shell脚本数学运算,数组,文本处理
知识要点
数学运算
数组的使用
seq 、tr 、sort、uniq、cut等命令
整数运算
1.常用运算符
加法运算:+
减法运算: -
乘法运算: *
除法运算: / 得到的是商例如1/2得到是0
求模(取余)运算: %
求幂运算:** bc中的幂运算符号是^
2.常用整数运算
第一种
declare -i a=1020;echo a 少 用 第 二 种 a = a 少用 第二种 a= a少用第二种a=(expr 10 ‘’ 20);echo $a 少用(兼容性好)
注:在*或者**运算时需要加入转义字符\或者’’
第三种
a=$[102] echo a [ ] 中 的 变 量 无 需 加 a []中的变量无需加 a[]中的变量无需加
echo [ R A N D O M 第 四 种 a = [ RANDOM % 10 ],求0-9的随机数 第四种 a= [RANDOM第四种a=((1020));echo $a ( ( ) ) 中 的 变 量 无 需 加 (())中的变量无需加 (())中的变量无需加
echo $(( RANDOM % 10 )) 求0-9的随机数
第五种 (推荐)
((a=1020));echo a 常 用 来 赋 值 ( ( a + + ) ) ( ( ) ) 中 的 变 量 无 需 加 a 常用来赋值 ((a++)) (())中的变量无需加 a常用来赋值((a++))(())中的变量无需加
((a+=10)) 相当于a=a+10
例如:: 第六种
第六种
let a=1020;echo $a 常用来赋值
let i++ 相当于 let i=i+1
let i+=10
条件测试操作
双圆括号整数值比较(推荐方法)
格式(( 整数1 操作符 整数2 ))
==(判断相等)、>、<、!=(判断不相等)、<=、>= 小数运算
小数运算
bash只支持整数的运算, 浮点数运算用bc
(())只能用于整数运算和整数比较。。小数运算和比较要用到bc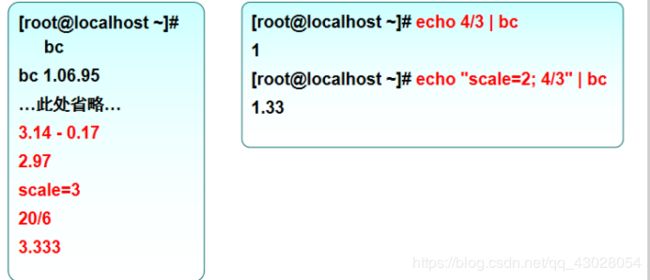 注:1. scale是bc 的一个变量,用来指定小数点后留几位
注:1. scale是bc 的一个变量,用来指定小数点后留几位
2.bc中的比较是否成立,需要通过bc的标准输出来判断 0是不成立 1为成立 补充:printf “%0.2f” 是格式化输出
补充:printf “%0.2f” 是格式化输出
数组的基本用法
1.数组(Array)是一个由若干同类型变量组成的集合,引用这些变量时可用同一名字。数组均由连续的存储单元组成,最低地址对应于数组的第一个元素,最高地址对应于最后一个元素
2.bash Shell只支持一维数组,数组从0开始标号,以array[x]表示数组元素,那么,array[0]就表示array数组的第1个元素、array[1]表示array数组的第2个元素、array[x]表示array数组的第x+1个元素
索引数组(普通数组),下标是数字,有序的,默认从0开始
关联数组,下标是字符串,是无序的
3.声明数组
格式:数组名=(参数1 参数2 ….)
4.多个ip地址存入数组中 注:切片和替换
注:切片和替换
切片:例如在array数组中提取第2个到第6个小标 替换:例如在array数组中将d替换为D,但不会改变数组原来的内容
替换:例如在array数组中将d替换为D,但不会改变数组原来的内容 需要改变数组原来的内容时,需要重定义数组,例如:
需要改变数组原来的内容时,需要重定义数组,例如: 5.查看数组里面的元素个数
5.查看数组里面的元素个数 补充:清除数组中的某个元素,数组下标不会重新排序。重新排序需要重定义数组
补充:清除数组中的某个元素,数组下标不会重新排序。重新排序需要重定义数组
6.利用数组获取当前主机的默认网关 注:route -n 命令可以查看到路由表,路由表中有默认网关
注:route -n 命令可以查看到路由表,路由表中有默认网关
使用route add default gw 172.16.255.254 命令可以添加网关172.16.255.254
grep ‘^0.0.0.0’ 提取以0.0.0.0开头的行
7.将变量替换为数组 8.利用循环为数组赋值
8.利用循环为数组赋值 关联数组(associative array)
关联数组(associative array)
数组bash 4.0开始支持关联数组,RHEL5不支持
关联数组,下标是字符串,无序的, 关联数组的key(下标)不能相同 declare -A 声明是关联数组 echo ${name[@]}得到数组元素内容 echo ${#name[@]}得到下标个数 echo ${!name[@]}得到下标内容
declare -A 声明是关联数组 echo ${name[@]}得到数组元素内容 echo ${#name[@]}得到下标个数 echo ${!name[@]}得到下标内容
seq 命令
seq
用途:打印出一串有序的数字
格式:seq [选项] 数字范围
-s:指定分隔符
-w:指定同等宽带输出 脚本示例
脚本示例
编写脚本创建用户,要求根据输入的用户名前缀和数目自动创建 tr 命令
tr 命令
1.tr命令
字符转换工具
只能对stdin(标准输入)操作,不能直接对文件操作
2.使用tr转换字符
tr SET1 SET2
用SET2中的字符替换掉SET1中同一位置的字符
echo 123456 | tr 345 abc
tr 123 abc < aa
tr ‘[a-z]’ ‘[A-Z]’ < /etc/hosts
echo $PATH | tr ‘:’ ‘\n’
3.使用tr删除字符
tr -d SET
将stdin中数据流删除与SET相同的字符
echo 123456 | tr -d 345
tr -d '[0-9]’ < /etc/hosts
df -h | tr -d %
who | tr -d ’ ’
4.使用tr压缩字符
tr -s SET
将连续相同的字符压缩成一个字符
echo 112233444555666 | tr -s 345
ifconfig | tr -s ’ ’
tr -s SET1 SET2
先替换为SET2再压缩
echo 112233444555666 | tr -s 345 abc
echo 112233444555666 | tr 345 abc | tr -s abc
who | tr -s ‘ ‘ ‘\n’
sort命令
sort命令
默认按每行的第一个字符排序
-n:按整数进行排序
-r:递减排序
指定排序键
指定按哪一列数据进行排序
-k:指定哪一列为排序键
cat tt | sort -n -k4
指定字段分隔符
-t:指定字段分割符(默认是空白)
sort -t: -n -k3 /etc/passwd
unip 命令
uniq命令
删除经过排序后的数据的重复记录
通常和sort连用
sort -n tt | uniq
数据的实例统计
-c:统计重复记录出现的次数(统计相同的有多少个)
cat tt | uniq -c
-u:只显示唯一的行
cat tt | uniq –u
-d:只显示重复的行
cat tt | uniq -d
数据提取
1.cut命令
从文本文件或者文本流中提取文本列
cut -选项 提取范围 文本文件
常见选项
-c:从指定提取范围中提取字符
-f:从指定提取范围中提取字段
提取范围
n:第n项
n-:第n项到行尾
-m:行首到第m项
n,m:第n项和第m项
n-m:第n项到第m项
2.cut -c命令
ls -l | cut -c10
who | cut -c 20-40
cut -c -10 /etc/passwd
3.cut -f命令
-d:指定分隔符默认是Tab
cut -d" " -f2 filename
意思就是我以空格为列的分隔符,提取第二列
cut -d “:” -f 1,7 /etc/passwd
who | cut -d ’ ’ -f1,6
grep数据提取程序
用途:在文件中查找并显示包含指定字符串的行
格式:grep [选项]… 模式 目标文件
-i:查找时忽略大小写
-v:反转查找,输出与模式不相符的行
-w:按整字查找
-n:显示符合模式要求的行号
-r:递归搜索所有文件
-o:只显示指定字符