团队项目(2.2) -- 人脸检测和瞳孔检测
在本项目中,人脸检测参考的主要理论依据为 Kaipeng Zhang,Zhanpeng Zhang,Zhifeng Li,Yu Qiao. Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks. IEEE Signal Processing Letters(SPL), vol.23,no10, pp.1499-1503,2016.,后来在CSDN中找到了一个系列的实战应用及详细的教程和讲解:tensorflow入门教程(三十五)facenet源码分析之MTCNN--人脸检测及关键点检测,博客中讲的肯定比我叙述得更详细,所以这部分尽可能去参考这个系列吧(题外话,这个博主感觉确实是个大牛,尤其是针对于Tensorflow这一块,做了很多详尽的研究)。瞳孔检测部分没有使用神经网络,主要是觉得全都是神经网络解决的话那这个项目就过于简单了,意义不大,因此从这一步起均采用传统图像处理的方法。事实上为了完成瞳孔位置的定位着实花了我很多时间,尝试了很多方法,最后效果虽然一般,但是在这个过程中充分锻炼了自己的思考能力和解决问题的能力。瞳孔检测在人脸识别的基础上需要先进行眼部ROI区域的划定,因此会分为单独的一点来介绍。
下面对环境的搭建和本项目中的具体使用作简单讲解:
一、开发平台及辅助工具等
开发平台:Anaconda
编译环境:Spyder
编程语言:Python
辅助库:OpenCV
二、安装
1、Anaconda安装:手把手教你如何安装Tensorflow(Windows和Linux两种版本
2、Spyder安装:选择Tensorflow环境,点击Spyder下面的Install按钮即可。(我的是已经安装好了,所以显示的是Launch)

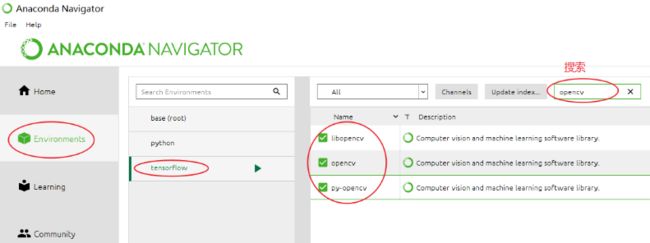
3、OpenCV安装:点击Environments → tensorflow,在搜索栏输入opencv,全点上安装就好了。
4、Facenet源码下载:https://github.com/davidsandberg/facenet/tree/master(参考博客)
三、启动
通常来说我们启动应用时只需要在搜索栏搜索应用然后回车即可,但是由于Anaconda是一个对开发环境的统一管理平台,也就意味着可能同时存在多种环境,比如这次所需的Tensorflow开发环境,因此直接启动的话有可能进不去我们所需的目标环境,所以需要注意下启动方式。
我采用的方式如下:
1、在Windows搜索栏搜索Anaconda Prompt并启动,可以看到一个类似于cmd的窗口被打开:
2、注意到上图中括号内的“base”字样,表示当前为默认环境;
3、输入 activate Tensorflow ,按下回车,可以注意到括号内的字符串变为tensorflowle了,这意味着我们成功进入了搭建的tensorflow环境:4、输入Spyder启动Spyder编译器即可进行代码撰写

至此,开发环境已经搭建完毕,打开对应的py文件即可进行编译。这里贴一个我遇到的问题:

图源及解决方法参考:https://www.cnblogs.com/Terrypython/p/10467859.html
四、完整源码
为便于下面各部分的讲解,先给出完整的源码如下:
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 26 22:40:32 2019
@author: Beta
"""
import cv2
import tensorflow as tf
import align.detect_face
from Filter import Filtercol
from Filter import Findboundcol
from Filter import Findboundrow
video_capture = cv2.VideoCapture(0)
#video_capture = cv2.VideoCapture("E:\\TensorCode\\facenet-master-Mine\\src\\Test.mp4")
totalimgnum = 0;
successnum = 0;
capture_interval = 1
capture_num = 100
capture_count = 0
frame_count = 0
detect_multiple_faces = False #因为是训练目标对象,一次只有一张人脸
#这里引用facenet/src/align/align_dataset_mtcnn.py文件的代码对采集帧进行人脸检测和对齐
minsize = 20 # minimum size of face
threshold = [ 0.6, 0.7, 0.7 ] # three steps's threshold
factor = 0.709 # scale factor
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.5)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = align.detect_face.create_mtcnn(sess, None)
Eyex = 15
Eyey = 10
while True:
ret, orimage = video_capture.read()
totalimgnum += 1
orimage = cv2.flip(orimage,1)#水平翻转
frame = cv2.resize(orimage, (int(orimage.shape[1]/4),int(orimage.shape[0]/4)), interpolation=cv2.INTER_CUBIC ) #缩放为1/4
try:
# cv2.imshow("原图", frame)
h=frame.shape[0]
w=frame.shape[1]
#每1帧采集一张人脸,这里采样不进行灰度变换,直接保存彩色图
if(capture_count%capture_interval == 0):
bounding_boxes, points = align.detect_face.detect_face(frame, minsize, pnet, rnet, onet, threshold, factor)
nrof_faces = bounding_boxes.shape[0]
# print(points.shape) #摄像头原图像尺寸
for face_position in bounding_boxes: #因为只采集一张人脸,所以实际只遍历一次
successnum += 1
face_position=face_position.astype(int)
cropped = frame[face_position[1]:face_position[3],face_position[0]:face_position[2],:]
if(len(points) == 10 and len(points[0]) == 1 ):
# =============================================================================
frame[int(points[5]),int(points[0]) - 10 : int(points[0]) + 10] = [0,0,255]#画出右眼十字
frame[int(points[5]) - 10:int(points[5]) + 10,int(points[0])] = [0,0,255] #画出右眼十字
frame[int(points[6]),int(points[1]) - 10:int(points[1]) + 10] = [255,0,0]#画出左眼十字
frame[int(points[6])-10:int(points[6]) + 10,int(points[1])] = [255,0,0]#画出左眼十字
# =============================================================================
Tresholdw = 1.8#宽的比例
Tresholdh = 0.17#高的比例
width_2 = int((points[1] - points[0])*Tresholdw/2)#眼列半距离
height_2 = int(Tresholdh*width_2)
mideyew = int((points[1] + points[0])/2) #眼列中点
mideyeh = int((points[5]+points[6])/2) #眼行中点
# =============================================================================
# # 显示人眼区域
frame[mideyeh-height_2,mideyew - width_2: mideyew + width_2] = [255,255,0]
frame[mideyeh+height_2,mideyew - width_2: mideyew + width_2] = [255,255,0]
frame[mideyeh-height_2:mideyeh+height_2,mideyew - width_2] = [255,255,0]
frame[mideyeh-height_2:mideyeh+height_2,mideyew + width_2] = [255,255,0]
# =============================================================================
# # 显示人脸区域
orimage[4*face_position[1],4*face_position[0]:4*face_position[2]] = [0,255,0] #上横线
orimage[4*face_position[3],4*face_position[0]:4*face_position[2]] = [0,255,0]
orimage[4*face_position[1]:4*face_position[3],4*face_position[0]] = [0,255,0]
orimage[4*face_position[1]:4*face_position[3],4*face_position[2]] = [0,255,0]
# cv2.imshow("Face",orimage)
# L_eyeimg = frame[mideyeh-height_2:mideyeh+height_2,mideyew - int(5/6*width_2):mideyew - int(1/3 * width_2)]
R_eyeimg = orimage[4*(mideyeh-height_2):4*(mideyeh+height_2),4*(mideyew + int(1/3 * width_2)):4*(mideyew + int(5/6*width_2))]
L_eyeimg = R_eyeimg
L_eyesize = cv2.resize(L_eyeimg, (30,20), interpolation=cv2.INTER_CUBIC ) #缩放为30*20
L_eyegray = cv2.cvtColor(L_eyesize,cv2.COLOR_BGR2GRAY) #灰度化
img_Guassian = cv2.GaussianBlur(L_eyegray,(3,3),0) #高斯滤波
trs,_ = cv2.threshold(img_Guassian, 20, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) # Otsu动态阈值
_,Blackimg = cv2.threshold(img_Guassian,5.5*trs/7,255,cv2.THRESH_BINARY) #二值化
Fillterimg = Filtercol( Blackimg,4)
begincol,endcol = Findboundcol(Fillterimg)
beginrow,endrow = Findboundrow(Fillterimg)
Fillterimg[:,begincol] = 0
Fillterimg[:,endcol] = 0#列
Fillterimg[beginrow,:] = 0
Fillterimg[endrow,:] = 0#行
L_eyesize = cv2.resize(L_eyesize, (300,200), interpolation=cv2.INTER_CUBIC ) #缩放
Blackimg = cv2.resize( Blackimg, (300,200), interpolation=cv2.INTER_CUBIC ) #缩放
Fillterimg = cv2.resize(Fillterimg, (300,200), interpolation=cv2.INTER_CUBIC ) #缩放
##画瞳孔圆
if endcol != 0:
# radius = int((endcol - begincol) / 2) + 1
radius = 6
#print(radius)
Finalx = int((begincol + endcol) / 2)
Finaly = int((beginrow + endrow) / 2)
cv2.circle(L_eyesize,(Finalx*10,Finaly*10),2,(0,255,255),1,0,0)
cv2.circle(L_eyesize,(Finalx*10,Finaly*10),radius*10,(255,0,0),1,0,0)
cv2.imshow("Eye", L_eyesize)
# cv2.imshow("Eye", L_eyesize)
# cv2.imshow("BlackEye", Blackimg)
# cv2.imshow("Fillterimg", Fillterimg)
#cv2.imwrite('F:\\eye.jpg',L_eyeimg)
except:
continue
if cv2.waitKey(1) & 0xFF == ord('q'):
break
print("总帧数:",totalimgnum)
print("识别人脸帧数:",successnum)
print("成功率:",successnum/totalimgnum)
video_capture.release()
cv2.destroyAllWindows()
print('已结束')
四、人脸检测
1、获取摄像头画面
这部分属于OpenCV基础使用,比较简单,获取的图像保存在orimage中:
import cv2
#···
video_capture = cv2.VideoCapture(0)#选定摄像头,默认为0,也可以用这种方式打开打开视频文件,如下
#video_capture = cv2.VideoCapture("E:\\TensorCode\\facenet-master-Mine\\src\\Test.mp4")
while True:
ret, orimage = video_capture.read()
orimage = cv2.flip(orimage,1)#水平翻转
frame = cv2.resize(orimage, (int(orimage.shape[1]/4),int(orimage.shape[0]/4)), interpolation=cv2.INTER_CUBIC ) #缩放为1/4
#...
2、人脸检测:
主要利用detect_face.py中的函数 detect_face(img, minsize, pnet, rnet, onet, threshold, factor)。各参数意义如下:
<入参>
img:即待检测人脸的图片;
minsize:图片中人脸最小尺寸阈值;
pnet、rnet、onet:由函数create_mtcnn(sess, model_path)创建的三层卷积MTCNN神经网络;
threshold:每一层的人脸可信度阈值
factor:缩放因子
<返回值>
total_boxes:人脸ROI区域
points:五官坐标
具体调用:
bounding_boxes, points = align.detect_face.detect_face(frame, minsize, pnet, rnet, onet, threshold, factor)
注意到代码中有一行:
detect_multiple_faces = False #因为是训练目标对象,一次只有一张人脸
这句话的意思是每帧图像只检测一张人脸,因此bounding_boxes中仅保存了一张人脸的位置信息,即下述循环仅执行一次:
for face_position in bounding_boxes:
在执行完人脸检测函数后,人脸ROI区域的四个顶点坐标保存在bounding_boxes中,类似数组调用的方式可以获得,下述程序可以绘制出人脸区域方框图:
# 原图上显示人脸区域
orimage[4*face_position[1],4*face_position[0]:4*face_position[2]] = [0,255,0] #上横线 ,其余类似
orimage[4*face_position[3],4*face_position[0]:4*face_position[2]] = [0,255,0]
orimage[4*face_position[1]:4*face_position[3],4*face_position[0]] = [0,255,0]
orimage[4*face_position[1]:4*face_position[3],4*face_position[2]] = [0,255,0]
五官坐标保存在points中,同样类似数组调用的方式可以获得,下述程序可以实现在眼部绘制出十字:
frame[int(points[5]),int(points[0]) - 10 : int(points[0]) + 10] = [0,0,255]#画出右眼十字
frame[int(points[5]) - 10:int(points[5]) + 10,int(points[0])] = [0,0,255] #画出右眼十字
frame[int(points[6]),int(points[1]) - 10:int(points[1]) + 10] = [255,0,0]#画出左眼十字
frame[int(points[6])-10:int(points[6]) + 10,int(points[1])] = [255,0,0]#画出左眼十字
五、人眼区域划定
由于本项目的实现目标是进行视线跟踪检测,所以在利用上述多层卷积网络得到人脸区域及五官坐标之后,还需要找到人眼区域作为视线移动的参考对象。
人脸五官满足一定的几何比例关系,通过对上述获得的眼部坐标进行一定的比例拓展并经过适量的参数调整即可得到比较好的眼部区域比例与眼部坐标之间的对应比例关系,即可作为我们进行瞳孔识别的ROI区域,减少了计算量。

经过一定的调整,选定比例及实现如下:
Tresholdw = 1.8#宽的比例
Tresholdh = 0.17#高的比例
width_2 = int((points[1] - points[0])*Tresholdw/2)#眼列半距离
height_2 = int(Tresholdh*width_2)
mideyew = int((points[1] + points[0])/2) #眼列中点
mideyeh = int((points[5]+points[6])/2) #眼行中点
# =============================================================================
#显示人眼区域
frame[mideyeh-height_2,mideyew - width_2: mideyew + width_2] = [255,255,0]
frame[mideyeh+height_2,mideyew - width_2: mideyew + width_2] = [255,255,0]
frame[mideyeh-height_2:mideyeh+height_2,mideyew - width_2] = [255,255,0]
frame[mideyeh-height_2:mideyeh+height_2,mideyew + width_2] = [255,255,0]
# =============================================================================
测试结果:

测试时只用了单眼进行处理,另一只眼同理即可,因此需要将单眼区域进行切割,与上述方法类似,这里直接就左眼图像等于右眼图像了,同时统一尺寸为30*20便于处理:
R_eyeimg = orimage[4*(mideyeh-height_2):4*(mideyeh+height_2),4*(mideyew + int(1/3 * width_2)):4*(mideyew + int(5/6*width_2))]
L_eyeimg = R_eyeimg
L_eyesize = cv2.resize(L_eyeimg, (30,20), interpolation=cv2.INTER_CUBIC ) #缩放为30*20
处理结果如下:

六、瞳孔检测
由于上述神经网络标定的五官坐标的精准度并不能达到项目的要求(如下图),因此在获取眼部区域的基础上设计了瞳孔定位的算法。

尝试了两种算法,都有一定的效果。最后采用的是第二种,但是仍然将两种方法都贴出来供交流:
方法一: 视频瞳孔跟踪之星团模型,参考链接博客,给出简单叙述如下:
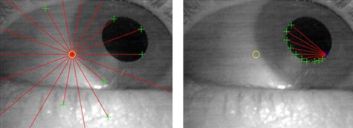
- 抓取第一帧图像,以该图像的中心为起始点;
- 从起始点向四周发出射线,射线间隔20度,共18条,如图d所示。依次沿每条射线前进,当相邻两点像素的差值delta大于设定阈值时停止,这里只考虑正值,即灰度值上升的情况,处理后会得到一个候选边缘点的集合;
然后,依次以每个候选点为起始点,在经过该候选点射线的两侧正负50度范围内再次发出射线,射线条数为n = 5*delta/∅,射线之间的间隔角度为 100/n,射线条数最小值为5。如图所示;
- 步骤1,2完成了第一次迭代,计算所有候选边缘点的几何中心为下次迭代的起始点;
- 重复执行步骤1,2,3直至所有候选边缘点的几何中心收敛于相对稳定的位置,即前后两次迭代计算出的几何中心位置之间的距离不大于10 pixel。如果迭代次数大于等于10几何中心仍未收敛,则说明当前图像中不存在瞳孔区域,有可能是眨眼或其他意外情况;
- 椭圆拟合,采用RANSAC(RANdom SAmple Consensus,随机抽样一致)模型,对候选点进行椭圆拟合,可有效的排出错误的候选点。经过迭代之后会找到一个椭圆所对应的模型一致集合内元素的数量最大,则将该椭圆作为最优拟合椭圆。
实现程序如下:
# -*- coding: utf-8 -*-
"""
Created on Sat Sep 21 11:01:41 2019
@author: Beta
"""
import cv2
import math
import numpy as np
#规定x为横向,y为纵向
#Beginpointx = 15 #第一个迭代的点的列号
#Beginpointy = 10 #第一个迭代的点的行号
def Findcenter(L_eyeimg,Beginpointx,Beginpointy,Tres):
#L_eyeimg = cv2.imread('E:\\TensorCode\\facenet-master-Mine\\src\\eye.jpg')
#归一化为20*30
L_eyesize = cv2.resize(L_eyeimg, (30,20), interpolation=cv2.INTER_CUBIC ) #缩放为30*180
#灰度化
#L_eyesize = L_eyeimg
L_eyegray = cv2.cvtColor(L_eyesize,cv2.COLOR_BGR2GRAY)
#高斯滤波
Blackimg = cv2.GaussianBlur(L_eyegray,(3,3),0)
trs,_ = cv2.threshold(Blackimg, 20, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) # Otsu 滤波
_,img_Guassian = cv2.threshold(Blackimg,5*trs/7,255,cv2.THRESH_BINARY)
#画出第一个圆
#cv2.circle(L_eyesize,(Beginpointx,Beginpointy), 0, (0,255,255), 0)
#cv2.circle(L_eyesize,(10,10), 1, (0,0,255), 0)
#以中心点为起始点,发出18条射线,找出梯度改变的点
#Tres = 30
countsum = 0 #点数
PreparePoint = np.zeros((18,4)) #第一轮备选点
for line in range(0,18):
theta = line * math.pi / 9
x_pre = Beginpointx
y_pre = Beginpointy
while True:
x_now = x_pre + math.cos(theta)
y_now = y_pre - math.sin(theta)
if x_now < 1 or x_now > 29 or y_now < 1 or y_now > 19:
break
Delta = int(img_Guassian[int(y_now),int(x_now)]) - int(img_Guassian[int(y_pre),int(x_pre)])
if Delta > Tres :
if countsum == 0 or (PreparePoint[countsum - 1,0] != int(x_now) and PreparePoint[countsum - 1 ,1] != int(y_now) ):
#L_eyesize[int(y_now),int(x_now)] = (0,255,0)
PreparePoint[countsum,0] = int(x_now)
PreparePoint[countsum,1] = int(y_now)
PreparePoint[countsum,2] = Delta
PreparePoint[countsum,3] = theta
countsum += 1
break
x_pre = x_now
y_pre = y_now
#cv2.imshow("First",L_eyesize)
# print(PreparePoint)
# print(countsum)
#以每一个梯度改变的点为中心点,发出左右各50度的射线
#n = 5*Delta/Tres n为射线条数,最少为5条
#delta = 100 / (n-1) 射线间隔角度
countsum2 = 0
PreparePoint2 = np.zeros((10*countsum,2)) #第一轮备选点
for count in range(0,countsum): #共countsum个点
n = int(5*PreparePoint[count,2]/Tres)
delta = int(100 / (n-1))
for i in range(0,n): #共n条射线
theta = -math.pi + PreparePoint[count,3] + 50/180 * math.pi - i*delta
x_pre = PreparePoint[count,0]
y_pre = PreparePoint[count,1]
while True:
x_now = x_pre + math.cos(theta)
y_now = y_pre - math.sin(theta)
if x_now < 1 or x_now > 29 or y_now < 1 or y_now > 19:
break
Delta = int(img_Guassian[int(y_now),int(x_now)]) - int(img_Guassian[int(y_pre),int(x_pre)])
if Delta > Tres :
if countsum2 == 0 or (PreparePoint2[countsum2 - 1,0] != int(x_now) and PreparePoint2[countsum2 - 1 ,1] != int(y_now)):
L_eyesize[int(y_now),int(x_now)] = (0,0,255)
PreparePoint2[countsum2,0] = int(x_now)
PreparePoint2[countsum2,1] = int(y_now)
countsum2 += 1
break
x_pre = x_now
y_pre = y_now
cv2.imshow("Second",L_eyesize)
# print(PreparePoint2)
#print(countsum2)
sumx = 0
sumy = 0
for i in range(0,countsum2):
sumx += PreparePoint2[i,0]
sumy += PreparePoint2[i,1]
avex = int(sumx/(countsum2+0.01))
avey = int(sumy/(countsum2+0.01))
if avex >= 30 or avex == 0:
avex = Beginpointx
if avey >= 20 or avey == 0:
avey = Beginpointy
return avex,avey,PreparePoint2,countsum2
这种方法适用于图像画质较好的情况,由于当时测试的时候我使用的是笔记本电脑自带的摄像头,画质较差,同时由于受到光照等影响,导致最后瞳孔中心收敛位置并不好,而且收敛速度也没有理想中的那么快,所以就舍弃了这个方案,写了一个更简单粗暴的方案:
方法二:Otsu动态阈值+腐蚀滤波。具体设计如下:
- 基于OTSU动态阈值算法对人眼区域进行处理,得到一个阈值,利用该阈值对人区域进行二值化处理得到初步而二值化图像;
- 上述二值化人眼区域由于人眼凹陷、光线阴影等因素会出现一些干扰的噪点,同时结合人眼狭长的特点,对二值化图像进行纵向的腐蚀滤波,滤出不连续且长度较短的黑色噪点,得到最终的虹膜区域;
- 对上述滤波后的图像进行行、列的遍历,锁定虹膜的最小包络矩形框,以该矩形框的几何中心作为瞳孔中心。
该算法实现起来也很简单:
L_eyegray = cv2.cvtColor(L_eyesize,cv2.COLOR_BGR2GRAY)
img_Guassian = cv2.GaussianBlur(L_eyegray,(3,3),0)
trs,_ = cv2.threshold(img_Guassian, 20, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) # Otsu 动态阈值
_,Blackimg = cv2.threshold(img_Guassian,5.5*trs/7,255,cv2.THRESH_BINARY)
Fillterimg = Filtercol( Blackimg,4) #4个像素点为最小单位的纵向腐蚀滤波
begincol,endcol = Findboundcol(Fillterimg)#找列边界
beginrow,endrow = Findboundrow(Fillterimg)#找行边界
其中,纵向腐蚀滤波实现如下:
#腐蚀滤波num为滤波点数
def Filtercol(img,num):
Filterimg = img
begin = 0
blacknum = 0
jmppointBlack = 0
for col in range(0,img.shape[1]):
for row in range(0,img.shape[0] - 1):
if img[row, col] == 255 and img[row + 1, col] == 0:
begin = row + 1
blacknum += 1
for j in range(begin + 1,img.shape[0] - 1):
if img[j + 1, col] == 0:
blacknum += 1
else:
break
if blacknum <= num and begin + blacknum < img.shape[0]:
for j in range(begin,begin + blacknum):
Filterimg[j,col] = 255
jmppointBlack += 1
row = row + blacknum
blacknum = 0
return Filterimg
寻找边界算法实现如下(以列边界为例):
def Findboundcol(img):
beginline = 0
endline = 0
whitecount = 0
for col in range(0,img.shape[1]):#列
for row in range(0,img.shape[0] - 1):
if beginline == 0 and img[row, col] == 0 and img[row + 1, col] == 0:
beginline = col
break
elif beginline != 0 and img[row, col] == 255:
whitecount += 1
if whitecount >= img.shape[0] - 2:
endline = col
break
else:
whitecount = 0
if endline != 0:
break;
return beginline,endline
七、结果展示
对于检测速度、精准度的改进方法不作叙述,有兴趣的可以进行交流,以下是测试展示:
1、神经网络训练
1.1数据集
(1)CASIA-WebFace人脸数据集[48]:共包含了10575个人的494414张人脸图片
(2)LFW人脸数据集[49]:共包含了5747个人的13234张人脸图片
1.2 训练过程
(1)图像预处理:进行上述数据集的预归一化裁剪总时长5小时
(2)参数整定及人脸模型训练时长总计:一周
1.3训练结果
(1)CASIA-WebFace人脸数据集:494414张人脸图片中共识别出491500张人脸,识别时长1250695ms,成功率达到99.42073%。
(2)LFW人脸数据集:13234张人脸图片共识别出13012张人脸,识别时长33802ms,准确率达到99.07813%。
2、实时识别测试记录
整个工程包括人脸识别、瞳孔检测及消息发送三个部分,消息发送指的是游戏平台和瞳孔检测结果的信息交流过程,放在下一篇博客中叙述。瞳孔检测结果保存在文件夹中,其中每部分详细数据如下:
- 采集画面总时长120000ms,总采集帧数3221帧,每帧平均处理耗时37.256ms;
- 成功识别人脸帧数3213帧,正确率99.7516%;
-
瞳孔检测帧数3213帧,通过人工查看瞳孔检测结果图片,统计成功率为100%,正确率不低于95%。
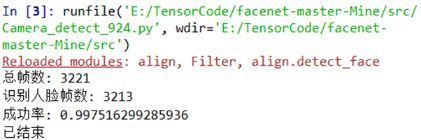 实时人脸检测情况记录
实时人脸检测情况记录

八、总结
在本篇博客中讨论了MTCNN神经网络的实际运用,实现了简单的人脸检测,并利用传统图像处理进行了瞳孔位置实时跟踪检测。事实上,该神经网络还可以进行人脸识别,而且经过我测试,正确率还是比较高的,有兴趣的可以去了解一下。实话说,我自己对于神经网络或者说是深度学习仍然停留在用的层面,要想真正学会对神经网络架构进行设计修改还是比较困难的,以后要走的路还很长。
下一篇博客将对本篇及上一篇博客的成果的对接部分进行讲解及展示,估计发出来已经年后了~
顺便记录一下,最近冠状病毒的事情闹得挺厉害的,家人朋友们都人心惶惶,也希望这事能早日过去。祝家人朋友们健健康康!每个人都要加油喔!
完整工程仓库:https://github.com/Beta-y/facenet-master-Mine