大数据环境搭建
大数据环境搭建
- linux环境
-
- 安装VM虚拟机
- centos创建用户并赋予权限
- ssh免密登录配置
- 编写集群分发脚本xsync
- 安装jdk
- 集群所有进程查看脚本
- hadoop环境
-
- 配置Hadoop集群
-
- Hadoop环境
- hadoop集群节点
- 核心配置文件 core-site.xml
- 配置hdfs-site.xml
- 配置yarn-site.xml
- MapReduce配置文件 mapred-site.xml
- 配置workers
- 配置历史服务器mapred-site.xml
- 配置日志的聚集 yarn-site.xml
- 手动启动hadoop集群
- hadoop群起脚本
- 支持LZO压缩配置
- Zookeeper安装
-
- zk集群安装
- 安装mysql
- sqoop部署和使用
- 部署hive
-
- Hive安装部署
- Hive元数据配置到MySQL
- 启动Hive
- 启动metastore,启动hiveserver2支持远程连接
- hbase安装部署
- 部署kylin
- Hive on Spark配置
- 部署presto
- 部署海豚调度系统
-
- 集群规划
- 前置准备工作
- 部署DolphinScheduler集群模式
- 搭建ELK日志采集与分析系统
-
- elasticsearch 7.17.14 linux安装部署
- kibana 安装部署
- elasticsearch-head
- 部署kafka集群
- 部署Logstash
- 部署Filebeat
- 测试配置是否正确
- 桥接模式、nat模式,这2种都可以,了解下底层原理
- HDFS存储多目录、集群数据均衡、磁盘间数据均衡
linux环境
安装VM虚拟机
-
VM软件、centos系统下载
VM15:链接: https://pan.baidu.com/s/1vc9RTEmqJlKUvrT-IUysag?pwd=x3hu 提取码: x3hu
centos7.9:链接: https://pan.baidu.com/s/1nXDzOA-0801YA6KiNq7IhQ?pwd=tvtf 提取码: tvtf -
创建3个VM虚拟机
一直默认即可 -
网络配置:相关参数修改
默认不改static和ip,网络是通的,改下面配置为了固定ip
vm选择桥接模式,则宿主机和虚拟机网段会一致。选择nat模式,宿主机和虚拟机网段会不一致,虽然宿主机能ping通虚拟机,但是局域网内其他电脑不能,可能需要做其他配置才行。
修改静态ip,cd到/etc/sysconfig/network-scripts,修改ifcfg-ens33
#修改为静态
BOOTPROTO="static"
#增加配置,该ip需要和宿主机的网段保持一致
#宿主机用ipconfig命令查看以太网适配器 VMware Network Adapter VMnet8:
IPADDR=192.168.xxx.200
NETMASK=255.255.255.0
#xxx和IPADDR中保持一致,最后一位改成2,和VM8的.1区分一下
GATEWAY=192.168.xxx.2
DNS1=8.8.8.8
--修改主机名称为:hadoop200
vim /etc/hostname
--改完后重启网关,重启完以后,ip和hostname才会改变
service network restart
--hostname命令查看
相关报错
“ifcfg-ens33” E212: Can’t open file for writing:需要用root账户修改
nat模式,虚拟机无法ping通宿主机和百度:
IPADDR:xxx和VMnet8保持一致
GATEWAY:最后一位VMnet8不能一样
4.自动化
VM设置开机启动虚拟机
centos取消屏幕保护:
进入centos系统,Applications→System Tools→Settings→Power→Black screen→Never
时区设置:
查看系统当前时区:timedatectl
查看系统所有时区:timedatectl list-timezones
设置系统时区:timedatectl set-timezone Asia/Shanghai
centos创建用户并赋予权限
--查看并关闭防火墙
systemctl status firewalld.service
systemctl stop firewalld.service
--永久关闭防火墙
systemctl disable firewalld.service
--创建hadoop用户
useradd hadoop
--给hadoop用户设置密码(密码为jrzf@666)
passwd hadoop
--给hadoop用户配置root权限,方便后期加sudo执行root权限命令
--vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows members of the 'sys' group to run networking, software,
## service management apps and more.
# %sys ALL = NETWORKING, SOFTWARE, SERVICES, STORAGE, DELEGATING,
PROCESSES, LOCATE, DRIVERS
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
hadoop ALL=(ALL) NOPASSWD:ALL
--ps: hadoop ALL=(ALL) NOPASSWD:ALL这行语句不能直接放在root下面,
因为所有用户都属于wheel组,
因为给hadoop设置了免密功能,如果放wheel上面,执行到wheel时,又需要密码了
--在/home目录下创建文件夹,并修改所属主和所属组
[root@localhost home]# mkdir /home/module
[root@localhost home]# mkdir /home/software
--修改module、software文件夹的所有者和所属组为hadoop用户
[root@localhost home]# chown -R hadoop:hadoop /home/module/
[root@localhost home]# chown -R hadoop:hadoop /home/software/
--【hadoop:hadoop,表示所有者:所属组】, ll命令查看效果
给所有子目录修改:chown -R hadoop:hadoop hive/
ssh免密登录配置
很重要:切换到hadoop用户
--切换到hadoop用户
--先用密码登录,记得切换到hadoop用户,很重要
1. 切换到hadoop用户,su hadoop
2:cd /home/hadoop/,ls -al 查看.ssh的隐藏目录,此时没有
3:ssh hadoop201报错,需配置sudo vim /etc/hosts
ssh: Could not resolve hostname hadoop201: Name or service not known
192.168.176.200 hadoop200
192.168.176.201 hadoop201
192.168.176.202 hadoop202
--在三台机器上配置完成后,就可以用ssh hadoop200,通过密码登录了,此时有.ssh的隐藏目录
--SSH无密码登录配置
4. 生成id_rsa(私钥)、id_rsa.pub(公钥)
ssh-keygen -t rsa,三个回车即可
5. 将公钥拷贝到要免密登录的目标机器上,需要输入密码
ssh-copy-id hadoop200
ssh-copy-id hadoop201
ssh-copy-id hadoop202
注意:
还需要在hadoop201上采用hadoop账号配置一下无密登录到hadoop200、hadoop201、hadoop202服务器上。
还需要在hadoop202上采用hadoop账号配置一下无密登录到hadoop200、hadoop201、hadoop202服务器上。
还需要在hadoop200上采用root账号,配置一下无密登录到hadoop200、hadoop201、hadoop202;
【root要配置的原因:比如使用sudo ./bin/xsync /etc/profile.d/my_env.sh 同步环境配置文件时用到 】
known_hosts记录ssh访问过计算机的公钥(public key)
id_rsa生成的私钥
id_rsa.pub生成的公钥
authorized_keys存放授权过的无密登录服务器公钥
6.exit可以退出ssh登录的服务器
编写集群分发脚本xsync
--切换到hadoop用户
1.循环复制文件到所有节点的相同目录下
2.xsync要同步的文件名称,期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
3.脚本实现
--具体步骤
切换到hadoop用户
cd /home/hadoop
mkdir bin
cd bin
vim xsync
--脚本内容,只需要改hadoop200 hadoop201 hadoop202即可
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop200 hadoop201 hadoop202
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
--修改脚本 xsync 具有执行权限
chmod +x xsync
--测试脚本
xsync /home/hadoop/bin/
--将脚本复制到/bin中,以便全局调用,不再需要cd到bin目录
[hadoop@hadoop201 ~]$ sudo cp xsync /bin/
--举例,修改jdk环境变量后,同步到三台服务器
sudo ./bin/xsync /etc/profile.d/my_env.sh
注意:如果用了sudo,那么xsync一定要给它的路径补全,因为切换到root,原来的cd后的目录位置会变
--让环境变量生效,每台服务器都需要刷新
source /etc/profile
安装jdk
--查看是否存在jdk
rpm -qa |grep jdk
--卸载系统自带的jdk
rpm -e --nodeps copy-jdk-configs-1.2-1.el7.noarch
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
--卸载后,输入java,会提示-bash: /usr/bin/java: 没有那个文件或目录
--在hadoop200上安装jdk
1.安装JDK前,一定确保提前删除了虚拟机自带的JDK
2.用XShell传输工具将JDK导入到home目录下面的software文件夹下面
3.解压JDK到/home/module目录下
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /home/module/
4.配置JDK环境变量
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/home/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
5.让环境变量生效
source /etc/profile.d/my_env.sh
6.测试
java -version
7.分发jdk
xsync /home/module/jdk1.8.0_212/
8.分发环境变量配置文件
sudo /home/hadoop/bin/xsync /etc/profile.d/my_env.sh
9.分别登录到3台服务器,执行source,使配置生效
source /etc/profile.d/my_env.sh
--环境变量配置说明
Linux的环境变量可在多个文件中配置,如/etc/profile,
/etc/profile.d/*.sh,~/.bashrc,~/.bash_profile等,下面说明上述几个文件之间的关系和区别
bash的运行模式可分为login shell和non-login shell
我们通过终端,输入用户名、密码,登录系统之后,得到就是一个login shell。
而当我们执行以下命令ssh hadoop103 command,
在hadoop103执行command的就是一个non-login shell
不管是login shell还是non-login shell,启动时都会加载/etc/profile.d/*.sh中的环境变量
集群所有进程查看脚本
1.cd /home/hadoop/bin
vim xcall.sh
--2.脚本
#! /bin/bash
for i in hadoop200 hadoop201 hadoop202
do
echo --------- $i ----------
ssh $i "$*"
done
3.修改脚本执行权限
chmod 777 xcall.sh
4.执行脚本
[hadoop@hadoop200 bin]$ ./xcall.sh jps
hadoop环境
配置Hadoop集群
Hadoop环境
1.用XShell文件传输工具将hadoop-3.1.3.tar.gz导入到/home目录下面的software文件夹下面
2.解压安装文件到/home/module下面(其他2台服务器分发一下)
tar -zxvf hadoop-3.1.3.tar.gz -C /home/module/
3.将Hadoop添加到环境变量: 在my_env.sh文件末尾添加如下内容:(shift+g)
--sudo vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/home/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
4.分发环境变量配置文件 sudo /home/hadoop/bin/xsync /etc/profile.d/my_env.sh
5.分别登录到3台服务器,执行source,使配置生效 source /etc/profile.d/my_env.sh
6.测试是否安装成功: hadoop version
--Hadoop目录结构
(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
hadoop集群节点
| hadoop200 | hadoop201 | hadoop202 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | DataNode、SecondaryNameNode |
| Yarn | NodeManager | Resourcemanager、NodeManager | NodeManager |
核心配置文件 core-site.xml
1.核心配置文件 core-site.xml
[hadoop@hadoop200 /]$ cd /home/module/hadoop-3.1.3/etc/hadoop/
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop200:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<!-- 配置该hadoop(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<!-- 配置该hadoop(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<!-- 配置该hadoop(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.hadoop.users</name>
<value>*</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop200:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop202:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop201</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>20480</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
MapReduce配置文件 mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置workers
--不能有空格,不能有空行 vim workers
hadoop200
hadoop201
hadoop202
配置历史服务器mapred-site.xml
-- vim mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop200:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop200:19888</value>
</property>
配置日志的聚集 yarn-site.xml
-- 配置日志的聚集 vim yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop200:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
手动启动hadoop集群
1.分发上面改过的5个配置文件
/home/hadoop/bin/xsync /home/module/hadoop-3.1.3/etc/hadoop/core-site.xml
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
workers
2. 如果集群是第一次启动,需要在hadoop200节点格式化NameNode
3. (注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[hadoop@hadoop200 bin]$ ./hdfs namenode -format
3.启动HDFS,在hadoop200机器上
[hadoop@hadoop200 hadoop-3.1.3]$ ./sbin/start-dfs.sh
4.查看启动情况
[hadoop@hadoop200 hadoop-3.1.3]$ /home/hadoop/bin/xcall.sh jps
--------- hadoop200 ----------
16608 NameNode
17377 DataNode
17690 Jps
--------- hadoop201 ----------
9089 DataNode
9174 Jps
--------- hadoop202 ----------
10118 Jps
9959 DataNode
9727 SecondaryNameNode
5.在配置了ResourceManager的节点(hadoop201)启动YARN
[hadoop@hadoop201 hadoop-3.1.3]$ ./sbin/start-yarn.sh
[hadoop@hadoop200 hadoop-3.1.3]$ /home/hadoop/bin/xcall.sh jps
--------- hadoop200 ----------
16608 NameNode
17377 DataNode
18009 Jps
17851 NodeManager
--------- hadoop201 ----------
9488 NodeManager
9089 DataNode
9361 ResourceManager
9857 Jps
--------- hadoop202 ----------
9959 DataNode
10395 Jps
10269 NodeManager
9727 SecondaryNameNode
6.Web端查看HDFS的Web页面:
http://hadoop200:9870/
http://192.168.xxx.200:9870/
如果无法访问,可能是防火墙没关
hadoop群起脚本
--hadoop群起脚本
1. cd /home/hadoop/bin
2. vim hadoop.sh
3. 脚本内容
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop200 "/home/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop201 "/home/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop200 "/home/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop200 "/home/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop201 "/home/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop200 "/home/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
4. 脚本赋予权限
[hadoop@hadoop200 bin]$ chmod 777 hadoop.sh
5. 测试
启动集群
[hadoop@hadoop200 bin]$ ./hadoop.sh start
关闭集群
[hadoop@hadoop200 bin]$ ./hadoop.sh stop
支持LZO压缩配置
1.hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译
2.将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-3.1.3/share/hadoop/common/
[hadoop@hadoop200 bin]$ cd /home/module/hadoop-3.1.3/share/hadoop/common/
3.同步hadoop-lzo-0.4.20.jar到hadoop103、hadoop104
[hadoop@hadoop200 common]$ xsync hadoop-lzo-0.4.20.jar
4.core-site.xml增加配置支持LZO压缩
[hadoop@hadoop200 hadoop]$ vim core-site.xml
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
5. 同步core-site.xml到hadoop201、hadoop202
[hadoop@hadoop200 hadoop]$ xsync core-site.xml
6.重启hadoop
7.测试-数据准备
[hadoop@hadoop200 bin]$ cd /home/module/hadoop-3.1.3/
[hadoop@hadoop200 hadoop-3.1.3]$ hadoop fs -mkdir /input
[hadoop@hadoop200 hadoop-3.1.3]$ hadoop fs -put README.txt /input
2022-10-29 17:39:00,705 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
8.测试-压缩
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output
9.项目经验之LZO创建索引
Zookeeper安装
zk集群安装
1. 解压Zookeeper安装包到/home/module/目录下
[hadoop@hadoop200 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /home/module/
2.修改/home/module/apache-zookeeper-3.5.7-bin名称为zookeeper-3.5.7
[hadoop@hadoop200 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
3.配置服务器编号
1)在/home/module/zookeeper-3.5.7/这个目录下创建zkData
[hadoop@hadoop200 zookeeper-3.5.7]$ mkdir zkData
2)在/home/module/zookeeper-3.5.7/zkData目录下创建一个myid的文件
--添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
[hadoop@hadoop200 zkData]$ vim myid
3)拷贝配置好的zookeeper到其他机器上,并分别在hadoop201、hadoop202上修改myid文件中内容为2、3
[hadoop@hadoop200 zkData]$ xsync myid
4.配置zoo.cfg文件
1)重命名/home/module/zookeeper-3.5.7/conf这个目录下的zoo_sample.cfg为zoo.cfg
[hadoop@hadoop200 conf]$ mv zoo_sample.cfg zoo.cfg
2)[hadoop@hadoop200 conf]$ vim zoo.cfg
--修改数据存储路径配置
dataDir=/home/module/zookeeper-3.5.7/zkData
--增加如下配置
#######################cluster##########################
server.1=hadoop200:2888:3888
server.2=hadoop201:2888:3888
server.3=hadoop202:2888:3888
3)同步zoo.cfg配置文件
[hadoop@hadoop200 conf]$ xsync zoo.cfg
4)启动zk,查看zk状态
[hadoop@hadoop200 zookeeper-3.5.7]$ ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@hadoop200 zookeeper-3.5.7]$ ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
5)zk集群启动脚本
[hadoop@hadoop200 zookeeper-3.5.7]$ cd /home/hadoop/bin/
[hadoop@hadoop200 bin]$ vim zk.sh
--集群脚本如下
#!/bin/bash
case $1 in
"start"){
for i in hadoop200 hadoop201 hadoop202
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/home/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop200 hadoop201 hadoop202
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/home/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop200 hadoop201 hadoop202
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/home/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac
--增加脚本执行权限
[hadoop@hadoop200 bin]$ chmod u+x zk.sh
--Zookeeper集群启动/停止脚本
[hadoop@hadoop200 bin]$ zk.sh status
[hadoop@hadoop200 bin]$ zk.sh stop
[hadoop@hadoop200 bin]$ zk.sh start
安装mysql
1.将安装包和JDBC驱动上传到/home/software,共计6个
01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
mysql-connector-java-5.1.27-bin.jar
2.卸载自带的Mysql-libs(如果之前安装过MySQL,要全都卸载掉)
[root@hadoop200 mysql]# rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
3.安装mysql
1)安装MySQL依赖
[root@hadoop200 mysql]# sudo rpm -ivh 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
警告:01_mysql-community-common-5.7.16-1.el7.x86_64.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:mysql-community-common-5.7.16-1.e################################# [100%]
[root@hadoop200 mysql]# sudo rpm -ivh 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
警告:02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:mysql-community-libs-5.7.16-1.el7################################# [100%]
[root@hadoop200 mysql]# sudo rpm -ivh 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
警告:03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:mysql-community-libs-compat-5.7.1################################# [100%]
2)安装mysql-client
[root@hadoop200 mysql]# sudo rpm -ivh 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
警告:04_mysql-community-client-5.7.16-1.el7.x86_64.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:mysql-community-client-5.7.16-1.e################################# [100%]
3)安装mysql-server
[root@hadoop200 mysql]# sudo rpm -ivh 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
警告:05_mysql-community-server-5.7.16-1.el7.x86_64.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:mysql-community-server-5.7.16-1.e################################# [100%]
4)启动mysql
[root@hadoop200 mysql]# sudo systemctl start mysqld
5)查看mysql密码
[root@hadoop200 mysql]# sudo cat /var/log/mysqld.log | grep password
2022-10-29T10:37:32.647921Z 1 [Note] A temporary password is generated for root@localhost: sh82uFfQL!)5
6)配置mysql
[root@hadoop200 mysql]# mysql -uroot -p'sh82uFfQL!)5'
7)设置复杂密码(由于MySQL密码策略,此密码必须足够复杂)
mysql> set password=password("Qs23=zs32");
8)更改MySQL密码策略
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
9)设置简单好记的密码
set password=password("jrzf@666");
10)进入MySQL库
mysql> use mysql
11)查询user表
mysql> select user, host from user;
+-----------+-----------+
| user | host |
+-----------+-----------+
| mysql.sys | localhost |
| root | localhost |
+-----------+-----------+
2 rows in set (0.00 sec)
12)修改user表,把Host表内容修改为%,支持远程登录
mysql> update user set host="%" where user="root";
13)刷新
mysql> flush privileges;
14)退出
mysql> quit;
sqoop部署和使用
1.上传安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz到hadoop200的/home/software路径中
2.解压sqoop安装包到指定目录
[root@hadoop200 software]# tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /home/module/
3.改名字
[root@hadoop200 module]# mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
4)修改配置文件
--进入到/home/module/sqoop/conf目录,重命名配置文件
[root@hadoop200 conf]# mv sqoop-env-template.sh sqoop-env.sh
--修改配置文件vim sqoop-env.sh
[root@hadoop200 conf]# vim sqoop-env.sh
export HADOOP_COMMON_HOME=/home/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/home/module/hadoop-3.1.3
export HIVE_HOME=/home/module/hive
export ZOOKEEPER_HOME=/home/module/zookeeper-3.5.7
export ZOOCFGDIR=/home/module/zookeeper-3.5.7/conf
5)拷贝JDBC驱动
将mysql-connector-java-5.1.48.jar 上传到/home/software路径
进入到/home/software/路径,拷贝jdbc驱动到sqoop的lib目录下
[root@hadoop200 mysql]# cp mysql-connector-java-5.1.27-bin.jar /home/module/sqoop/lib/
6)验证Sqoop
[root@hadoop200 sqoop]# bin/sqoop help
7)测试Sqoop是否能够成功连接数据库
[root@hadoop200 sqoop]# bin/sqoop list-databases --connect jdbc:mysql://hadoop200:3306/ --username root --password 123456
8)分发sqoop到其他服务器
部署hive
Hive安装部署
1.把apache-hive-3.1.2-bin.tar.gz上传到Linux的/home/software目录下
2.解压apache-hive-3.1.2-bin.tar.gz到/home/module/目录下面
[root@hadoop200 software]# tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /home/module/
3.修改apache-hive-3.1.2-bin.tar.gz的名称为hive
[root@hadoop200 module]# mv /home/module/apache-hive-3.1.2-bin/ /home/module/hive
4.修改/etc/profile.d/my_env.sh,添加环境变量
[hadoop@hadoop200 module]$ sudo vim /etc/profile.d/my_env.sh
#HIVE_HOME
export HIVE_HOME=/home/module/hive
export PATH=$PATH:$HIVE_HOME/bin
--刷新,使环境变量生效
[hadoop@hadoop200 module]$ source /etc/profile.d/my_env.sh
5.解决日志Jar包冲突,进入/home/module/hive/lib目录
[hadoop@hadoop200 lib]$ sudo mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
Hive元数据配置到MySQL
1.将MySQL的JDBC驱动拷贝到Hive的lib目录下
[hadoop@hadoop200 mysql]$ sudo cp mysql-connector-java-5.1.27-bin.jar /home/module/hive/lib/
2.配置Metastore到MySQL
--在$HIVE_HOME/conf目录下新建hive-site.xml文件
--配置文件[hadoop@hadoop200 conf]$ sudo vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop200:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop200</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
hive不需要分发
启动Hive
1.初始化元数据库
--登陆MySQL
[hadoop@hadoop200 conf]$ mysql -uroot -p'123456'
--新建Hive元数据库
mysql> create database metastore;
Query OK, 1 row affected (0.00 sec)
mysql> quit;
--初始化Hive元数据库
--特别注意,要su root ,才能执行成功,用hadoop用户执行会报错:org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
--改权限[hadoop@hadoop200 lib]$ sudo chown hadoop:hadoop mysql-connector-java-5.1.27-bin.jar
[root@hadoop200 conf]# schematool -initSchema -dbType mysql -verbose
--报错的原因,先用root执行了schematool,又用hadoop账号执行了一次
[hadoop@hadoop200 conf]# schematool -initSchema -dbType mysql -verbose
--解决办法,在mysql中删除metastore库,用hadoop账号重新走一遍流程
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!
