【终极版】大数据环境搭建汇编 cent os 7(权限问题详解)
大数据环境搭建汇编
网络静态IP设定
命令行键入命令:
![]()
确定该系统的静态IP,需要设置的参数如下:
Bootproto参数为static
Ip地址 子网掩码 网关 dns服务器
Onboo参数为yes,如下图

编辑结束,重启机器或者运行:service network start使得配置生效
配置/etc/hosts使得master和slaves之间能够用名字访问
1.配置master的hosts
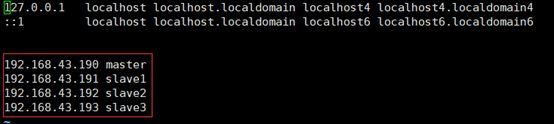
2.把hosts文件传送给其他主机
![]()
配置master无密码访问其他slaves主机
原理:把master生成的公钥发送给其他slaves主机即可
- 命令:ssh-keygen -t rsa //生成公钥
- 命令:cd ~/.ssh //进入ssh目录
- 命令:rm -f authorized_keys
- 命令:cat id_rsa.pub>>authorized_keys
- 命令:ssh-copy-id slaves
在hadoop用户下配置ssh免密码登录
如果不检查权限会导致在hadoop用户下启动集群ssh免密码登录失效
- 给hadoop用户赋予 sudo 执行权限
切换到root用户修改文件 vi /etc/sudoers
添加 hadoop ALL=(root) NOPASSWD:ALL
- 进入hadoop用户下~/.ssh文件夹运行 ssh-keygen –t rsa
生成公钥 cat id_rsa.pub>>authorized_keys
- 检查父子文件权限 ssh不允许home和~/.ssh文件group写入权限
chmod g-w /home/hadoop
chmod 700 /home/hadoop/.ssh
chmod 600 /home/hadoop/.ssh/authorized_keys
- 分发公钥到子节点上
ssh-copy-id hadoop@slave1
配置jdk环境
Master上主机的jdk环境配置
- 拷贝jdk压缩文件到相应目录(比如/home)
- 解压jdk压缩文件:tar -zxvf jdk压缩文件
- 把jdk压缩之后的目录改名:
-

-
- 修改jdk运行环境:vi /etc/profile
- 编辑好之后运行:source /etc/profile

配置slaves的jdk环境
- Scp jdk目录到slaves;scp /etc/profile到slaves
- 在slaves端运行命令:source /etc/profile
测试所有的master,slaves jdk是否安装成功命令:java
配置hadoop环境
Master主机配置
- 拷贝hadoop压缩文件到/home
- 解压hadoop压缩文件
- 更名hadoop文件夹:
- 编辑/etc/profile,添加hadoop的环境
- 运行命令:source /etc/profile
- 把文件/etc/profile ;目录/home/hadoop发送给slaves
- 在slaves上分别运行source /etc/profile

