大数据生态组件——Hive安装及配置
Hive安装与配置
- Hive简介
- Hive的安装与配置(一)
- Hive的启动
- hive的元数据库
- 安装配置MySQL
- MySQL的开机自启操作
- 配置hive(二)
- 配置hive-env.sh
- 配置hive-site.xml
- 上传mysql-connector-java-5.1.38-bin.jar到$HIVE_HOME/lib
- 观察此时的Hive的元数据库hive_metastore_db
- 重新给整个Hive目录授权(建议再做一遍授权操作)
- 初始化MySQL数据库
- hive-shell的基本操作命令
以下安装配置均是在虚拟机环境下进行的(我使用的是centos)
Hive简介
- HIve是一个基于hadoop的开源数据仓库工具,用于存储和处理海量的(半)结构化数据
- Hive将海量的数据存储于hadoop文件系统,而不是数据库,但提供了 一套类数据库的数据存储和处理机制,并采用HQL(类SQL)语言对这些数据进行自动化管理和处理,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制
- Hive的本质是将SQL转换为SQL转换为MapReduce程序
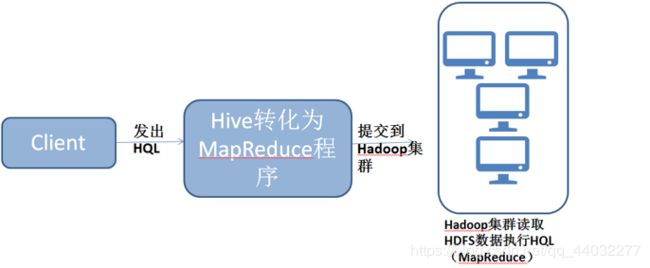
- Hive诞生于Facebook的日志分析需求,面对海量的结构化数据,Hive以较低的成本完成了以往需要大规模数据库才能完成的任务,并且学习门槛相对较低,应用开发灵活而高效。
Hive的安装与配置(一)
Hive不存在集群,Hive不用配置是伪分布式还是完全分布式模式,它只是一个客户端工具,可以运行在集群的任意一个节点上
- 下载解压
apache-hive-2.3.3-bin.tar.gz到/usr/local - 重命名文件夹为
hive - 修改所属组和所属用户(root环境下不需要这一步)
- 配置环境变量
~/.bashrc
[hadoop@s0 ~]$ sudo tar -zxvf downloads/apache-hive-2.3.3-bin.tar.gz -C /usr/local/
[hadoop@s0 ~]$ cd /usr/local/
[hadoop@s0 local]$ sudo mv apache-hive-2.3.3-bin/ hive
[hadoop@s0 local]$ sudo chown -R hadoop:hadoop hive
[hadoop@s0 ~]$ vi .bashrc
# 在.bashrc 中输入以下内容(前三行不是本次需要输入的内容):
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export SPARK_HOME=/usr/local/spark
export HIVE_HOME=/usr/local/hive #输入此行
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$SPARK_HOME/bin:$HIVE_HOME/bin:$PATH
Hive的启动
- 启动hadoop集群(前面有博客介绍过,这里就不再介绍安装了)
[hadoop@s0 ~]$ start-all.sh # Yarn必须要启动
启动Hive之前要先启动Hadoop集群,不能只启动HDFS文件系统,Yarn也需要启动,因为以后执行Hive语句的时候会转化为MapReduce任务
- 启动hive
[hadoop@s0 ~]$ hive
启动时会报错:不能建立元数据库的错误

hive的元数据库
-
hive中的元数据(Metastore)
-
元数据包括表的名字、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等。
-
Hive 将元数据存储在关系型数据库中,目前只支持MySQL、Derby;原始的Hive默认使用Derby数据库
-
请注意区分,Hive存储的海量数据放在HDFS中,但是Hive自己的元数据放在关系型数据库中
-
元数据库默认使用内嵌的Derby数据库作为存储引擎;Derby引擎的缺点:一次只能打开一个会话
-
需要更换Hive的数据库为MySQL,使用MySQL作为外置存储引擎,支持多用户同时访问。
-
所以先要安装一下MySQL(本地方式),即MySQL数据库同hive安装在一个系统中。
安装配置MySQL
- 观察是否安装过MySQL
[hadoop@s0 ~]$ rpm -qa | grep -i mysql
mysql-libs-5.1.73-3.el6_5.x86_64
已存在mysql-libs-5.1.73-3.el6_5.x86_64的库(这是linux自带的)
- 在线安装MySQL
[hadoop@s0 ~]$ sudo yum install mysql-server
- 观察MySQL版本
[hadoop@s0 ~]$ mysql -V #是大写的V
mysql Ver 14.14 Distrib 5.1.73, for redhat-linux-gnu (x86_64) using readline 5.1
- 观察MySQL是否正常运行
[hadoop@s0 ~]$ netstat -an | grep 3306
# 结果为空 证明没有运行
- 启动MySQL
[hadoop@s0 ~]$ sudo service mysqld start # service mysqld start/stop/restart
[sudo] password for hadoop:
Starting mysqld: [ OK ]
[hadoop@s0 ~]$ netstat -an | grep 3306
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN
- 进入和退出MySQL
[hadoop@s0 ~]$ mysql -uroot #此root与Linux的root用户毫无关系;u和root之间可以有空格,也可以没有
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.1.73 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql安装后会创建一个默认用户root,与linux的root用户无关
root用户默认没有密码
mysql> exit; #MySQL数据库的命令输入时最后也要加分号
Bye
- 设置root用户密码
[hadoop@s0 ~]$ mysqladmin -uroot password 123456
- 以带密码的root用户身份登录
[hadoop@s0 ~]# mysql -uroot -p
Enter password: #此处输入密码123456
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 23
Server version: 5.6.40 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
- 添加远程登录的用户hive及权限
mysql>GRANT all ON *.* TO hiver@'%' IDENTIFIED BY '123456';// *.*:所有库下的所有表 %:任何IP地址或主机都可以连接,此处的hiver是一个远程访问MySQL数据库的用户
mysql>GRANT all ON *.* TO hiver@'s0' IDENTIFIED BY '123456';
mysql> GRANT all ON *.* TO hiver@'localhost' IDENTIFIED BY '123456';
mysql>FLUSH PRIVILEGES; //让前3条命令生效
#可以使用下述命令删除用户及权限:
mysql >drop user hiver@'%';
mysql> drop user hiver@'s0';
mysql> drop user hiver@'localhost';
- 创建hive的元数据库名称为hive_metastore_db
mysql> create database hive_metastore_db;
Query OK, 1 row affected (0.00 sec)
#此数据库用于存放Hive的metastore元数据,即Hive的元数据存放在MySQL数据库中
- 显示数据库
mysql> show databases;
MySQL的开机自启操作
- 设置开机自启
[hadoop@s0 ~]$ sudo chkconfig mysqld on
[hadoop@s0 ~]$ chkconfig --list | grep mysql
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
配置hive(二)
配置hive-env.sh
- 将hive-env.sh.template复制一份为hive-env.sh
- 配置hive-env.sh

注意查看自己文件的位置,将自己的位置写上去
配置hive-site.xml
- 将/usr/local/hive/conf/hive-default.xml.template复制一份并重命名为hive-site.xml
[hadoop@s0 ~]$ cd /usr/local/hive/conf/
[hadoop@s0 conf]$ cp hive-default.xml.template hive-site.xml #注意不是hive-default.xml
[hadoop@s0 conf]$ sudo vi hive-site.xml #虽然可以不用sudo,加上可以保证格式容易控制
- 原始的hive-default.xml.template中的配置

javax.jdo.option.ConnectionURL:数据库链接字符串。

javax.jdo.option.ConnectionDriverName:连接数据库的驱动包。

javax.jdo.option.ConnectionUserName:数据库用户名(默认是APP)。

javax.jdo.option.ConnectionPassword:连接数据库的密码。
修改为对应以下内容:
"1.0" encoding="UTF-8" standalone="no"?>
-stylesheet type="text/xsl" href="configuration.xsl"?>
javax.jdo.option.ConnectionURL</name>
jdbc:mysql://s0:3306/hive_metastore_db</value>
</property>
javax.jdo.option.ConnectionDriverName</name>
com.mysql.jdbc.Driver</value>
</property>
javax.jdo.option.ConnectionUserName</name>
hiver</value>
</property>
javax.jdo.option.ConnectionPassword</name>
123456</value>
</property>
</configuration>
上传mysql-connector-java-5.1.38-bin.jar到$HIVE_HOME/lib
[hadoop@s0 downloads]$ sudo cp mysql-connector-java-5.1.38-bin.jar /usr/local/hive/lib/
观察此时的Hive的元数据库hive_metastore_db
mysql> use hive_metastore_db;
Database changed
mysql> show tables;
Empty set (0.00 sec)
此时Hive的元数据库hive_metastore_db的元数据库中没有表
重新给整个Hive目录授权(建议再做一遍授权操作)
[hadoop@s0 local]$ sudo chown -R hadoop:hadoop hive
初始化MySQL数据库
[hadoop@s0 ~]$ cd /usr/local/hive/bin/
[hadoop@s0 bin]$ schematool -dbType mysql -initSchema
- 观察此时的Hive的元数据库hive_metastore_db
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hive_metastore_db |
| mysql |
| test |
+--------------------+
4 rows in set (0.00 sec)
mysql> use hive_metastore_db;
Database changed
mysql> show tables;
+-----------------------------+
| Tables_in_hive_metastore_db |
+-----------------------------+
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| DATABASE_PARAMS |
| DBS |
……
29 rows in set (0.00 sec)
hive-shell的基本操作命令
- 启动hadoop集群
- 启动hive
hive> show databases; #最后的分号必须有,为英文分号,风格与MySQL的命令类似
OK
default
Time taken: 2.832 seconds, Fetched: 1 row(s)
可以看到只有一个默认的数据库default
hive> show tables;
OK
Time taken: 1.23 seconds
hive> create database student; #创建数据库student
hive> create database student; #再次创建数据库student会报错
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database student already exists
hive> create database if not exists student;
OK
Time taken: 0.048 seconds
hive> describe database student;
OK
student hdfs://s0:9000/user/hive/warehouse/student.db hadoop USER
Time taken: 0.073 seconds, Fetched: 1 row(s)
hive> use student; #创建好的数据库要被使用,必须使用use命令
hive> create table stu(id int, name string); #在数据库student中创建表stu
hive> show tables; #注意table是复数形式
OK
stu
Time taken: 0.101 seconds, Fetched: 1 row(s)
#显示表的结构
hive> desc stu;
OK
id int
nam string
Time taken: 0.263 seconds, Fetched: 1 row(s)
#插入一条记录,会启动MR作业
hive> insert into stu values(1,'zhangsan');
hive> insert into stu values(2,'lisi');
#只带*号的返回全部字段的查询不启动MR作业
hive> select * from stu;
OK
1 zhangsan
2 lisi
Time taken: 0.191 seconds, Fetched: 2 row(s)
#使用了排序子句 会启动MR作业
hive> select * from stu order by id desc;
hive> drop table stu; #删除表
hive> drop database student; #在Hive中删除数据库,必须要先删除数据库中的表才能删除数据库
hive> quit;