Underlying cause: java.io.IOException : Schema script failed, errorcode 2
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:594)
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:567)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1517)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:318)
at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
Caused by: java.io.IOException: Schema script failed, errorcode 2
at org.apache.hive.beeline.HiveSchemaTool.runBeeLine(HiveSchemaTool.java:1226)
at org.apache.hive.beeline.HiveSchemaTool.runBeeLine(HiveSchemaTool.java:1204)
at org.apache.hive.beeline.HiveSchemaTool.doInit(HiveSchemaTool.java:590)
2.启动Hive客户端
[hadoop@hadoop200 bin]$ ./hive
--用root账号会报错:
Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=EXECUTE, inode="/tmp":hadoop:supergroup:drwxrwx---
3)查看一下数据库
hive (default)> show databases;
OK
database_name
default
Time taken: 0.499 seconds, Fetched: 1 row(s)
启动metastore,启动hiveserver2支持远程连接
========hive==========在hadoop200服务器
登录hadoop200服务器,cd到/home/module/hive/bin,使用hadoop账号
1. 启动metastore
nohup hive --service metastore 2>&1 &
停止:netstat -lnp|grep 9083
ps -ef |grep -i metastore
2.启动hiveserver2
nohup hive --service hiveserver2 2>&1 &
ps -ef |grep -i hiveserver2
HiveServer2 web访问地址
http://192.168.xxx.200:10002/
3.启动beeline客户端
/home/module/hive/bin/beeline -u jdbc:hive2://hadoop200:10000/jrxfdb -n hadoop
可以使用命令
4.启动 hive
/home/module/hive/bin/hive
停止:ps -aux|grep hive
5.hive的webui只支持到2.3的版本,可以使用squirrel-sql-3.9.1可视化工具连接查看,但很卡
hbase安装部署
1.首先保证Zookeeper集群的正常部署,并启动之
2.Hadoop集群的正常部署并启动
3.HBase解压
[hadoop@hadoop200 software]$ tar -zxvf hbase-2.0.5-bin.tar.gz -C /home/module/
配置环境变量
3.将Hbase添加到环境变量: 在my_env.sh文件末尾添加如下内容:(shift+g)
--sudo vim /etc/profile.d/my_env.sh
#HBASE_HOME
export HBASE_HOME=/home/module/hbase-2.0.5
export PATH=$PATH:$HBASE_HOME/bin
4.分发环境变量配置文件 sudo /home/hadoop/bin/xsync /etc/profile.d/my_env.sh
5.分别登录到3台服务器,执行source,使配置生效 source /etc/profile.d/my_env.sh
4.修改HBase对应的配置文件
1)hbase-env.sh修改内容
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/home/module/jdk1.8.0_212/
2)hbase-site.xml修改内容
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop200:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop200,hadoop201,hadoop202</value>
</property>
</configuration>
3)修改regionservers
hadoop200
hadoop201
hadoop202
5.软连接hadoop配置文件到HBase
[hadoop@hadoop200 conf]$ ln -s /home/module/hadoop-3.1.3/etc/hadoop/core-site.xml /home/module/hbase-2.0.5/conf/core-site.xml
[hadoop@hadoop200 conf]$ ln -s /home/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /home/module/hbase-2.0.5/conf/hdfs-site.xml
6.HBase远程发送到其他集群,需要分发,要不会报错
hadoop202: bash: /home/module/hbase-2.0.5/bin/hbase-daemon.sh: 没有那个文件或目录
[hadoop@hadoop200 conf]$ /home/hadoop/bin/xsync /home/module/hbase-2.0.5/
7.HBase服务的启动
[hadoop@hadoop200 bin]$ ./start-hbase.sh
[hadoop@hadoop200 bin]$ ./stop-hbase.sh
部署kylin
1.安装Kylin前需先部署好Hadoop、Hive、Zookeeper、HBase,SPARK,并且需要在/etc/profile中配置以下环境变量HADOOP_HOME,HIVE_HOME,HBASE_HOME,记得source使其生效
2.上传Kylin安装包apache-kylin-3.0.2-bin.tar.gz,并解压
tar -zxvf apache-kylin-3.0.2-bin.tar.gz -C /home/module/
mv apache-kylin-3.0.2-bin/ kylin
3.修改/home/module/kylin/bin/find-spark-dependency.sh,排除冲突的jar包
需要增加的内容:! -name '*jackson*' ! -name '*metastore*'
注意前后保留空格
4.启动
启动Kylin之前,需先启动Hadoop(hdfs,yarn,jobhistoryserver)、Zookeeper、Hbase,SPARK
[hadoop@hadoop200 bin]$ ./kylin.sh start
5.访问
jps:进程是RunJar
在http://hadoop102:7070/kylin查看Web页面
用户名为:ADMIN,密码为:KYLIN
Hive on Spark配置
启动kylin失败报错:spark not found, set SPARK_HOME, or run bin/download-spark.sh
1. 注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的.因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本
2.在Hive所在节点部署Spark
1)上传并解压解压spark-3.0.0-bin-hadoop3.2.tgz
[hadoop@hadoop200 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /home/module/
[hadoop@hadoop200 module]$ mv spark-3.0.0-bin-hadoop3.2 spark
2)配置SPARK_HOME环境变量
# SPARK_HOME
export SPARK_HOME=/home/module/spark
export PATH=$PATH:$SPARK_HOME/bin
sudo vim /etc/profile.d/my_env.sh
source /etc/profile.d/my_env.sh
3)在hive中创建spark配置文件
[hadoop@hadoop200 spark]$ vim /home/module/hive/conf/spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop200:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
4)在HDFS创建如下路径,用于存储历史日志
[hadoop@hadoop200 spark]$ hadoop fs -mkdir /spark-history
5)向HDFS上传Spark纯净版jar包
说明1:由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
#上传并解压spark-3.0.0-bin-without-hadoop.tgz
[hadoop@hadoop200 software]$ tar -zxvf spark-3.0.0-bin-without-hadoop.tgz
#上传Spark纯净版jar包到HDFS
[hadoop@hadoop200 software]$ hadoop fs -mkdir /spark-jars
[hadoop@hadoop200 software]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
6)修改hive-site.xml文件
[hadoop@hadoop200 conf]$ vim /home/module/hive/conf/hive-site.xml
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop200:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
7)Hive on Spark测试
1)启动hive客户端
[atguigu@hadoop102 hive]$ bin/hive
(2)创建一张测试表
hive (default)> create table student(id int, name string);
(3)通过insert测试效果
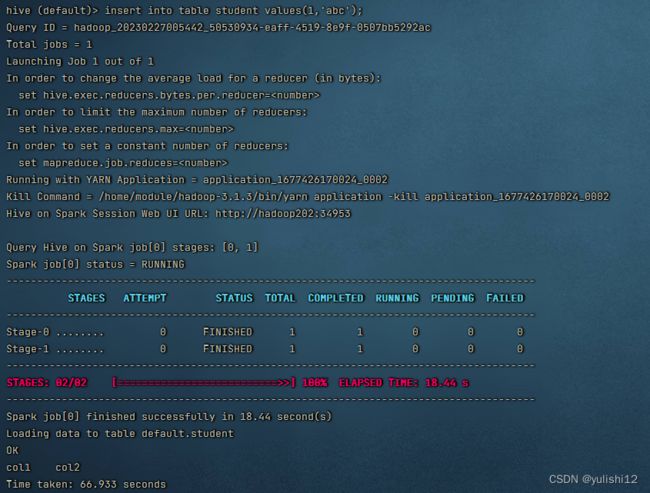
hive (default)> insert into table student values(1,'abc');
若结果如下,则说明配置成功
部署presto
部署海豚调度系统
集群规划
集群模式下,可配置多个Master及多个Worker。通常可配置2~3个Master,若干个Worker。由于集群资源有限,此处配置一个Master,三个Worker,集群规划如下
| 服务器 | 节点 |
|---|---|
| hadoop200 | master、worker |
| hadoop201 | worker |
| hadoop202 | worker |
前置准备工作
(1)三台节点均需部署JDK(1.8+),并配置相关环境变量。
(2)需部署数据库,支持MySQL(5.7+)或者PostgreSQL(8.2.15+)。如 MySQL 则需要 JDBC Driver 8.0.16。
(3)需部署Zookeeper(3.4.6+)。
(4)如果启用 HDFS 文件系统,则需要 Hadoop(2.6+)环境。
(5)三台节点均需安装进程管理工具包psmisc。
sudo yum install -y psmisc
部署DolphinScheduler集群模式
(1)上传DolphinScheduler安装包到hadoop102节点的/home/software目录
(2)解压安装包到当前目录:[hadoop@hadoop200 software]$ tar -zxvf apache-dolphinscheduler-2.0.5-bin
注:解压目录并非最终的安装目录
(3)配置一键部署脚本
修改解压目录下的conf/config目录下的install_config.conf文件
[hadoop@hadoop200 apache-dolphinscheduler-2.0.5-bin]$ vim ./conf/config/install_config.conf
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# A comma separated list of machine hostname or IP would be installed DolphinScheduler,
# including master, worker, api, alert. If you want to deploy in pseudo-distributed
# mode, just write a pseudo-distributed hostname
# Example for hostnames: ips="ds1,ds2,ds3,ds4,ds5", Example for IPs: ips="192.168.8.1,192.168.8.2,192.168.8.3,192.168.8.4,192.168.8.5"
ips="hadoop200,hadoop201,hadoop202"
# 将要部署任一 DolphinScheduler 服务的服务器主机名或 ip 列表
# Port of SSH protocol, default value is 22. For now we only support same port in all `ips` machine
# modify it if you use different ssh port
sshPort="22"
# A comma separated list of machine hostname or IP would be installed Master server, it
# must be a subset of configuration `ips`.
# Example for hostnames: masters="ds1,ds2", Example for IPs: masters="192.168.8.1,192.168.8.2"
masters="hadoop200"
# master 所在主机名列表,必须是 ips 的子集
# A comma separated list of machine : or :.All hostname or IP must be a
# subset of configuration `ips`, And workerGroup have default value as `default`, but we recommend you declare behind the hosts
# Example for hostnames: workers="ds1:default,ds2:default,ds3:default", Example for IPs: workers="192.168.8.1:default,192.168.8.2:default,192.168.8.3:default"
workers="hadoop200:default,hadoop201:default,hadoop202:default"
# worker主机名及队列,此处的 ip 必须在 ips 列表中
# A comma separated list of machine hostname or IP would be installed Alert server, it
# must be a subset of configuration `ips`.
# Example for hostname: alertServer="ds3", Example for IP: alertServer="192.168.8.3"
alertServer="hadoop200"
# 告警服务所在服务器主机名
# A comma separated list of machine hostname or IP would be installed API server, it
# must be a subset of configuration `ips`.
# Example for hostname: apiServers="ds1", Example for IP: apiServers="192.168.8.1"
apiServers="hadoop200"
# api服务所在服务器主机名
# A comma separated list of machine hostname or IP would be installed Python gateway server, it
# must be a subset of configuration `ips`.
# Example for hostname: pythonGatewayServers="ds1", Example for IP: pythonGatewayServers="192.168.8.1"
# pythonGatewayServers="ds1"
# 不需要的配置项,可以保留默认值,也可以用 # 注释
# The directory to install DolphinScheduler for all machine we config above. It will automatically be created by `install.sh` script if not exists.
# Do not set this configuration same as the current path (pwd)
installPath="/home/module/dolphinscheduler"
# DS 安装路径,如果不存在会创建
# The user to deploy DolphinScheduler for all machine we config above. For now user must create by yourself before running `install.sh`
# script. The user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled than the root directory needs
# to be created by this user
deployUser="hadoop"
# 部署用户,任务执行服务是以 sudo -u {linux-user} 切换不同 Linux 用户的方式来实现多租户运行作业,因此该用户必须有免密的 sudo 权限。
# The directory to store local data for all machine we config above. Make sure user `deployUser` have permissions to read and write this directory.
dataBasedirPath="/tmp/dolphinscheduler"
# 前文配置的所有节点的本地数据存储路径,需要确保部署用户拥有该目录的读写权限
# ---------------------------------------------------------
# DolphinScheduler ENV
# ---------------------------------------------------------
# JAVA_HOME, we recommend use same JAVA_HOME in all machine you going to install DolphinScheduler
# and this configuration only support one parameter so far.
javaHome="/home/module/jdk1.8.0_212"
# JAVA_HOME 路径
# DolphinScheduler API service port, also this is your DolphinScheduler UI component's URL port, default value is 12345
apiServerPort="12345"
# ---------------------------------------------------------
# Database
# NOTICE: If database value has special characters, such as `.*[]^${}\+?|()@#&`, Please add prefix `\` for escaping.
# ---------------------------------------------------------
# The type for the metadata database
# Supported values: ``postgresql``, ``mysql`, `h2``.
# 注意:数据库相关配置的 value 必须加引号,否则配置无法生效
DATABASE_TYPE="mysql"
# 数据库类型
# Spring datasource url, following :/? format, If you using mysql, you could use jdbc
# string jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8 as example
# SPRING_DATASOURCE_URL=${SPRING_DATASOURCE_URL:-"jdbc:h2:mem:dolphinscheduler;MODE=MySQL;DB_CLOSE_DELAY=-1;DATABASE_TO_LOWER=true"}
SPRING_DATASOURCE_URL="jdbc:mysql://hadoop200:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8"
# 数据库 URL
# Spring datasource username
# SPRING_DATASOURCE_USERNAME=${SPRING_DATASOURCE_USERNAME:-"sa"}
SPRING_DATASOURCE_USERNAME="dolphinscheduler"
# 数据库用户名
# Spring datasource password
# SPRING_DATASOURCE_PASSWORD=${SPRING_DATASOURCE_PASSWORD:-""}
SPRING_DATASOURCE_PASSWORD="dolphinscheduler"
# 数据库密码
# ---------------------------------------------------------
# Registry Server
# ---------------------------------------------------------
# Registry Server plugin name, should be a substring of `registryPluginDir`, DolphinScheduler use this for verifying configuration consistency
registryPluginName="zookeeper"
# 注册中心插件名称,DS 通过注册中心来确保集群配置的一致性
# Registry Server address.
registryServers="hadoop200:2181,hadoop201:2181,hadoop202:2181"
# 注册中心地址,即 Zookeeper 集群的地址
# Registry Namespace
registryNamespace="dolphinscheduler"
# DS 在 Zookeeper 的结点名称
# ---------------------------------------------------------
# Worker Task Server
# ---------------------------------------------------------
# Worker Task Server plugin dir. DolphinScheduler will find and load the worker task plugin jar package from this dir.
taskPluginDir="lib/plugin/task"
# resource storage type: HDFS, S3, NONE
resourceStorageType="HDFS"
# 资源存储类型
# resource store on HDFS/S3 path, resource file will store to this hdfs path, self configuration, please make sure the directory exists on hdfs and has read write permissions. "/dolphinscheduler" is recommended
resourceUploadPath="/dolphinscheduler"
# 资源上传路径
# if resourceStorageType is HDFS,defaultFS write namenode address,HA, you need to put core-site.xml and hdfs-site.xml in the conf directory.
# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,S3 be sure to create the root directory /dolphinscheduler
defaultFS="hdfs://hadoop200:8020"
# 默认文件系统
# if resourceStorageType is S3, the following three configuration is required, otherwise please ignore
s3Endpoint="http://192.168.xx.xx:9010"
s3AccessKey="xxxxxxxxxx"
s3SecretKey="xxxxxxxxxx"
# resourcemanager port, the default value is 8088 if not specified
resourceManagerHttpAddressPort="8088"
# yarn RM http 访问端口
# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single node, keep this value empty
yarnHaIps=
# Yarn RM 高可用 ip,若未启用 RM 高可用,则将该值置空
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single node, you only need to replace 'yarnIp1' to actual resourcemanager hostname
singleYarnIp="hadoop201"
# Yarn RM 主机名,若启用了 HA 或未启用 RM,保留默认值
# who has permission to create directory under HDFS/S3 root path
# Note: if kerberos is enabled, please config hdfsRootUser=
hdfsRootUser="hadoop"
# 拥有 HDFS 根目录操作权限的用户
# kerberos config
# whether kerberos starts, if kerberos starts, following four items need to config, otherwise please ignore
kerberosStartUp="false"
# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"
# keytab username,watch out the @ sign should followd by \\
keytabUserName="hdfs-mycluster\\@ESZ.COM"
# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"
# kerberos expire time, the unit is hour
kerberosExpireTime="2"
# use sudo or not
sudoEnable="true"
# worker tenant auto create
workerTenantAutoCreate="false"
4)初始化数据库
DolphinScheduler 元数据存储在关系型数据库中,故需创建相应的数据库和用户。
(1)创建数据库
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
(2)创建用户
mysql> CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
注:
若出现以下错误信息,表明新建用户的密码过于简单。
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
可提高密码复杂度或者执行以下命令降低MySQL密码强度级别。
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
(3)赋予用户相应权限
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
mysql> flush privileges;
(4)修改配置文件
[hadoop@hadoop200 conf]$ vim datasource.properties 这个是1.3.9版本
[hadoop@hadoop200 conf]$ vim application-mysql.yaml # mysql example 这个是2.0.5版本
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://hadoop200:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=dolphinscheduler
spring.datasource.password=dolphinscheduler
(5)拷贝驱动mysql-connector-java-5.1.27-bin.jar 到/opt/software/apache-dolphinscheduler-1.3.9-bin/lib
文档中用mysql-connector-java-8.0.16.jar是错误的
(6)执行数据库初始化脚本,会生成表
[hadoop@hadoop200 apache-dolphinscheduler-1.3.9-bin]$ ./script/create-dolphinscheduler.sh
(7)启动Zookeeper集群,一键部署并启动DolphinScheduler
[hadoop@hadoop200 apache-dolphinscheduler-2.0.3-bin]$ ./install.sh
(8)访问DolphinScheduler UI
DolphinScheduler UI地址为http://hadoop200:12345/dolphinscheduler
初始用户的用户名为:admin,密码为dolphinscheduler123
如果报登录失败,查看logs目录下的dolphinscheduler-api.log,修改配置文件中的数据库连接,重启服务
[hadoop@hadoop200 conf]$ pwd
/opt/module/dolphinscheduler/conf
[hadoop@hadoop200 conf]$ vim datasource.properties
(11)一键启停所有服务
./bin/start-all.sh
./bin/stop-all.sh
搭建ELK日志采集与分析系统
elasticsearch 7.17.14 linux安装部署
选择下载linux版本,elasticsearch-7.17.14-linux-x86_64.tar.gz
官网配置文件:https://www.elastic.co/guide/en/elasticsearch/reference/8.0/important-settings.html#cluster-name
jdk8支持的es最高版本为:7.17.14:https://www.elastic.co/cn/support/matrix#matrix_jvm
下载地址:https://www.elastic.co/cn/downloads/past-releases/#elasticsearch
# 集群部署准备工作
上传文件到/home/software目录
解压: tar -zxvf elasticsearch-7.17.14-linux-x86_64.tar.gz -C /home/module/
删除安装包:rm elasticsearch-7.17.14-linux-x86_64.tar.gz
1. elasticsearch不能使用root用户运行,可以使用上面创建的hadoop用户,来解约es安装包
mac电脑:创建用户等操作很麻烦,适合装linux上https://blog.csdn.net/tobrainto/article/details/117935714
2. Elasticsearch是使用Java语言开发的,所以需要在环境上安装jdk并配置环境变量,8.x以上版本需要jdk17以上的环境
3. 关闭防火墙
# 启动前提前期解决的问题
1.错误 max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
在linux系统:/etc/security/limits.conf
编辑该文件,后面加上:
hadoop soft nofile 65536
hadoop hard nofile 65536
此配置搭建hadoop时已修改过
2.max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决:切换到root用户修改配置sysctl.conf
vi /etc/sysctl.conf
添加配置:vm.max_map_count=655360
并执行命令:sysctl -p
3.内存不足max number of threads [1024] for user [es] likely too low, increase to at least [2048]
解决:切换到root用户,进入limits.d目录下修改配置文件
vi /etc/security/limits.d/20-nproc.conf
修改如下内容:* soft nproc 1024
修改为:* soft nproc 2048
此配置搭建hadoop时已修改过
4. /home/module/elasticsearch-8.0.0/config/jvm.options
默认是4g
## -Xms4g
## -Xmx4g
5.path.data: /path/to/data1,/path/to/data2
设置索引数据的存储路径,默认是elasticsearch根目录下的data文件夹。切记不要使用默认值,因为若elasticsearch进行了升级,则有可能导致数据全部丢失。可以用半角逗号隔开设置的多个存储路径,在多硬盘的服务器上设置多个存储路径是很有必要的
***以上配置修改完成后,记得分发到其他服务器
集群内部安全通信
ElasticSearch集群内部的数据是通过9300进行传输的,如果不对数据加密,可能会造成数据被抓包,敏感信息泄露。
解决方案: 为节点创建证书
TLS 协议要求Trusted Certificate Authority (CA)签发x.509的证书。证书认证的不同级别:
Certificate ——节点加入需要使用相同CA签发的证书
Full Verification——节点加入集群需要相同CA签发的证书,还需要验证Host name 或IP地址
No Verification——任何节点都可以加入,开发环境中用于诊断目的生成节点证书
命令 elasticsearch-certutil 简化了生成证书的过程,它负责生成CA并与CA签署证书
1. 创建证书颁发机构CA
随便进入一个节点的bin 目录下执行elasticsearch-certutil 命令即可,如下
# 该命令输出单个文件,默认名称为elastic-stack-ca.p12。此文件是PKCS#12密钥库
# 其中包含CA的公共证书和用于对每个节点的证书签名的私钥。
bin/elasticsearch-certutil ca
执行这个命令之后:
会让你输入生成elastic-stack-ca.p12文件放在哪。(直接回车,会放在/home/module/elasticsearch-7.17.14/目录)
回车之后让你输入密码,该密码是让你保护文件和密钥的。直接回车
2. 生成证书和私钥
# 此命令生成证书凭证,输出的文件是单个PKCS#12密钥库,其中包括节点证书,节点密钥和CA证书。
bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12
执行命令之后需要你操作3次:
第一次,输入上面生成CA的密码,没有设置直接回车
第二次,生成的文件路径,直接回车
第三次,生成这次证书与私钥文件的密码,建议和上面生成CA一致(怕忘记密码,也可以直接回车)
3. 移动到config目录下
mv *.p12 config/
4. 将如上命令生成的两个证书文件拷贝到另外两个节点作为通信依据
## 三个ES节点增加如下配置,elasticsearch.yml 配置
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.client_authentication: required
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
5. 开启并配置X-Pack的认证
修改elasticsearch.yml配置文件,开启xpack认证机制
xpack.security.enabled: true
测试:
使用Curl访问ES,返回401错误curl localhost:9200/_cat/nodes
使用浏览器访问,需要账号密码,elastic : 123456
6. 为内置账号添加密码
ES中内置了几个管理其他集成组件的账号即:apm_system, beats_system, elastic, kibana, logstash_system, remote_monitoring_user,使用之前,首先需要添加一下密码
需要启动集群服务才能设置密码
bin/elasticsearch-setup-passwords interactive
interactive:给用户手动设置密码
auto:自动生成密码
# 配置描述
# 加入如下配置
#指定集群名称3个节点必须一致
cluster.name: es-cluster
#指定节点名称,每个节点名字唯一
node.name: es-hadoop200
#是否有资格为master节点,默认为true
node.master: true
#是否为data节点,默认为true
node.data: true
#绑定ip,开启远程访问,可以配置0.0.0.0
network.host: 0.0.0.0
#指定web端口
http.port: 9200
#指定tcp端口
transport.tcp.port: 9300
#用于节点发现
discovery.seed_hosts: ["192.168.111.94", "192.168.111.95", "192.168.111.98"]
#7.0新引入的配置项,初始仲裁,仅在整个集群首次启动时才需要初始仲裁。
#该选项配置为node.name的值,指定可以初始化集群主节点的名称
cluster.initial_master_nodes: ["es-hadoop200", "es-hadoop201", "es-hadoop202"]
#解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"
## elasticsearch.yml 配置
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.client_authentication: required
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
# hadoop200主节点配置修改
cluster.name: es-cluster
node.name: es-hadoop200
node.master: true
node.data: true
network.host: 192.168.111.94
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.111.94", "192.168.111.95", "192.168.111.98"]
cluster.initial_master_nodes: ["es-hadoop200", "es-hadoop201", "es-hadoop202"]
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.client_authentication: required
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
ingest.geoip.downloader.enabled: false
#hadoop201节点配置修改
node.name: es-hadoop201
network.host: 192.168.111.95
修改这2个属性即可,其他不用改
#hadoop202节点配置修改
node.name: es-hadoop202
network.host: 192.168.111.98
修改这2个属性即可,其他不用改
启动、关闭es
1. 进入bin目录启动
前台启动:./elasticsearch,ctrl+c关闭服务
后台启动:./elasticsearch -d
后台启动后,关闭