Hadoop的几个配置文件的设置
几个配置文件分别是:hadoop-env.sh、core-site.xml、hdfs-site,yarn-site。xml、mapred-site.xml
-
- 配置hadoop-env.sh,此文件只需要配置jdk的环境目录就可以
- 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/tmpvalue>
property>
configuration>
-
- 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>/home/hadoop/tmp/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/home/hadoop/tmp/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:50090value>
property>
configuration>
-
- 配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
-
- 配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
-
- 制定salves文件中的所有的slaves主机
slave1
slave2
slave3
运行hadoop
配置完master上的几个hadoop配置文件之后,把配置文件目录传送到slaves;
- 第一次运行hadoop前,运行命令:hadoop namenode -format
- 运行hadoop的启动命令:start-all.sh
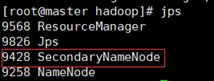
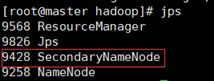
- 在master上运行jps,出现以下进行项,表示运行成功(红色框住的是可以配置的非必须进程)
- 在slaves上运行jps会得到如下进程项,表示运行成功。
Hdfs文件系统的操作命令(该命令必须要关闭所有主机的防火墙)
- 查看根目录下文件及文件夹:hadoop fs -ls /
- 在根文件夹下创建子文件夹:hadoop fs -mkdir /tmp
- 删除根文件夹下子文件夹tmp:hadoop fs -rmr /tmp
- 上传文件到hdfs的tmp目录下:hadoop fs -put 文件 /tmp
创建一个hadoop临时项目
- 配置pom.xml
- Map函数的代码
Pass
HIVE安装配置
Master主机上配置Hive
- 解压jdk压缩文件:tar -zxvf hive压缩文件
- 修改文件夹名为hive
- 修改文件权限 sudo chown –R hadoop:hadoop hive
配置环境变量
- vi ~/.bashrc
- export HIVE_HOME=/usr/local/hive
- export PATH=$PATH:$HIVE_HOME/bin
- source ~/.bashrc
修改配置文件
- 修改hive/conf下的hive-default.xml.template文件重命名为hive-default.xml
- 新建一个文件hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://(mysql的ip地址):3306/hive? Create
DatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriveNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>rootvalue>
property>
configuration>
MySQL JDBC驱动
- 解压jdbc包文件
- 将驱动包复制到hive/lib目录下
cp mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib
- 启动mysql服务service mysql start
- 配置MySQL允许Hive接入
mysql>grant all privileges on *.* to root@master identified by ‘root’;
(将mysql数据库所有表的所有权限赋给root用户 root用户和后面的root是在配置文件hive-site.xml中事先设置的连接密码)
mysql>flush privileges; (刷新权限)
启动 HIVE
- 启动hadoop:start-all.sh
- 启动hive:$hive
若是启动失败
- Cd /usr/local/hive/lib 找到jline-2.12.jar 文件,复制。
- Cd /usr/local/hadoop/share/hadoop/yarn/lib/
- 替换hadoop中的jline包
Spark安装配置
Spark安装
- 解压jdk压缩文件:tar -zxvf spark压缩文件
- 修改文件夹名为spark
- 修改权限:sudo chown –R hadoop:hadoop spark (hadoop是当前linux系统的用户名)
配置相关文件
- $cd /usr/local/spark
- $cp ./conf/spark-env.sh.template ./conf/spark-env.sh
- $vi spark-env.sh
- 在第一行添加(配置了就可以把数据存储到hdfs中,也可以从hdfs读取数据)
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
测试
- cd /usr/local/spark
- bin/run-example SparkPi 2>&1 | grep "Pi is roughly"
Spark集群安装
配置环境变量
- $vi ~/.bahrc
- $export SPARK_HOME=/usr/local/spark
- $export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
- $source ~/.bashrc
Spark的配置
- 配置slaves文件
$cd /usr/local/spark
$cp ./conf/slaves.template ./conf/slaves
替换默认的localhost为Slave1 Slave2
- 配置spark-env.sh
$cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MATER_IP=xxx.xxx.xxx.xxx
- 配置Slave节点
$scp –r /usr/local/spark root@slave1:/usr/local/
$scp –r /usr/local/spark root@slave2:/usr/local/
$sudo chown –R hadoop usr/local/spark
启动Spark集群
- 启动hadoop集群 start-all.sh
- 启动Master节点$cd /usr/local/spark/
$sbin/start-master.sh
- 启动所有Slave节点
$sbin/start-slaves.sh
- 查看集群信息
访问http://master:8080
Flume配置与测试
- 将flume安装包解压到/home/hadoop/local/目录下
- 配置环境变量
export FLUME_HOME=/home/hadoop/local/flume
export PATH=$FLUME_HOME/bin:$PATH
- 使用mv命令将conf目录下flume-env.sh.template文件修改为flume-env.sh
- 将jdk安装路径添加到flume-env.sh中
export JAVA_HOME=/usr/local/jdk
- 新建一个conf文件用来描述一个agent demoagent.conf文件内容如下
#命名此代理上的组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=55555
a1.sources.r1.max-line-length=1000000
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://Initial_Data/%Y%m%d
a1.sinks.k1.hdfs.filePrefix=%Y%m%d-
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.rollSize=1048576
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.channel=c1
连接好后通过flume-ng 命令启动flume组件
flume-ng agent -n a1 -c conf -p 55555 -f /home/hadoop/local/flume/conf/demoagent.conf -Dflume.hadoop.logger=INFO,console
windows 上面cmd命令行用 telnet 主机ip地址 +端口号也可以连接 并且cmd是作为客户端(作为55555端口存在)存在

- 运行flume验证程序
import time
import socket
import datetime
class Flume_test(object):
def __init__(self):
self.flume_host ='192.168.31.190'
self.flume_port = 55555
def gen_conn(self):
tcp_cli = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
return tcp_cli
def gen_data(self):
return 'Flume test ,datetime:[%s]\n'%datetime.datetime.now()
def main(self):
cli = self.gen_conn()
cli.connect((self.flume_host,self.flume_port))
while 1:
data = self.gen_data()
print(data)
cli.sendall(bytes(data, encoding="utf8"))
recv = cli.recv(1024)
print(recv)
time.sleep(1)
if __name__ == '__main__':
ft = Flume_test()
ft.main()
zookeeper集群安装配置
1操作4台电脑都要做
- 解压zookeeper安装包 设置环境变量 vi /etc/profile
export ZOOKEEPER_HOME=/home/hadoop/local/zookeeper
export PATH= $ZOOKEEPER_HOME/bin:$PATH
- Zookeeper根目录下创建data文件 进入conf 修改zoo.cfg文件
dataDir=/home/hadoop/local/zookeeper/data
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
server.4=slave3:2888:3888
通过scp将/etc/profile文件传入 此时要使用root用户登录对方
这样会有一个权限问题 这样解决给当前hadoop用户赋予读写执行权限
sudo chmod u+rwx /home/hadoop/local/zookeeper
通过scp将zookeeper安装包传入 此时hadoop用户登录即可
- 确定集群之间的关系创建好的data目录下创建myid文件当中填入对应server编号数字
sudo echo "1" >myid 剩下三个集群分别做对应配置
- 启动zookeeper集群 以及 关闭防火墙
firewall-cmd –state
systemctl stop firewalld.service
zkServer.sh start
{start|start-foreground|stop|restart|status|upgrade|print-cmd}
zkServer.sh status 查看关系
这一步报错请检查
第一,zoo.cfg文件配置出错:dataLogDir指定的目录未被创建。
第二,myid文件中的整数格式不对,或者与zoo.cfg中的server整数不对应
第三,防火墙未关闭;(我当时遇到的)
第四,端口被占用;
第五,zoo.cfg文件中主机名出错;
第六,hosts文件中,本机的主机名有两个对应,只需保留主机名和ip地址的映射