Python爬取bilibili任意视频实战总结
Python爬取bilibili任意视频
前言
在之前的利用Python爬取bilibili今日热门这个实战中,我们可以利用其API接口实现获得视频的真实地址,但是如果是在随意一个B站视频中,却没办法直接获得视频真实地址,只能获得.m4s数据流,但是经过测试发现通过拼接url可以获得.flv格式的视频文件,这就意味着我们可以直接下载B站视频啦!!!
本次使用的模块有以下三个:
re、requests、lxml
本次爬取的视频是这个【唱跳rap篮球】空你大没述
接下来开始:
我们还是打开网址F12,然后刷新一下网址进行抓包,在XHR中有这个网址:
https://api.bilibili.com/x/player/playurl?avid=69542806&cid=120570181&qn=32&type=&otype=json&fnver=0&fnval=16&session=94373099b0667b90f587014146d831c4
获得了以下数据:

这个就是视频的资料了,但是却是.m4s格式,再查看一下所需要提交的参数:
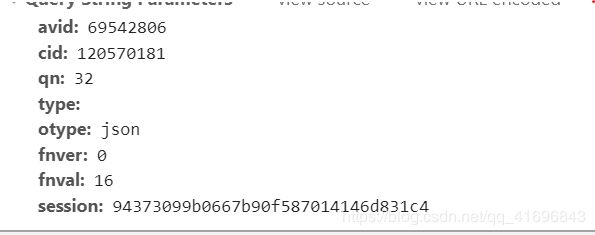
这里的avid是视频的标号(猜想),很容易获得,cid也是可以通过另外一个api很容易获得,qn是视频的质量,高清、流畅什么的
112: 高清 1080P+
80: 高清 1080P
64: 高清 720P
32: 清晰 480P
16: 流畅 360P
但是下面的fnval和session却无法得知是什么东东,于是尝试将原始视频url进行截取,发现如果去掉&fnver=0&fnval=16&session=94373099b0667b90f587014146d831c4
后访问:
https://api.bilibili.com/x/player/playurl?avid=69542806&cid=120570181&qn=32&type=&otype=json
可以得到以下数据:
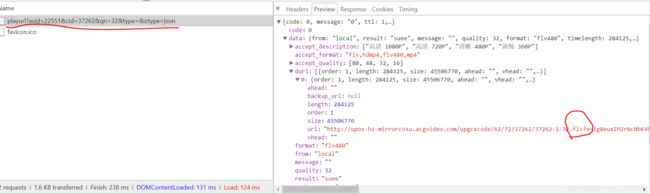
看到了没,flv格式的视频文件!!!这个就是视频的真实flv地址,也就是说我们只要想办法获得cid和avid就可以下载视频了!!!
其中的avid就是我们页面的av后面的一串数字也就是:69542806
用代码显示如下(正则re模块):
avid = re.findall("video/av(.+)\?", url)
至于cid可以从这个接口获得:https://api.bilibili.com/x/player/pagelist?aid=69542806&jsonp=jsonp
代码如下:
def get_cid(aid):#获得cid
header = {
'host': 'api.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
url = "https://api.bilibili.com/x/player/pagelist?aid={aid}&jsonp=jsonp".format(aid=aid)
response = requests.get(url,headers=header).json()
return response["data"][0]["cid"] ,response["data"][0]["part"]
从这个api接口可以的到视频cid和名字等参数,那么接下来就是获得flv的地址咯,代码如下:
def get_flvurl(url):#获得视频真实flv地址传入的url为:url2 = "https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json".format(avid=avid[0],cid=cid)
header = {'host': 'api.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
response = requests.get(url,headers=header).json()
return response["data"]["durl"][0]["url"],response["data"]["durl"][0]["size"]
在这里面可以获得flv视频的真实地址和视频大小,最后就是如何成功访问视频啦,经测试访问真实flv地址必要的header是以下代码还是用的正则表达式:
headers2 = {
"host": "",
"Referer": "https://www.bilibili.com",
"User-Agent": "Mozilla/5.0(Windows NT 10.0;WOW64) AppleWebKit/537.36(KHTML,likeGecko)Chrome/63.0.3239.132Safari/537.36"
}
h = re.findall("http://(.+)com",flv_url)
host = h[0]+"com"
#print(host1)
headers2["host"] = host
其中的User-Agent和Referer都是很容易得到的,但是host需要注意的是其内容是flv地址中http://的后面到com(包含com),如果host拼接错误则会导致访问页面403错误,如果直接用浏览器访问flv真实地址也是会显示403错误,原因就是host和Referer参数不正确。
接下来就是访问并保存视频啦!
访问代码如下:
res = requests.get(flv_url,headers=headers2,stream=True, verify=False)
print(res.status_code)
括号里的的赋值就不解释为什么啦,不知道的可以直接去requests文档查看哟
数据的存储:
def save_movie(res,name):#保存视频
chunk_size = 1024
with open("{name}.flv".format(name = name),"wb") as f:
for data in res.iter_content(1024):
f.write(data)
到这里就完成了B站里面随意视频的爬取了,成果如下:

总结了一下,在不知道参数是什么时,可以尝试删除一些参数去访问,会有意外惊喜哟!!!在此基础上还可以利用爬取单个视频升级成爬取整个专栏的视频呢!!!喜欢的点个小赞赞哟
最后的最后,上代码:
import requests
from lxml import html
import re
#Mr.离
def star(url):
url2 = "https://api.bilibili.com/x/player/playurl?avid={avid}&cid={cid}&qn=32&type=&otype=json"
headers2 = {
"host": "",
"Referer": "https://www.bilibili.com",
"User-Agent": "Mozilla/5.0(Windows NT 10.0;WOW64) AppleWebKit/537.36(KHTML,likeGecko)Chrome/63.0.3239.132Safari/537.36"
}
avid = re.findall("video/av(.+)\?", url)
print(avid)
cid ,name = get_cid(avid[0])
print(name)
flv_url , size = get_flvurl(url2.format(avid=avid[0],cid=cid))
shuju = size / 1024 / 1024
print("本视频大小为:%.2fM" % shuju)
#print(flv_url)
#print(size)
h = re.findall("http://(.+)com",flv_url)
host = h[0]+"com"
#print(host1)
headers2["host"] = host
#print(headers2)
res = requests.get(flv_url,headers=headers2,stream=True, verify=False)
print(res.status_code)
save_movie(res,name)
def get_cid(aid):#获得cid
header = {
'host': 'api.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
url = "https://api.bilibili.com/x/player/pagelist?aid={aid}&jsonp=jsonp".format(aid=aid)
response = requests.get(url,headers=header).json()
return response["data"][0]["cid"] ,response["data"][0]["part"]
def get_flvurl(url):#获得视频真实flv地址
header = {'host': 'api.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
response = requests.get(url,headers=header).json()
return response["data"]["durl"][0]["url"],response["data"]["durl"][0]["size"]
def save_movie(res,name):#保存视频
chunk_size = 1024
with open("{name}.flv".format(name = name),"wb") as f:
for data in res.iter_content(1024):
f.write(data)
if __name__ == "__main__":
url = "https://www.bilibili.com/video/av69542806?spm_id_from=333.334.b_62696c695f646f756761.5"
star(url)