基于VGG16的垃圾分类系统
目录
1.VGG结构
2.块结构
3.权重参数
3.特点
4.代码实现
4.1 数据集介绍
4.2 代码
4.3 实验结果
1.VGG结构
VGG16 是基于大量真实图像的 ImageNet 图像库预训练的网络。VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
VGG中根据卷积核大小和卷积层数目的不同,可分为A,A-LRN,B,C,D,E共6个配置(ConvNet Configuration),其中以D,E两种配置较为常用,分别称为VGG16和VGG19。下图给出了VGG的六种结构配置:
下图 VGG六种结构配置图:
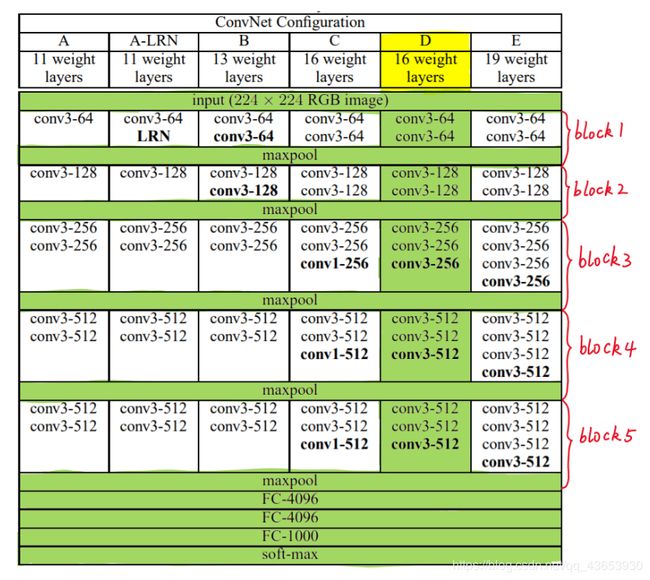
上图中,每一列对应一种结构配置。例如,图中绿色部分即指明了VGG16所采用的结构。
我们针对VGG16进行具体分析发现,VGG16共包含:
- 13个卷积层(Convolutional Layer),分别用conv3-XXX表示
- 3个全连接层(Fully connected Layer),分别用FC-XXXX表示
- 5个池化层(Pool layer),分别用maxpool表示
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是VGG16中16的来源。(池化层不涉及权重,因此不属于权重层,不被计数)。
VGG16整个架构图如下图所示:
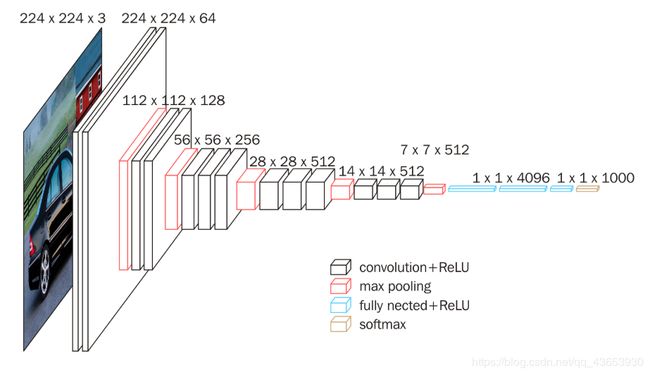
从左至右,一张彩色图片输入到网络,白色框是卷积层,红色是池化,蓝色是全连接层,棕色框是预测层。预测层的作用是将全连接层输出的信息转化为相应的类别概率,而起到分类作用。
可以看到 VGG16 是13个卷积层+3个全连接层叠加而成。
网络开始输入(3,224,224)的图像数据,即一张宽224,高244的彩色RGB图片,同时补了一圈0。接着是卷积层,有64个(3,3)的卷积核,一个卷积核扫完图片,生成一个新的矩阵,64个就生成64 层。接着是补0,接着再来一次卷积。此时图像数据是64*224*224,接着是池化,小矩阵是(2,2)。按照这样池化之后,数据变成了64*112*112,矩阵的宽高由原来的224减半,变成了112。再往下,同理,只不过是卷积核个数依次变成128,256,512,而每次按照这样池化之后,矩阵都要缩小一半。13层卷积和池化之后,数据变成了 512*7*7。
2.块结构
观察上面第一幅图右侧,VGG16的卷积层和池化层可以划分为不同的块(Block),从前到后依次编号为block1-block5。每一个块内包含若干卷积层和一个池化层。例如:block4包含:3个卷积层,conv3-512;1个池化层,maxpool。
并且同一块内,卷积层的通道数是相同的,例如:block2中包含2个卷积层,每个卷积层用conv3-128表示,即卷积核为:3x3x3,通道数都是128;block3中包含3个卷积层,每个卷积层用conv3-256表示,即卷积核为:3x3x3,通道数都是256
下面给出按照块划分的VGG16的结构图,可以结合下图进行理解:

VGG的输入图像是 224x224x3:通道数翻倍,由64依次增加到128,再到256,直至512保持不变,不再翻倍;高和宽变减半,由 224→112→56→28→14→7。
3.权重参数
尽管VGG的结构简单,但是所包含的权重数目却很大,达到了惊人的139,357,544个参数。这些参数包括卷积核权重和全连接层权重。
例如,对于第一层卷积,由于输入图的通道数是3,网络必须学习大小为3x3,通道数为3的的卷积核,这样的卷积核有64个,因此总共有(3x3x3)x64 = 1728个参数。
计算全连接层的权重参数数目的方法为:前一层节点数×本层的节点数前一层节点数×本层的节点数。因此,全连接层的参数分别为:
- 7x7x512x4096 = 1027,645,444
- 4096x4096 = 16,781,321
- 4096x1000 = 4096000
FeiFei Li在CS231的课件中给出了整个网络的全部参数的计算过程(不考虑偏置),如下图所示:

图中蓝色是计算权重参数数量的部分;红色是计算所需存储容量的部分。
VGG16具有如此之大的参数数目,可以预期它具有很高的拟合能力;但同时缺点也很明显,即训练时间过长,调参难度大;需要的存储容量大,不利于部署。例如存储VGG16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
3.特点
VGG16的突出特点是简单,体现在:
(1)卷积层均采用相同的卷积核参数:卷积层均表示为conv3-XXX,其中conv3说明该卷积层采用的卷积核的尺寸(kernel size)是3,即宽(width)和高(height)均为3,3*3是很小的卷积核尺寸,结合其它参数(步幅stride=1,填充方式padding=same),这样就能够使得每一个卷积层(张量)与前一层(张量)保持相同的宽和高。XXX代表卷积层的通道数。
(2)池化层均采用相同的池化核参数:池化层的参数均为2×。
(3)模型是由若干卷积层和池化层堆叠(stack)的方式构成,比较容易形成较深的网络结构(在2014年,16层已经被认为很深了)。
综合上述分析,可以概括VGG的优点为: Small filters, Deeper networks.
4.代码实现
4.1 数据集介绍
该数据集包含了2507 个生活垃圾图片,物品都是物品放在白板上在日光/室内光源下拍摄的,压缩后的尺寸为 512 * 384,垃圾识别分类数据集中包括玻璃 (glass) 、硬纸板 (cardboard) 、金属 (metal) 、纸 (paper) 、塑料 (plastic) 、一般垃圾 (trash) ,共6个类别,如下表3-1所示:
| 序号 |
中文名 |
英文名 |
数据集大小 |
| 1 |
