hdfs、tfs、fastdfs、Tachyon的辨析
一、Hdfs
概念:
Hadoop分布式文件系统.
①保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
② 运行在廉价的机器上。
③ 适合大数据的处理。多大?多小?HDFS默认会将文件分割成block,128M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中(namenode)。如果小文件太多,那内存的负担会很重
架构:
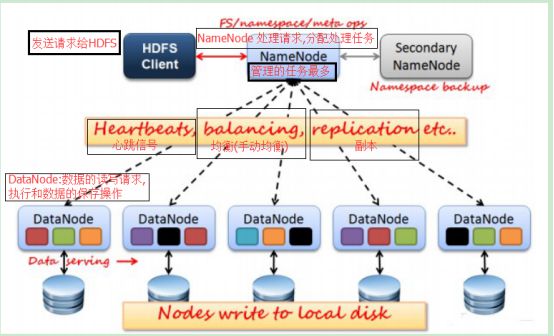
HDFS按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是管理者。1、管理数据块映射;2、处理客户端的读写请求;3、配置副本策略;4、管理HDFS的名称空间;
NameNode保存的metadata包括文件ownership和permission , 文件包含的block信息 , Block保存在那些DataNode节点上(这部分数据并非保存在NameNode磁盘上的,它是在DataNode启动时上报给NameNode的,Name接收到之后将这些信息保存在内存中), NameNode的metadata信息在NameNode启动后加载到内存中 , Metadata存储到磁盘上的文件名称为fsimage , Block的位置信息不会保存在fsimage中 , Edits文件记录了客户端操作fsimage的日志,对文件的增删改等。用户对fsimage的操作不会直接更新到fsimage中去,而是记录在edits中
SecondaryNameNode:分担namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
应用场景:
1) HDFS不适合大量小文件的存储
2) HDFS适用于高吞吐量,而不适合低时间延迟的访问
3)流式读取的方式,不适合多用户写入一个文件
5)HDFS更加适合写入一次,读取多次的应用场景
二、Tfs
概念:
TFS是Team Fundation Server的简称,是微软VSTS的一部分,它是Microsoft应用程序生命周期管理(ALM)工具的核心协作平台,简单的说它是管理和开发软件项目的整个生命周期的平台工具。
是淘宝针对海量非结构化数据存储设计的分布式系统,构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。
是一个分布式的文件系统,目前最新的版本是TFS2.X
TFS的分为客户端层、应用层、数据层。
他们的数据模型流转如下图:
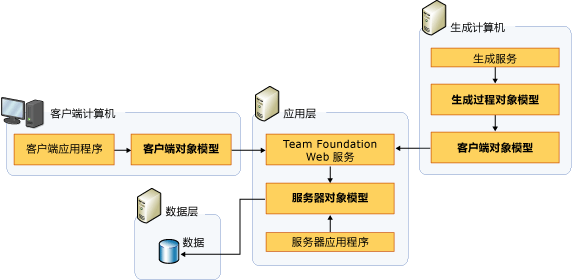
客户端层分为架构师客户端、开发人员客户端、测试人员客户端等。
应用层分为:版本控制、团队生成、团队站点(SharePoint)、工作项跟踪、团队报告(Sql Server Reporting Service)、项目管理、TFS API接口(Web Service)。
数据层:配置数据库、仓库数据库、分析数据库、团队项目集合数据库
TFS2的读写流程

特点:
跨集群同步:
可以再创建一个和TFS对等的集群,由主集群负责写入这个集群 和同步数据 这个集群只对外提供读的功能, 当主机群挂了的时候,这个集群会自动顶上去.
平滑扩容:
由于NameServer和DataServer 之间是通过心跳机制来通信的,如果集群需要扩容,只需要将新的DataServer服务器部署好,然后启动即可.这些DataServer服务器会像NameServer发送心跳汇报 . NameServer的写入策略是 在容量较小,负载较轻的服务器写入新数据的概率会比较高, 同时.在集群负载较轻的时候, NameServer 会对所有的DataServer 和Block进行均衡. 使所有的DataServer容器尽早达到均衡.
容错机制(高可用):
TFS有四重容错机制(我觉得应该算四层,官方文档里面是三层)
1.集群容错:(已了解,直接copy过来,不知道我们会不会部署多个集群呢0.0)
TFS可以配置主辅集群,一般主辅集群会存放在两个不同的机房。主集群提供所有功能,辅集群只提供读。主集群会把所有操作重放到辅集群。这样既提供了负载均衡,又可以在主集群机房出现异常的情况不会中断服务或者丢失数据。
2.NameServer容错:
NameServer采用了HA结构,一主一备,主NameServer上的操作会重放至备NameServer。如果主NameServer出现问题,可以实时切换到备NameServer。
另外: NameServer 与DataServer之间也有心跳机制.DataServer 会将他的Block的信息定时发送到NameServer上, NameServer会根据这些信息重建Block和DataServer的关系(这里高版本的TFS已经不将这个功能放到心跳机制里了,心跳机制只用来检查DataServer是否还活着,以及有没有其他的DataServer加入).
3.DataServer容错:
TFS采用备份多个Block来实现DataServer容错,每个Block 在集群中存在多份,并且他们分别部署在不同网段的不同DataServer上,一般为3份,我记得可以通过配置max_Block....来修改,正是因为这样,如果你只有一台DataServer的时候,那么你的这个属性就要改为1 否则不能启动TFS
对于每一个写入请求.必须等待所有的Block备份完成之后才算写入成功.当出现磁盘损坏或者DataServer宕机的时候,TFS会启动复制流程,通过心跳机制获得这些DataServer上Block的信息,把那备份数小于3的Block尽快复制到其他的DataServer上去.
4.对单个文件的容错:
TFS对每一个文件会记录校验crc ,当客户端访问这个文件的时候发现crc和文件内容不匹配的时候,会自动切换到一个好的Block上去读取.此后客户端会修复单个文件损坏的情况.
并发机制:
对同一个文件来说,TFS支持并发的读 ,但是不支持并发的写入,其实单个Block块也是不支持并发的写入
应用场景:
TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能
三、Fastdfs
概念:
FastDFS是用c语言编写的一款开源的分布式文件系统。FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。
架构:
FastDFS架构包括 Tracker server和Storage server。客户端请求Tracker server进行文件上传、下载,通过Trackerserver调度最终由Storage server完成文件上传和下载。
Trackerserver作用是负载均衡和调度,通过Trackerserver在文件上传时可以根据一些策略找到Storageserver提供文件上传服务。可以将tracker称为追踪服务器或调度服务器。
Storageserver作用是文件存储,客户端上传的文件最终存储在Storage服务器上,Storage server没有实现自己的文件系统而是利用操作系统 的文件系统来管理文件。可以将storage称为存储服务器。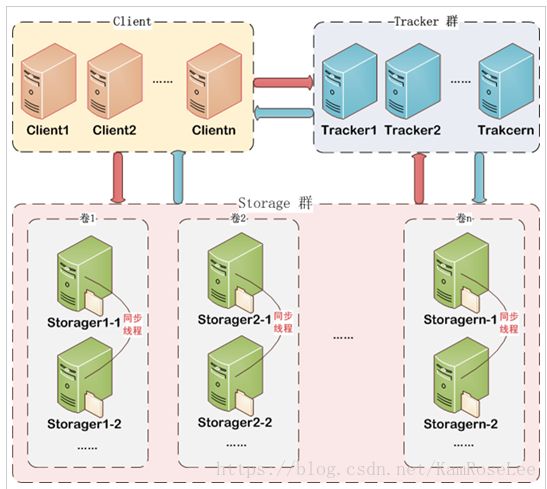
应用场景:
FastDFS适合的存储范围为4KB至500M之间,它更倾向于存储中小型文件,如图片网站、短视频网站、文档、app下载站等。
FastDFS的用户有支付宝、京东、赶集网、58同城、UC、51CTO和一些网盘公司,可以说目前用到FastDFS的公司特别多,因为移动互联网的兴起,一些短视频、电子书、小音频和一些app,都在十几兆或者一两百兆左右,使用FastDFS十分合适。
四、Tachyon
概念:
tachyon是一个分布式内存文件系统,可以在集群里以访问内存的速度来访问存储在Tachyon里的文件。Tachyon是架构在最底层的分布式文件系统和上层的各种计算框架之间的一种中间件,其主要职责是将那些不需要落地到DFS里的文件,落地到分布式内存文件系统中,来达到共享内存,从而提高效率,减少内存冗余,减少GC时间等。
架构 :
tachyon的架构是传统的Master—Slave架构,这里和Hadoop类似,TachyonMaster里WorkflowManager是 Master进程,因为是为了防止单点问题,所以通过Zookeeper做了HA,可以部署多台Standby Master。Slave是由Worker Daemon和Ramdisk构成。Ramdisk使用off heap memory。Master和Worker直接的通讯协议是Thrift。

应用场景:
由于其解决分布式内存计算的分布式数据存储所产生的的问题。所以应用场景基于Spark进行大多数批处理工作。