系数的平均值。
L = LOAD_TIME-FFP_DATE
R=LAST_TO_END
F=FLIGHT_COUNT
M=SEG_KMSUM
C=AVG_DISCOUNT
计算出这五个属性并且对属性值进行标准化处理
new_df = df[["LOAD_TIME","FFP_DATE","LAST_TO_END","FLIGHT_COUNT","SEG_KM_SUM","avg_discount"]]
new_df["L"] = (pd.to_datetime(new_df["LOAD_TIME"])-pd.to_datetime(new_df["FFP_DATE"]))/np.timedelta64(1,'D')
new_df = new_df.iloc[:,2:]
new_df = new_df.rename(columns = {"LAST_TO_END":"R","FLIGHT_COUNT":"F","SEG_KM_SUM":"M","avg_discount":"C"})
new_df.insert(0,"L",new_df.pop("L"))处理完了之后就要开始对数据训练聚类把数据聚类聚成五类,把聚类中心和据类的类别次数放到同一个dataframe里可以直观的看到不同簇的大小以及不同簇的聚类中心点。在这里采用的是轮廓系数对聚类的效果进行评估,轮廓系数大于0的聚类是好的聚类,越接近1,聚类效果就越好。本次的聚类轮廓系数0.277
trf_data = data_change()
K_model = KMeans(n_clusters=5,n_jobs=4,random_state=132)
K_model.fit(trf_data)
print(silhouette_score(trf_data,K_model.labels_))# 查看轮廓系数
# print(K_model.cluster_centers_)# 查看聚类中心
ser = pd.Series(K_model.labels_).value_counts()
after_df = pd.DataFrame(K_model.cluster_centers_,columns = ["ZL","ZR","ZF","ZM","ZC"])
after_df["类别"] = ser.index
after_df["次数"] = ser.values
after_df.to_csv("final_data.csv")
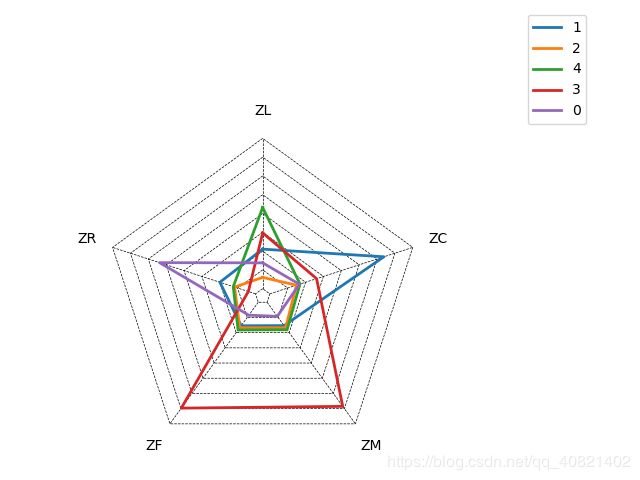
然后对已有的分类画出雷达图:
三 对不同类客户进行不同的个性化服务:
重要保持客户:
平均折扣率(C)比较高,因为其购买你舱位的等级比较高,最近乘坐过本公司航班(R)低,乘坐的次数(F)或里程(M)较高,他们是航空公司的高价值客户。是最理想的客户类型,对航空公司贡献最大,所占的比例却比较小,航空公司应该优先将资源投放到他们身上,对他们进行差异化管理一对一营销,提高这类客户的忠诚度和满意度尽可能延长这类客户的高水平消费。
重要发展客户:
这类客户的平均折扣率(C)比较高,最近乘坐过本公司航班(R)低,但是乘坐次数(F)或乘坐里程(M)低,这类客户入会时常(L)短,他们是航空公司的潜在价值客户,虽然这类客户的潜在价值并不是很高,但是却有很大的发展潜力,航空公司要努力促使这类客户增加在本公司的乘机消费和合作伙伴处的消费,也就是增加客户的钱包份额,通过客户价值的提升,加强这类客户的满意度。提高他们转向竞争对手的转移成本,使他们逐渐成为公司的忠实客户。
重要挽留客户:
这类客户过去所乘航班的平均折扣率(C)很低,乘坐次数(F)或者里程(M)比较高 较长时间没有乘坐过本公司的航班(R)或者是乘坐的频率变小,他们客户变化的不确定性很高,,由于这些客户衰退原因各不相同,所以掌握客户的最新信息,维持与客户的互动就显得尤其重要,,航空公司应该根据客户的最近消费时间,消费次数的变化,,推测客户的消费异东情况,并列出消费名单对其重点联系,采取一定的应销售手段,延长客户的生命周期。
一般与低价值客户:
这类客户所乘航班的平均折扣率(c)低,较长时间没有乘坐过本公司的航班(R)高,乘坐的次数或者里程(M)低,入会时长短,他们是航空公司的一般价值客户,可能在公司打折促销时才会乘坐公司航班。
完整代码:
import csv
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples,silhouette_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from datetime import datetime
def data_view():
df = pd.read_csv("air_data.csv", encoding="utf-8")
explore = df.describe(include="all").T
explore["null"] = len(df)-explore["count"]
print(explore[["null","max","min"]])
def data_expore():
df = pd.read_csv("air_data.csv",encoding="utf-8")
df = df[df["SUM_YR_1"].notnull()*df["SUM_YR_2"].notnull()]# 删除掉SUM_YR_1,SUM_YR_2其中有一个或者都为0的情况
exp1 = df["SUM_YR_1"]!=0
exp2 = df["SUM_YR_2"]!=0
exp3 = (df["SEG_KM_SUM"] ==0) & (df["avg_discount"] ==0)
exp = df[exp1|exp2|exp3]
exp.to_csv("air_data_cleared.csv.csv")