玻璃 |
glass |
497张图片 |
| 2 |
纸 |
paper |
590张图片 |
| 3 |
硬纸板 |
cardboard |
400张图片 |
| 4 |
塑料 |
plastic |
479张图片 |
| 5 |
金属 |
metal |
407张图片 |
| 6 |
一般垃圾 |
trash |
134张图片 |
数据集链接:
链接:https://pan.baidu.com/s/144CJwIe_f3IBqktodFtYSA
提取码:g16r4.2 代码
model_cre.py 数据预处理-构建VGG16模型
# coding=utf-8
from keras.layers import Dropout
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Flatten, Dense
from keras.optimizers import SGD
from keras.applications.vgg16 import VGG16
import matplotlib.pyplot as plt
import time
"""
1.数据预处理
data_path: 数据集路径
return: train, test:处理后的训练集数据、测试集数据
"""
def processing_data(data_path):
# 生成训练集
train_data = ImageDataGenerator(
# 浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度
width_shift_range=0.1,
# 浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
height_shift_range=0.1,
# 浮点数,剪切强度(逆时针方向的剪切变换角度)
shear_range=0.1,
# 随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]
zoom_range=0.1,
# 布尔值,进行随机水平翻转
horizontal_flip=True,
# 对图片的每个像素值均乘上这个放缩因子,把像素值放缩到0和1之间有利于模型的收敛
vertical_flip=True,
# 在 0 和 1 之间浮动。用作验证集的训练数据的比例
rescale=1. / 225,
# 布尔值,进行随机竖直翻转
validation_split=0.1)
# 生成测试集
validation_data = ImageDataGenerator(
rescale=1. / 255,
validation_split=0.1)
# 以文件夹路径为参数,生成经过归一化后的数据,在一个无限循环中无限产生batch数据
train_generator = train_data.flow_from_directory(
# 提供的路径下面需要有子目录
data_path,
# 整数元组 (height, width),默认:(256, 256)。 所有的图像将被调整到的尺寸。
target_size=(150, 150),
# 一批数据的大小
batch_size=16,
# "categorical", "binary", "sparse", "input" 或 None 之一。
# 默认:"categorical",返回one-hot 编码标签。
class_mode='categorical',
# 数据子集 ("training" 或 "validation")
subset='training',
seed=0)
validation_generator = validation_data.flow_from_directory(
data_path,
target_size=(150, 150),
batch_size=16,
class_mode='categorical',
subset='validation',
seed=0)
return train_generator, validation_generator
def model(train_generator, validation_generator, save_model_path, epochs):
start = time.time()
'''
使用keras的已封装的vgg16建立一个模型,构建的模型会将VGG16顶层(全连接层)
去掉只保留其余的网络结构(去掉全连接层,前面都是卷积层)
weights='imagenet' 使用ImageNet上预训练的模型,用ImageNet的参数初始化模型的参数
include_top = False 是否包含最上层的全连接层 表明迁移除顶层以外的其余网络结构到自己的模型中
input_shape 输入进来的数据是150*150 3通道
通过.add()方法一个个的将layer加入模型中
'''
vgg16_model = VGG16(weights='imagenet', include_top=False, input_shape=(150,150,3))
top_model = Sequential()
# Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡
top_model.add(Flatten(input_shape=vgg16_model.output_shape[1:]))
# dense 全连接 activation: 激活函数
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(6, activation='softmax'))
model = Sequential()
model.add(vgg16_model)
model.add(top_model)
# 配置模型学习过程
model.compile(
# 优化器, 主要有Adam、sgd、rmsprop等方式
# SGD 每次更新时对每个样本进行梯度更新, 一次只进行一次更新,就没有冗余,而且比较快,并且可以新增样本
# lr: float >= 0. 学习率, momentum: float >= 0. 参数,用于加速 SGD 在相关方向上前进,并抑制震荡
optimizer=SGD(lr=1e-3, momentum=0.9),
# 损失函数,多分类采用 categorical_crossentropy(亦称作多类的对数损失)
loss='categorical_crossentropy',
# 评价函数 训练和测试期间的模型评估标准 除了损失函数值之外的特定指标, 分类问题一般都是准确率
metrics=['accuracy'])
# 训练
# 返回一个history 记录了训练过程 fit_generator分批次读取 逐个生成数据的batch并进行训练
model.fit_generator(
# generator:生成器函数 一个生成器或 Sequence 对象的实例
generator=train_generator,
# epochs: 整数,数据的迭代总轮数。
epochs=epochs,
# 每轮步数 一个epoch包含的步数,通常应该等于你的数据集的样本数量除以批量大小。
steps_per_epoch=2259 // 16,
# 验证集
validation_data=validation_generator,
# 在验证集上,一个epoch包含的步数,通常应该等于你的数据集的样本数量除以批量大小。
validation_steps=248 // 16,
)
model.save(save_model_path)
end = time.time()
print("训练完毕,模型已保存!总耗时:%d 秒" % (end - start))
return model
epochs = 20
# 数据集路径
data_path = 'dataset/'
# 保存模型路径和名称
save_model_path = 'results/model_20.h5'
# 获取数据
train_generator, validation_generator = processing_data(data_path)
# 创建、训练和保存模型
model(train_generator, validation_generator, save_model_path, epochs)
model_evaluate.py 模型评估
# coding=utf-8
from keras.models import load_model
from model_cret import processing_data
import matplotlib.pyplot as plt
# 评估模型
def evaluate_mode(validation_generator):
# 加载模型
model = load_model('results/model_20.h5')
history = model.fit_generator(
# 一个生成器或 Sequence 对象的实例
generator=train_generator,
# epochs: 整数,数据的迭代总轮数。
epochs=20,
# 一个epoch包含的步数,通常应该等于你的数据集的样本数量除以批量大小。
steps_per_epoch=2259 // 16,
# 验证集
validation_data=validation_generator,
# 在验证集上,一个epoch包含的步数,通常应该等于你的数据集的样本数量除以批量大小。
validation_steps=248 // 16,
)
plt.figure()
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig('model_accuracy.png')
plt.figure()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig('model_loss.png')
plt.show()
# 获取验证集的 loss 和 accuracy
loss, accuracy = model.evaluate_generator(validation_generator)
print("模型评估:")
print("Loss: %.2f, Accuracy: %.2f%%" % (loss, accuracy * 100))
print(model.summary())
# 数据集路径
data_path = 'dataset/'
train_generator, validation_generator = processing_data(data_path)
evaluate_mode(validation_generator)model_pred.py 预测
# coding=utf-8
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import cv2
"""
加载模型和模型预测
主要步骤:
1.加载模型
2.图片处理
3.用加载的模型预测图片的类别
:param img: PIL.Image 对象
:return: string, 模型识别图片的类别,
共 'cardboard','glass','metal','paper','plastic','trash' 6 个类别
"""
def predict(img_path):
# 把图片转换成为numpy数组
img = image.load_img(img_path, target_size=(150, 150))
img = image.img_to_array(img)
