网络爬虫—02网络数据采集
文章目录
- 一、网络数据采集之urllib库
- 二、网络数据采集之requests库
- request方法
- response对象
- 高级应用一:添加headers
- 高级应用二:IP代理设置
- 三、项目案例一:京东商品的爬取
- 项目案例二:百度/360搜索关键字提交
Python 给人的印象是抓取网页非常方便,提供这种生产力的,主要依靠的就是 urllib、requests这两个模块。重点学习requests
一、网络数据采集之urllib库
官方文档地址:https://docs.python.org/3/library/urllib.html
urllib库是python的内置HTTP请求库,包含以下各个模块内容:
(1)urllib.request:请求模块
(2)urllib.error:异常处理模块
(3)urllib.parse:解析模块
(4)urllib.robotparser:robots.txt解析模块
urlopen进行简单的网站请求,不支持复杂功能如验证、cookie和其他HTTP高级功能,若要支持这些功能必须使用build_opener()函数返回的OpenerDirector对象。
很多网站为了防止程序爬虫爬网站照成网站瘫痪,会需要携带一些headers头部信息才能访问, 我们可以通过urllib.request.Request对象指定请求头部信息.
from urllib.request import urlopen, Request
# response = urlopen('http://www.python.org/')
# print(response)
# print(dir(response))
# print(response.read()[:20])
# 方法一:通过get方法请求url
with urlopen('http://www.python.org/') as f :
# 默认返回的页面信息是bytes类型,bytes类型转换成字符串用decode encode
print(f.read(20).decode('utf-8'))
# 方法二:通过Request对象发起请求
User_agent ='Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0'
# 封装请求头部信息,模拟浏览器向服务器发起请求
request = Request('http://www.python.org/', headers={'User-Agent':User_agent}) #重写头部信息
with urlopen(request) as f :
print(f.read(20).decode('utf-8'))二、网络数据采集之requests库
requests官方网址: https://requests.readthedocs.io/en/master/
安装:
pip install -i http://pypi.douban.com/simple requestsrequest方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法 |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELETE |
import requests
#requests 没有捕获异常的模块
from urllib.error import HTTPError
# 用GET方法获取
def get():
# url = 'http://127.0.0.1:5000/'
#可以获取页面数据,也可以提交非敏感数据:名字,页数,每页显示几条数据
# 问号后提交给服务器
# url = 'http://127.0.0.1:5000/?username=zhangsan&page=18per_page=5'
try:
#将网址后面的信息拼接起来
params = {
'username':'zhangsan',
'page':1,
'per_page':5
}
url = 'http://127.0.0.1:5000/'
# response = requests.get(url) # 请求网址,返回一个响应
response = requests.get(url, params=params) #用到params,将url和params里的内容自动拼接
print(response.text,response.url)
# print(response)
# print(dir(response))
# print(response.status_code)
# print(response.text)
# print(response.content)
# print(response.encoding)
except HTTPError as e :
print('失败:%s' % (url, e.reason))
#用POST方法提交数据
def post():
url = 'http://127.0.0.1:5000/post'
try:
data = {
'username':'admain',
'password':'123'
}
response = requests.post(url,data = data) # 信息提交 登录
print(response)
print(response.text)
except HTTPError as e :
print('失败:%s' % (url, e.reason))
if __name__ == '__main__':
get()
# post()response对象
Response对象包含服务器返回的所有信息,也包含请求的Request信息。
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404失败 |
| r.text | HTTP响应内容的字符串形式,URL对应的页面内容 |
| r.content | HTTP响应内容的二进制形式 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应的编码方式(备选编码方式) |
高级应用一:添加headers
有些网站访问时必须带有浏览器等信息,如果不传入headers就会报错
headers = {'User=Agent':useragent}
response = requests.get(url, headers = heders)UserAgent是识别浏览器的一串字符串,相当于浏览器的身份证,在利用爬虫爬取网站数据时,频繁更换UserAgent可以避免触发相应的反爬机制。