def data_change():
df = pd.read_csv("air_data_cleared.csv", encoding="utf-8")
new_df = df[["LOAD_TIME","FFP_DATE","LAST_TO_END","FLIGHT_COUNT","SEG_KM_SUM","avg_discount"]]
new_df["L"] = (pd.to_datetime(new_df["LOAD_TIME"])-pd.to_datetime(new_df["FFP_DATE"]))/np.timedelta64(1,'D')
new_df = new_df.iloc[:,2:]
new_df = new_df.rename(columns = {"LAST_TO_END":"R","FLIGHT_COUNT":"F","SEG_KM_SUM":"M","avg_discount":"C"})
new_df.insert(0,"L",new_df.pop("L"))
sdd = StandardScaler()
new_df = sdd.fit_transform(new_df.values)
return new_df
def data_model():
trf_data = data_change()
K_model = KMeans(n_clusters=5,n_jobs=4,random_state=132)
K_model.fit(trf_data)
print(silhouette_score(trf_data,K_model.labels_))# 查看轮廓系数
# print(K_model.cluster_centers_)# 查看聚类中心
ser = pd.Series(K_model.labels_).value_counts()
after_df = pd.DataFrame(K_model.cluster_centers_,columns = ["ZL","ZR","ZF","ZM","ZC"])
after_df["类别"] = ser.index
after_df["次数"] = ser.values
after_df.to_csv("final_data.csv")
import numpy as np
import matplotlib.pyplot as plt
def plot_radar():
'''
the first column of the data is the cluster name;
the second column is the number of each cluster;
the last are those to describe the center of each cluster.
'''
data = pd.read_csv("final_data.csv", encoding="utf-8")
data.insert(0,"类别",data.pop("类别"))
data.insert(1,"数量",data.pop("次数"))
data = data.drop("Unnamed: 0",axis=1)
# print(data)
# exit()
kinds = data.iloc[:, 0]
labels = data.iloc[:, 2:].columns
centers = pd.concat([data.iloc[:, 2:], data.iloc[:, 2]], axis=1)
centers = np.array(centers)
n = len(labels)
angles = np.linspace(0, 2 * np.pi, n, endpoint=False)
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure()
ax = fig.add_subplot(111, polar=True) # 设置坐标为极坐标
# 画若干个五边形
floor = np.floor(centers.min()) # 大于最小值的最大整数
ceil = np.ceil(centers.max()) # 小于最大值的最小整数
for i in np.arange(floor, ceil + 0.5, 0.5):
ax.plot(angles, [i] * (n + 1), '--', lw=0.5, color='black')
# 画不同客户群的分割线
for i in range(n):
ax.plot([angles[i], angles[i]], [floor, ceil], '--', lw=0.5, color='black')
# 画不同的客户群所占的大小
for i in range(len(kinds)):
ax.plot(angles, centers[i], lw=2, label=kinds[i])
# ax.fill(angles, centers[i])
ax.set_thetagrids(angles * 180 / np.pi, labels) # 设置显示的角度,将弧度转换为角度
plt.legend(loc='lower right', bbox_to_anchor=(1.5, 1)) # 设置图例的位置,在画布外
ax.set_theta_zero_location('N') # 设置极坐标的起点(即0°)在正北方向,即相当于坐标轴逆时针旋转90°
ax.spines['polar'].set_visible(False) # 不显示极坐标最外圈的圆
ax.grid(False) # 不显示默认的分割线
ax.set_yticks([]) # 不显示坐标间隔
plt.show()
if __name__ == '__main__':
# data_change()
plot_radar()