# 查看进程id
ps -ef | grep elastic
# 关闭进程
kill -9 1376(进程id)
3. 查看cat所有命令
http://192.168.111.94:9200/_cat/
cat命令明细
GET /_cat/nodes?v #查看节点信息
GET /_cat/health?v #查看集群当前状态:红、黄、绿
GET /_cat/shards?v #查看各shard的详细情况
GET /_cat/shards/{index}?v #查看指定分片的详细情况
GET /_cat/master?v #查看master节点信息
GET /_cat/indices?v #查看集群中所有index的详细信息
GET /_cat/indices/{index}?v #查看集群中指定index的详细信息
kibana 安装部署
1. 解压:
[hadoop@hadoop200 software]$ tar -zxvf kibana-7.17.14-linux-x86_64.tar.gz -C /home/module/
2. 修改名字
[hadoop@hadoop200 module]$ mv kibana-7.17.14-linux-x86_64 kibana-7.17.14
3. 修改配置文件,进入config目录
vim kibana.yml
# 修改以下内容
server.port: 5601
server.host: "192.168.111.94"
elasticsearch.hosts: ["http://192.168.111.94:9200","http://192.168.111.95:9200","http://192.168.111.98:9200"]
elasticsearch.username: "kibana_system"
elasticsearch.password: "123456"
4. 后台启动,使用nohup命令,默认不允许使用root运行
[hadoop@hadoop200 bin]$ nohup ./kibana &
5. 访问
http://192.168.111.94:5601/
账号:elastic
密码:123456
elasticsearch-head
配置nodejs环境
下载地址:https://nodejs.org/dist/v16.14.0/node-v16.14.0-linux-x64.tar.xz
1. 解压
[hadoop@hadoop200 software]$ tar -xvJf node-v16.14.0-linux-x64.tar.xz -C /home/module/
2. 重命名
[hadoop@hadoop200 module]$ mv node-v16.14.0-linux-x64 nodejs
3. 配置环境变量
sudo vim /etc/profile.d/my_env.sh
#nodejs
export NODE_HOME=/home/module/nodejs
export PATH=$PATH:$NODE_HOME/bin
4.让环境变量生效
source /etc/profile.d/my_env.sh
5. 测试是否配置成功
node -v
配置elasticsearch-head
下载地址:https://github.com/mobz/elasticsearch-head/archive/master.zip
1.解压
[hadoop@hadoop200 software]$ unzip elasticsearch-head-master.zip -d /home/module/
2.重命名
[hadoop@hadoop200 module]$ mv elasticsearch-head-master elasticsearch-head
3.修改Gruntfile.js
connect: {
server: {
options: {
hostname: '*',---增加此句代码
port: 9100,
base: '.',
keepalive: true
}
}
}
4.修改app.js
cd /home/module/elasticsearch-head/_site
vim app.js,/init,找到并修改下面的地址,4388行附近
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://192.168.111.94:9200";
4.进入到elasticsearch-head目录
cd elasticsearch-head
#切换软件源,可以提升安装速度
npm config set registry https://registry.npm.taobao.org
# 执行安装命令
npm install -g [email protected]
npm install [email protected] --ignore-scripts
npm install
# 启动命令
npm run start
后台运行,需要手动输入exit关闭shell连接,要不会关掉9100的进程
nohup npm run start >/dev/null 2>&1 &
关闭:
查看head 进程:lsof -i :9100
停止head:kill -9 进程id
5.访问
访问一直显示:集群健康值: 未连接,手动输入正确的http://192.168.111.94:9200/,点击连接时报401
处理401:3台es的配置,增加如下配置
http.cors.allow-headers: Authorization,content-type
修改三台es节点后重新启动,以url+认证信息方式可以正常访问es集群
http://192.168.111.94:9100/?auth_user=elastic&auth_password=123456
部署kafka集群
下载:http://kafka.apache.org/downloads.html
新建kafka的日志目录,因为默认放在tmp目录,而tmp目录中内容会随重启而丢失
[hadoop@hadoop200 home]$ sudo mkdir data
[hadoop@hadoop200 home]$ sudo mkdir data/kafka
[hadoop@hadoop200 home]$ sudo mkdir data/kafka/data
[hadoop@hadoop200 home]$ sudo mkdir data/kafka/logs
赋予权限,修改所属主和所属组
[hadoop@hadoop200 home]$ sudo chown -R hadoop:hadoop /home/data/
1.分发到其他2台服务器
[hadoop@hadoop200 software]$ /home/hadoop/bin/xsync /home/software/kafka_2.13-3.1.0.tgz
2.三台服务器分别解压
[hadoop@hadoop200 module]$ tar -zxvf /home/software/kafka_2.13-3.1.0.tgz -C /home/module/
3.修改配置文件,config目录server.properties,只需要改下面三个配置即可,其他都默认
#broker的全局唯一编号,不能重复,只能是数字。三台服务器broker.id分别对应1,2,3
broker.id=0
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/home/data/kafka/logs
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=192.168.111.94:2181,192.168.111.95:2181,192.168.111.98:2181/kafka
可以考虑修改一台后进行分发,在修改其他2台的broker.id
#broker的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/home/data/kafka/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=192.168.111.94:2181,192.168.111.95:2181,192.168.111.98:2181/kafka
# 配置kafka环境变量
1.[hadoop@hadoop200 profile.d]$ sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/home/module/kafka_2.13-3.1.0
export PATH=$PATH:$KAFKA_HOME/bin
2.刷新环境变量:[hadoop@hadoop200 profile.d]$ source /etc/profile
3.分发到其他服务器,并刷新环境变量
[hadoop@hadoop200 profile.d]$ sudo /home/hadoop/bin/xsync /etc/profile.d/my_env.sh
启动集群
kafka启动时先启动zookeeper,再启动kafka;关闭时相反,先关闭kafka,再关闭zookeeper
停止Kafka集群时,一定要等Kafka所有节点进程全部停止后再停止Zookeeper集群。因为Zookeeper集群当中记录着Kafka集群相关信息,Zookeeper集群一旦先停止,Kafka集群就没有办法再获取停止进程的信息,只能手动杀死Kafka进程了。
# 依次在hadoop200、hadoop201、hadoop202节点上启动Kafka
[hadoop@hadoop200 bin]$ ./kafka-server-start.sh -daemon ../config/server.properties
#关闭集群
bin/kafka-server-stop.sh
#集群启停脚本
1.[hadoop@hadoop200 bin]$ vim kafka.sh
#! /bin/bash
case $1 in
"start"){
for i in hadoop200 hadoop201 hadoop202
do
echo " --------启动 $i Kafka-------"
ssh $i "/home/module/kafka_2.13-3.1.0/bin/kafka-server-start.sh -daemon /home/module/kafka_2.13-3.1.0/config/server.properties"
done
};;
"stop"){
for i in hadoop200 hadoop201 hadoop202
do
echo " --------停止 $i Kafka-------"
ssh $i "/home/module/kafka_2.13-3.1.0/bin/kafka-server-stop.sh "
done
};;
esac
2.添加执行权限
[hadoop@hadoop200 bin]$ chmod +x kafka.sh
3.启动集群命令:
[hadoop@hadoop200 bin]$ ./kafka.sh start
[hadoop@hadoop200 bin]$ ./kafka.sh stop
#查看操作主题命令参数:bin/kafka-topics.sh
参数 描述
--bootstrap-server <String: server toconnect to> 连接的Kafka Broker主机名称和端口号。
--topic <String: topic> 操作的topic名称。
--create 创建主题。
--delete 删除主题。
--alter 修改主题。
--list 查看所有主题。
--describe 查看主题详细描述。
--partitions <Integer: # of partitions> 设置分区数。
--replication-factor<Integer: replication factor> 设置分区副本。
--config <String: name=value> 更新系统默认的配置。
#查看操作生产者命令参数: bin/kafka-console-producer.sh
参数 描述
--bootstrap-server <String: server toconnect to> 连接的Kafka Broker主机名称和端口号。
--topic <String: topic> 操作的topic名称。
#查看操作消费者命令参数: bin/kafka-console-consumer.sh
参数 描述
--bootstrap-server <String: server toconnect to> 连接的Kafka Broker主机名称和端口号。
--topic <String: topic> 操作的topic名称。
--from-beginning 从头开始消费。
--group <String: consumer group id> 指定消费者组名称。
#kafka命令行操作
1.主题命令行操作
1)查看操作主题命令参数:bin/kafka-topics.sh --bootstrap-server hadoop200:9092 --list
2)创建first topic:bin/kafka-topics.sh --bootstrap-server hadoop200:9092 --create --partitions 1 --replication-factor 1 --topic first
3)查看first主题的详情:bin/kafka-topics.sh --bootstrap-server hadoop200:9092 --describe --topic first
4)修改分区数(注意:分区数只能增加,不能减少):bin/kafka-topics.sh --bootstrap-server hadoop200:9092 --alter --topic first --partitions 3
5)删除topic:bin/kafka-topics.sh --bootstrap-server hadoop200:9092 --delete --topic first
2.生产者命令行操作
1)发送消息:bin/kafka-console-producer.sh --bootstrap-server hadoop200:9092 --topic first
3.消费者命令行操作(重新打开一个shell连接,随便哪台服务器都行,在生产者那边输入,消费者这边可以接收到)
1)消费first主题中的数据:bin/kafka-console-consumer.sh --bootstrap-server hadoop200:9092 --topic first