fake-useragent对频繁更换UserAgent提供了很好的支持,可谓防反扒利器。
# 用户代理
import requests
from fake_useragent import UserAgent
def add_headers():
"""
封装一个请求头部,获取页面的时候加进去,get,post都可以
不同的浏览器 请求头部不同
"""
#谷歌浏览器的请求头部 拷贝过来
# headers= {'user_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}
# 默认情况下python爬虫的用户代理是:客户端请求的user_agent: python-requests/2.22.0
ua = UserAgent() # 从网络获取所有的用户代理
# print(ua.random) #可以随机拿出一个用户代理
headers = {'user_Agent': ua.random}
response = requests.get('http://127.0.0.1:5000', headers=headers)
print(response)
if __name__ == '__main__':
add_headers()高级应用二:IP代理设置
在进行爬虫爬取时,有时候爬虫会被服务器给屏蔽掉,这时采用的方法主要有降低访问时间,通过代理IP访问。ip可以从网上抓取,或者某宝购买。
proxies = { "http": "http://127.0.0.1:9743", "https": "https://127.0.0.1:9743",}
response = requests.get(url, proxies=proxies)# IP代理
import requests
from fake_useragent import UserAgent
ua = UserAgent()
# 代理IP
proxies = {
'http':'http://222.95.144.65:3000',
'https':'https://182.92.220.212:8080'
}
response = requests.get('http://47.92.255.98:8000',
headers = {'User-Agent':ua.random},
proxies = proxies)
print(response)
# 这是因为服务器端会返回数据:get提交的数据和请求的客户端ip
#如何判断是否成功:返回的客户端IP刚好是代理IP
print(response.text)三、项目案例一:京东商品的爬取
from urllib.error import HTTPError
from colorama import Fore
import requests
from fake_useragent import UserAgent
def download_page(url, params=None):
try:
ua = UserAgent()
headers = {'User-Agent': ua.random}
response = requests.get(url, params=params, headers = headers)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站失败:%s' %(url, e.reason) )
return None
else:
return response.content #content 返回的是bytes类型
def download_file(content = b'' ,filename='hello.html'):
"""
:param filename: 写入本地的文件名
:param content: 要写入本地的html字符串 bytes类型
:return:
"""
with open(filename, 'wb') as f:
f.write(content)
print(Fore.GREEN+'[+] 写入文件%s成功' %(filename))
if __name__ == '__main__':
url = 'https://item.jd.com/100012014970.html'
html = download_page(url)
download_file(content=html)运行结果: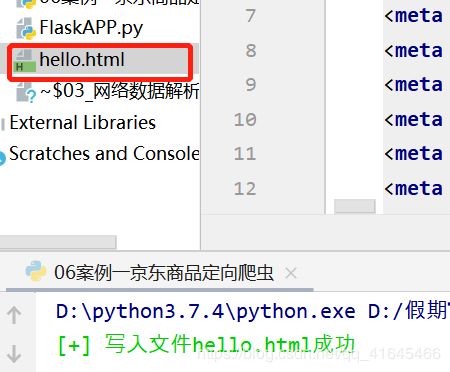
项目案例二:百度/360搜索关键字提交
百度的关键词接口:https://www.baidu.com/baidu?wd=xxx&tn=monline_4_dg
360的关键词接口:http://www.so.com/s?q=keyword
from urllib.error import HTTPError
from colorama import Fore
import requests
from fake_useragent import UserAgent
def download_page(url, params=None):
try:
ua = UserAgent()
headers = {'User-Agent': ua.random}
response = requests.get(url, params=params, headers = headers)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站失败:%s' %(url, e.reason) )
return None
else:
return response.content #content 返回的是bytes类型
def download_file(content = b'' ,filename='sousuo.html'):
"""
:param filename: 写入本地的文件名
:param content: 要写入本地的html字符串 bytes类型
:return:
"""
with open(filename, 'wb') as f:
f.write(content)
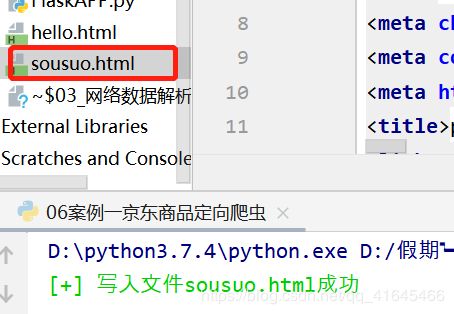
print(Fore.GREEN+'[+] 写入文件%s成功' %(filename))
if __name__ == '__main__':
url = 'https://www.so.com/s'
params = {
'q':'python'
}
content = download_page(url,params)
download_file(content)运行结果: