前言
之前对JVM中堆内存和栈内存都是一直半解,今天有空就好好整理一下,用做学习笔记。
毕竟在简历想写精通jvm,还真的要下一番功夫啊,好啦,话不多说,往下看
组成
包括Java程序在内,任何程序在运行时都是要开辟内存空间的。JVM运行时在内存中开辟一片内存区域,启动时在自己的内存区域中进行更细致的划分,因为虚拟机中每一片内存处理的方式都不同,所以要单独进行管理。实际上在JVM有五种内存管理形式:
- 寄存器;
- 本地方法区;
- 方法区;
- 栈内存(stack);
- 堆内存(heap);
今天重点梳理一下栈内存和堆内存。
在讲解之前我们要了解一个计算机发展至今仍然无法解决的一个矛盾,就是内存的存取速度和数据大小之间的矛盾。当我们对存取速度越快,存储的数据量就越少,反之亦然。栈内存、堆内存其实就是对这种矛盾的一种妥协方式,它们有自己的优点也有自己的缺点:
- 栈内存:存取速度要比堆内存快,仅次于CPU中的寄存器,但栈内存中数据大小和周期时固定的。
- 堆内存:可以动态地分配内存大小,但存取速度慢。
那么栈内存、堆内存到底存储那些数据呢?
- 栈内存中存储都是局部变量,栈中数据生存空间一般在当前scopes内(可以简单理解为{...}括起来的区域)包含所有的基本类型(int、bool、char、float、double、short、long、byte)和引用类型。
- 堆内存存储时类的对象,即类的实体,凡是new建立的都是在堆中,堆中存放的都是实体(对象),实体用于封装数据,而且是封装多个(实体的多个属性)。
另外,在举例前我们需要了解一个概念,什么是变量?变量是内存中分配的区域的名称。换句话说就是变量其实分配地址的别称,我们通过这个变量的名字就可以找到一个指向这个变量所引用的数据的内存指针。我们知道了变量的类型,也就知道了这个指针地址后面连续几个字节内存储的数据。
我们以int[] arr=new int[]{1,2,3}为例,它的内存分配如下:
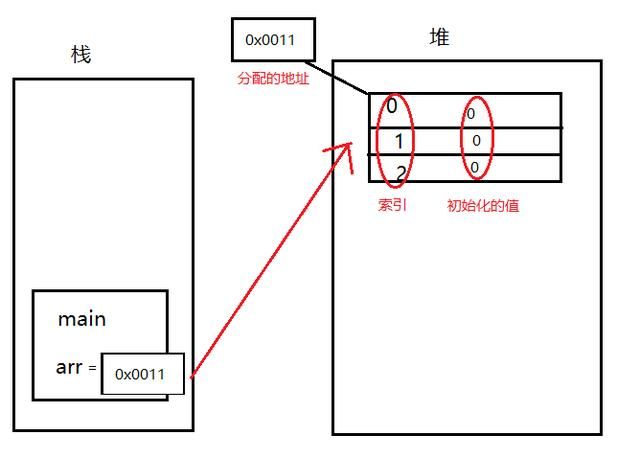
从上图我们可以看到,“变量”是存在栈内存中,“变量所指向的数据”是存在堆内存中的。
下面我们举一个更为复杂的类, 来展示每一部分到底是怎么存储的:
package class1;
class Fruit{
static int x=10;
static BigWaterMelon bigWaterMelon_1=new BigWaterMelon(x);
int y=20;
BigWaterMelon bigWaterMelon_2=new BigWaterMelon(y);
public static void main(String[] args){
final Fruit fruit=new Fruit();
int z=30;
BigWaterMelon bigWaterMelon_3=new BigWaterMelon(z);
new Thread(){
@Override
public void run(){
int k=100;
setWeight(k);
}
void setWeight(int waterMelonWeight){
fruit.bigWaterMelon_2.Weight=waterMelonWeight;
}
}.start();
}
}
class BigWaterMelon{
public int Weight;
public BigWaterMelon(int Weight){
this.Weight=Weight;
}
}内存图如下:
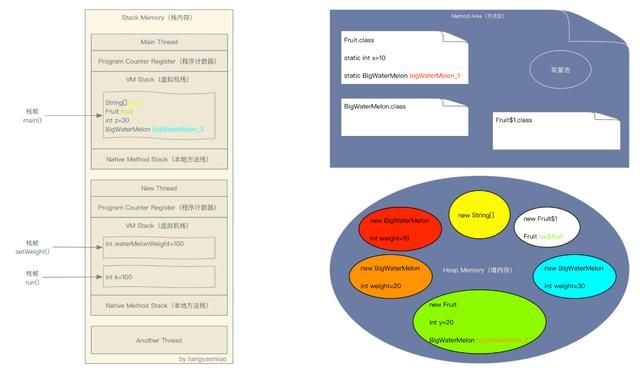
同一种颜色代表变量和对象的引用关系
由于方法区和堆内存的数据都是线程间共享的,所以线程Main Thread,New Thread和Another Thread都可以访问方法区中的静态变量以及访问这个变量所引用的对象的实例变量。
栈内存中每个线程都有自己的虚拟机栈,每一个栈帧之间的数据就是线程独有的了,也就是说线程New Thread中setWeight方法是不能访问线程Main Thread中的局部变量bigWaterMelon_3,但是我们发现setWeight却访问了同为Main Thread局部变量的“fruit”,这是为什么呢?因为“fruit”被声明为final了。
当“fruit”被声明为final后,“fruit”会作为New Thread的构造函数的一个参数传入New Thread,也就是堆内存中Fruit$1对象中的实例变量val$fruit会引用“fruit”引用的对象,从而New Thread可以访问到Main Thread的局部变量“fruit”。
此外,栈内存有先进后出(Last in first Out)的特点,并且栈中数据生存空间一般在当前scopes内(可以简单理解为{...}括起来的区域),也就是说当方法执行结束后,方法内的局部变量在内存中就被清除了。但堆内存不会自动清除,它回不断地申请新的堆内存地址来存储新的数据。不再使用地旧数据只会当作“垃圾数据”,在C++中需要你手动清除,在JVM会自动将这些垃圾数据回收,也就是传说中地GC。
无论是栈内存还是堆内存,内存空间都是有限的。当堆内存没有可用空间时,比如递归没有跳出,JVM会抛出java.lang.StackOverFlowError;当堆内存没有空间时,比如在while循环中不断创建实例,JVM会抛出java.lang.OutOfMemoryError。
问题
为什么变量要放在栈内存中,而变量指向的数据要放在堆内存中呢?
我觉得可以这样理解,其一,变量实际上是地址的别称,本质上就是个地址,数据量不大,而实体数据量很大;其二,变量当不在使用时内存空间被回收,这是也就没有指针指向原来的实体数据,也就是成为了垃圾状态,当JVM再此检查时发现没有指针指向这块空间就会将其收回。
这只是我对于jvm的一些理解,关于jvm,要学习和补充的还有很多,处于篇幅的原因我就没有进行详细的讲解
知识导图
视频
相信视频截图中的那个名字,大家应该都听说过或者听人说过,没错,这些视频就是他的亲授视频,
需要这些视频以及上面百度脑图的老铁,添加小助手:msbxq2020免费获取
关注公众号:Java架构师联盟,回复关键字获取资料