2)把主题中所有的数据都读取出来(包括历史数据):bin/kafka-console-consumer.sh --bootstrap-server hadoop200:9092 --from-beginning --topic first
部署Logstash
Logstash没有提供集群安装方式,相互之间并没有交互,但是我们可以配置同属一个Kafka消费者组,来实现统一消息只消费一次的功能
1.解压
[hadoop@hadoop200 software]$ tar -zxvf logstash-7.17.14-linux-x86_64.tar.gz -C /home/module/
2.新建配置文件
cd logstash/config目录
[hadoop@hadoop200 config]$ vim logstash-kafka.conf
# 新增以下内容
input {
kafka {
codec => "json"
group_id => "logstash"
client_id => "logstash-api"
topics_pattern => "api_log"
type => "api"
bootstrap_servers => "192.168.111.94:9092,192.168.111.95:9092,192.168.111.98:9092"
auto_offset_reset => "latest"
}
kafka {
codec => "json"
group_id => "logstash"
client_id => "logstash-operation"
topics_pattern => "operation_log"
type => "operation"
bootstrap_servers => "192.168.111.94:9092,192.168.111.95:9092,192.168.111.98:9092"
auto_offset_reset => "latest"
}
kafka {
codec => "json"
group_id => "logstash"
client_id => "logstash-debugger"
topics_pattern => "debugger_log"
type => "debugger"
bootstrap_servers => "192.168.111.94:9092,192.168.111.95:9092,192.168.111.98:9092"
auto_offset_reset => "latest"
}
kafka {
codec => "json"
group_id => "logstash"
client_id => "logstash-nginx"
topics_pattern => "nginx_log"
type => "nginx"
bootstrap_servers => "192.168.111.94:9092,192.168.111.95:9092,192.168.111.98:9092"
auto_offset_reset => "latest"
}
}
output {
if [type] == "api"{
elasticsearch {
hosts => ["192.168.111.94:9200","192.168.111.95:9200","192.168.111.98:9200"]
index => "logstash_api-%{+YYYY.MM.dd}"
user => "elastic"
password => "123456"
}
}
if [type] == "operation"{
elasticsearch {
hosts => ["192.168.111.94:9200","192.168.111.95:9200","192.168.111.98:9200"]
index => "logstash_operation-%{+YYYY.MM.dd}"
user => "elastic"
password => "123456"
}
}
if [type] == "debugger"{
elasticsearch {
hosts => ["192.168.111.94:9200","192.168.111.95:9200","192.168.111.98:9200"]
index => "logstash_debugger-%{+YYYY.MM.dd}"
user => "elastic"
password => "123456"
}
}
if [type] == "nginx"{
elasticsearch {
hosts => ["192.168.111.94:9200","192.168.111.95:9200","192.168.111.98:9200"]
index => "logstash_nginx-%{+YYYY.MM.dd}"
user => "elastic"
password => "123456"
}
}
}
3.启动logstash
cd bin目录
启动命令:nohup ./logstash -f ../config/logstash-kafka.conf &
查看日志:[hadoop@hadoop200 bin]$ tail -500f nohup.out
部署Filebeat
Filebeat用于安装在业务软件运行服务器,收集业务产生的日志,并推送到我们配置的Kafka、Redis、RabbitMQ等消息中间件,或者直接保存到Elasticsearch
1.解压
[hadoop@hadoop200 software]$ tar -zxvf filebeat-7.17.14-linux-x86_64.tar.gz -C /home/module/
重命名:
[hadoop@hadoop200 module]$ mv filebeat-7.17.14-linux-x86_64 filebeat-7.17.14
2.编辑配置filebeat.yml
配置文件中默认是输出到elasticsearch,这里我们改为kafka,同文件目录下的filebeat.reference.yml文件是所有配置的实例,可以直接将kafka的配置复制到filebeat.yml
2.1 配置采集开关和采集路径
- type: filestream
# Change to true to enable this input configuration.
# enable改为true
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
# 修改微服务日志的实际路径
paths:
- /home/data/project/order/*.log
- /home/data/project/pay/*.log
2.2 Elasticsearch 模板配置
# ======================= Elasticsearch template setting =======================
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
#index.codec: best_compression
#_source.enabled: false
# 允许自动生成index模板
setup.template.enabled: true
# # 生成index模板时字段配置文件
setup.template.fields: fields.yml
# # 如果存在模块则覆盖
setup.template.overwrite: true
# # 生成index模板的名称
setup.template.name: "project_log"
# # 生成index模板匹配的index格式
setup.template.pattern: "filebeat-*"
#索引生命周期管理ilm功能默认开启,开启的情况下索引名称只能为filebeat-*, 通过setup.ilm.enabled: false进行关闭;
setup.ilm.pattern: "{now/d}"
setup.ilm.enabled: false
setup.dashboards.enabled: true
2.3 开启仪表盘并配置使用Kibana仪表盘
setup.kibana:
host: "192.168.111.94:5601"
2.4 配置输出到Kafka,完整的filebeat.yml如下:
# ============================== Filebeat inputs ===============================
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /home/data/project/*/*operation.log
fields:
topic: operation_log
- type: filestream
enabled: true
paths:
- /home/data/project/*/*api.log
fields:
topic: api_log
- type: filestream
enabled: true
paths:
- /home/data/project/*/*debug.log
fields:
topic: debugger_log
- type: filestream
enabled: true
paths:
- /home/data/project/*/access.log
fields:
topic: nginx_log
# ============================== Filebeat modules ==============================
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
# ======================= Elasticsearch template setting =======================
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
#index.codec: best_compression
#_source.enabled: false
setup.template.enabled: true
setup.template.fields: fields.yml
setup.template.overwrite: true
setup.template.name: "project_log"
setup.template.pattern: "filebeat-*"
setup.ilm.pattern: "{now/d}"
setup.ilm.enabled: false
setup.dashboards.enabled: true
# =================================== Kibana ===================================
setup.kibana:
host: "192.168.111.94:5601"
username: "elastic"
password: "123456"
# =============================== Elastic Cloud ================================
# ================================== Outputs ===================================
# ---------------------------- Elasticsearch Output ----------------------------
#output.elasticsearch:
#hosts: ["192.168.111.94:9200","192.168.111.95:9200","192.168.111.98:9200"]
# ------------------------------ Logstash Output -------------------------------
# -------------------------------- Kafka Output --------------------------------
output.kafka:
enabled: true
hosts: ["192.168.111.94:9092","192.168.111.95:9092","192.168.111.98:9092"]
topic: '%{[fields.topic]}'
partition.hash:
reachable_only: true
compression: gzip
max_message_bytes: 1000000
required_acks: 1
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
执行filebeat启动命令:./filebeat -e -c filebeat.yml
后台启动:nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
停止:ps -ef |grep filebeat
kill -9 进程号
测试配置是否正确
1.测试filebeat是否能够采集log文件并发送到Kafka
在kafka服务器开启消费者,监听api_log主题
./kafka-console-consumer.sh --bootstrap-server 192.168.111.94:9092 --topic api_log
手动写入日志文件,按照filebeat配置的采集目录写入
echo "api log1111" > /home/data/project/order/api.log
查看消费者是否接收到消息
2.elasticsearch-head中查看概览、数据浏览是否有数据
http://192.168.111.94:9100/?auth_user=elastic&auth_password=123456
3.配置Kibana用于日志统计和展示
依次点击左侧菜单Management -> Stack Management -> Kibana -> Index patterns , 输入logstash_* ,选择@timestamp,再点击Create index pattern按钮,完成创建。
点击日志分析查询菜单Analytics -> Discover,选择logstash_* 进行日志查询