# 加载模型,加载请注意 model_path 是相对路径, 与当前文件同级。
# 如果你的模型是在 results 文件夹下的 dnn.h5 模型,则 model_path = 'results/dnn.h5'
model_path = 'results/model_20.h5'
# 加载模型
model = load_model(model_path)
# expand_dims的作用是把img.shape转换成(1, img.shape[0], img.shape[1], img.shape[2])
# 给函数增加维度
x = np.expand_dims(img, axis=0)
# 模型预测
y = model.predict(x)
# 获取labels
labels = {0: 'cardboard', 1: 'glass', 2: 'metal', 3: 'paper', 4: 'plastic', 5: 'trash'}
predict = labels[np.argmax(y)]
# 返回图片的类别
return predict
img_path = 'testImg/cardboard2.jpg'
frame = cv2.imread(img_path)
# 定义字体
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame, predict(img_path), (10, 140), font, 3, (255, 0, 0), 2, cv2.LINE_AA)
cv2.imwrite('results/pred.png', frame)
cv2.imshow('img', frame)
cv2.waitKey(0)
cv2.destroyAllWindows()model_ui.py 可视化界面
# coding=utf-8
import tkinter as tk
from tkinter import *
from tkinter import ttk
from PIL import Image, ImageTk
# 创建窗口 设定大小并命名
window = tk.Tk()
window.title('垃圾分类')
window.geometry('1050x500')
global img_png # 定义全局变量 图像的
var = tk.StringVar() # 这时文字变量储存器
mainframe = ttk.Frame(window, padding="5 4 12 12")
mainframe.grid(column=0, row=0, sticky=(N, W, E, S))
mainframe.columnconfigure(0, weight=1)
mainframe.rowconfigure(0, weight=1)
def openImg():
global img_png
var.set('已打开')
Img = Image.open('testImg/cardboard2.jpg')
img_png = ImageTk.PhotoImage(Img)
label_Img2 = tk.Label(image=img_png).grid(column=2, row=2, sticky=W)
num = 1
def change(): #更新图片操作
global num
var.set('已预测')
num=num+1
if num%3==0:
url1="results/pred.png"
pil_image = Image.open(url1)
img= ImageTk.PhotoImage(pil_image)
label_img.configure(image = img)
window.update_idletasks() #更新图片,必须update
# row = 1
# epochs = StringVar()
# ttk.Label(mainframe, text="epochs:").grid(column=1, row=1, sticky=W)
# addr_entry = ttk.Entry(mainframe, width=7, textvariable=epochs)
# addr_entry.grid(column=2, row=1, sticky=(W, E))
#
# ttk.Button(mainframe, text="Train").grid(column=4, row=1, sticky=W)
# row = 2
ttk.Button(mainframe, text="打开", command=openImg).grid(column=1, row=2, sticky=W)
ttk.Button(mainframe, text="预测", command=change).grid(column=3, row=2, sticky=W)
# row = 3 创建文本窗口,显示当前操作状态
ttk.Label(mainframe, text="状态").grid(column=1, row=3, sticky=W)
ttk.Label(mainframe, textvariable=var).grid(column=3, row=3, sticky=W)
url = "testImg/logo.jpg"
pil_image = Image.open(url)
img= ImageTk.PhotoImage(pil_image)
label_img = ttk.Label(window, image = img ,compound=CENTER)
label_img.grid(column=0, row=2, sticky=W)
# 运行整体窗口
window.mainloop()
4.3 实验结果
本实验的GUI设计采用TK实现,主界面包含选择要预测的图片和预测两个按钮,具体页面设计如下:


