caffe:windows下训练模型
一、利用mnist训练集进行训练
(1) 将mnist数据集lmdb格式存储于examples\mnist目录下
(2) 计算出均值文件:mean.binaryproto
产生均值文件的方法是利用解决方案中的compute_image_mean.exe,位于目录\caffe-master\Build\x64\Release下。回到caffe-master根目录下创建一个mnist_mean.txt,写入如下内容:
Build\x64\Release\compute_image_mean.exe examples\mnist\mnist_train_lmdb mean.binaryproto
pause
接着为了使用均值文件需要稍微修改下层的定义。所以打开\examples\mnist\lenet_train_test.prototxt,做如下修改:
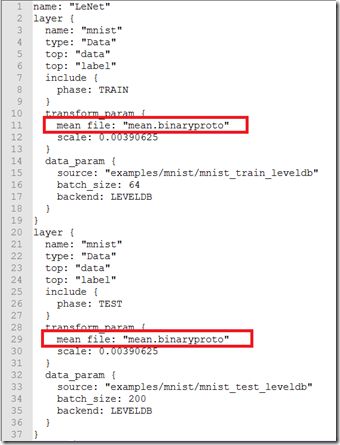
到此为止,均值文件的预处理部分处理完毕,下面就可以进行测试了。
(3) 在正式运行前还有几个文件中需要进行改动,首先用VS打开\examples\mnist目录下的lenet_solver.prototxt,将最后一行改成CPU:
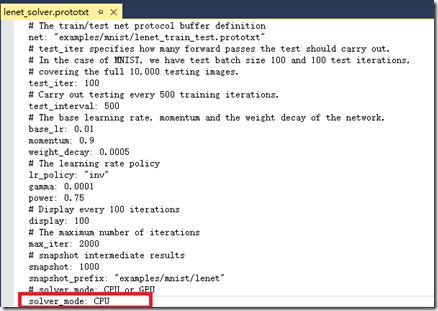
可以看到,这个文件是对网络训练参数进行指定:max_iter指定了最大迭代次数,snapshot是输出中间结果。上图中的参数已经修改过,初始的max_iter和snapshot是10000和5000。
接着再用VS打开\examples\mnist目录下的lenet_train_test.prototxt,以正确指定训练集和测试集。
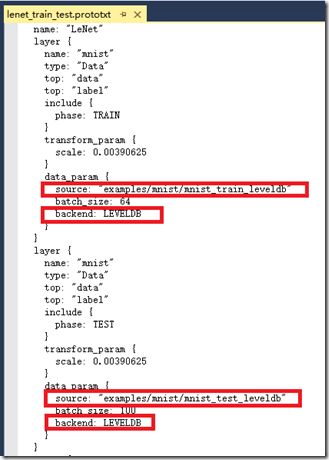
(实际默认的是lmdb格式,则不需要修改)这里额外介绍下caffe-windows采用的LeNet-5模型,也就是上图中layer的定义方式。由于之后自己写代码实现模型时肯定需要对LeNet-5模型有了解,所以提供该模型的原始资料以供参考。
http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
其实平时看些别人论文中提供的代码,上述两个文件也算是论文和代码的核心所在。
#网络模型描述文件
#也可以用train_net和test_net来对训练模型和测试模型分别设定
#train_net: "xxxxxxxxxx"
#test_net: "xxxxxxxxxx"
net: "E:/Caffe-windows/caffe-windows/examples/mnist/lenet_train_test.prototxt"
#这个参数要跟test_layer结合起来考虑,在test_layer中一个batch是100,而总共的测试图片是10000张
#所以这个参数就是10000/100=100
test_iter: 100
#每训练500次进行一次测试
test_interval: 500
#学习率
base_lr: 0.01
#动力
momentum: 0.9
#type:SGD #优化算法的选择。这一行可以省略,因为默认值就是SGD,Caffe中一共有6中优化算法可以选择
#Stochastic Gradient Descent (type: "SGD"), 在Caffe中SGD其实应该是Momentum
#AdaDelta (type: "AdaDelta"),
#Adaptive Gradient (type: "AdaGrad"),
#Adam (type: "Adam"),
#Nesterov’s Accelerated Gradient (type: "Nesterov")
#RMSprop (type: "RMSProp")
#权重衰减项,其实也就是正则化项。作用是防止过拟合
weight_decay: 0.0005
#学习率调整策略
#如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power),其中iter表示当前的迭代次数
lr_policy: "inv"
gamma: 0.0001
power: 0.75
#每训练100次屏幕上显示一次,如果设置为0则不显示
display: 100
#最大迭代次数
max_iter: 2000
#快照。可以把训练的model和solver的状态进行保存。每迭代5000次保存一次,如果设置为0则不保存
snapshot: 5000
snapshot_prefix: "E:/Caffe-windows/caffe-windows/examples/mnist/models"
#选择运行模式
solver_mode: CPUname: "LeNet" #网络的名字"LeNet"
layer { #定义一个层
name: "mnist" #层的名字"mnist"
type: "Data" #层的类型"Data",表明数据来源于LevelDB或LMDB。另外数据的来源还可能是来自内存,HDF5,图片等
top: "data" #输出data
top: "label" #输出label
include {
phase: TRAIN #该层只在TRAIN训练的时候有效
}
transform_param { #数据的预处理
scale: 0.00390625 #1/256,将输入的数据0-255归一化到0-1之间
}
data_param {
source: "E:/Caffe-windows/caffe-windows/examples/mnist/lmdb/train_lmdb" #数据来源
batch_size: 64 #每个批次处理64张图片
backend: LMDB #数据格式LMDB
}
}
layer { #定义一个层
name: "mnist" #层的名字"mnist"
type: "Data" #层的类型"Data",表明数据来源于LevelDB或LMDB
top: "data" #输出dada
top: "label" #输出label
include {
phase: TEST #该层只在TEST测试的时候有效
}
transform_param { #数据的预处理
scale: 0.00390625 #1/256,将输入的数据0-255归一化到0-1之间
}
data_param {
source: "E:/Caffe-windows/caffe-windows/examples/mnist/lmdb/test_lmdb" #数据来源
batch_size: 100 #每个批次处理100张图片
backend: LMDB #数据格式LMDB
}
}
layer { #定义一个层
name: "conv1" #层的名字"conv1"
type: "Convolution" #层的类型"Convolution"
bottom: "data" #输入data
top: "conv1" #输出conv1
param { #这个是权值的学习率
lr_mult: 1 #学习率系数。最终的学习率是这个学习率系数lr_mult乘以solver.prototxt里面的base_lr
}
param { #这个是偏置的学习率
lr_mult: 2 #学习率系数。最终的学习率是这个学习率系数lr_mult乘以solver.prototxt里面的base_lr
}
convolution_param {
num_output: 20 #卷积核的个数为20,或者表示输出特征平面的个数为20
kernel_size: 5 #卷积核的大小5*5。如果卷积核长和宽不等,则需要用kernel_h和kernel_w分别设置
stride: 1 #步长为1。也可以用stride_h和stride_w来设置
weight_filler { #权值初始化
type: "xavier" #使用"Xavier"算法,也可以设置为"gaussian"
}
bias_filler { #偏置初始化
type: "constant" #一般设置为"constant",取值为0
}
}
}
layer { #定义一个层
name: "pool1" #层的名字"pool1"
type: "Pooling" #层的类型"Pooling"
bottom: "conv1" #输入conv1
top: "pool1" #输出pool1
pooling_param {
pool: MAX #池化方法。常用的方法有MAX,AVE或STOCHASTIC
kernel_size: 2 #池化核的大小2*2。如果池化核长和宽不等,则需要用kernel_h和kernel_w分别设置
stride: 2 #池化的步长。也可以用stride_h和stride_w来设置
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50 #卷积核的个数为50,或者表示输出特征平面的个数为50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer { #定义一个层
name: "ip1" #层的名字"ip1"
type: "InnerProduct" #层的类型"InnerProduct",全连接层
bottom: "pool2" #输入pool2
top: "ip1" #输出ip1
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500 #500个神经元
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer { #定义一个层
name: "relu1" #层的名字"relu1"
type: "ReLU" #层的类型"ReLU",激活函数
bottom: "ip1" #输入ip1
top: "ip1" #输出ip1
}
layer { #定义一个层
name: "ip2" #层的名字"ip2"
type: "InnerProduct" #层的类型"InnerProduct",全连接层
bottom: "ip1" #输入ip1
top: "ip2" #输出ip2
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10 #10个输出,代表10个分类
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer { #定义一个层
name: "accuracy" #层的名字"accuracy"
type: "Accuracy" #层的类型"Accuracy",用来判断准确率
bottom: "ip2" #层的输入ip2
bottom: "label" #层的输入label
top: "accuracy" #层的输出accuracy
include {
phase: TEST #该层只在TEST测试的时候有效
}
}
layer { #定义一个层
name: "loss" #层的名字"loss"
type: "SoftmaxWithLoss" #层的类型"SoftmaxWithLoss",输出loss值
bottom: "ip2" #层的输入ip2
bottom: "label" #层的输入label
top: "loss" #层的输出loss
}(4) 完成上述工作后就可以编写bat脚本进行正式训练了。回到caffe-master的根目录下新建一个run.txt并写入以下内容:
![]()
将后缀名改成bat后双击运行,不出意料,应该会出现类似如下的训练过程:
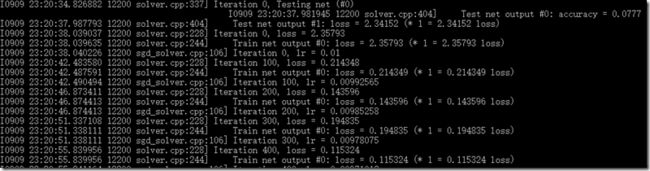
下面就对运行的结果进行一些简单的解释:
最前面的部分是打印各种信息(包括是用CPU还是GPU、训练参数、网络参数等等),类似下图内容:
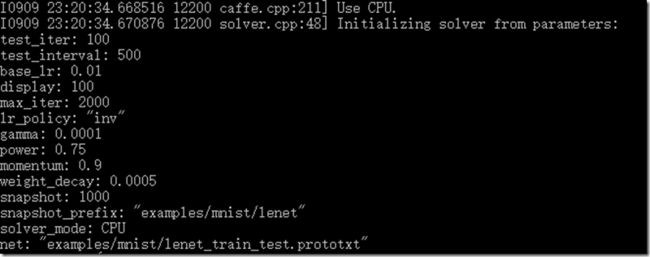
之后即为和下图一样的正式训练过程,可以看到打印信息的格式也是有规律的:

左侧为caffe采用的GLOG库内方法打印的信息,这个库主要起记录日志的功能,方便出现问题时查找根源,具体格式为:
[日期] [时间] [进程号] [文件名] [行号]
往右即为当前迭代次数以及损失值(训练过程不输出准确率accuracy)。
当迭代次数达到lenet_solver.prototxt定义的max_iter时,就可以认为训练结束了。并且最终会在目录\examples\mnist下产生训练出的模型(文件后缀名为caffemodel和solverstate),如下图所示:

分别是训练至一半和训练最终完成后的模型。接下来可以用这模型对mnist的测试集和自己手写的数字进行测试。
接下来就可以利用模型进行测试了。关于测试方法按照上篇教程还是选择bat文件,当然python、matlab更为方便,比如可以迅速把识别错误的图片显示出来。
二、利用mnist测试集进行测试
这部分比较简单,因为之前生成的Caffe.exe就可以直接用来进行测试。同样地在caffe-master目录下新建mnist_test.txt,并写入如下内容(其中的间断处都为一个空格)。
Build\x64\Release\caffe.exe test --model=examples\mnist\lenet_train_test.prototxt -weights=examples\mnist\lenet_iter_10000.caffemodel
pause
意思也显而易见,首先指定为测试模式,随后指定模型和训练出来的参数。
将后缀名改为bat后双击运行,结果如下所示:
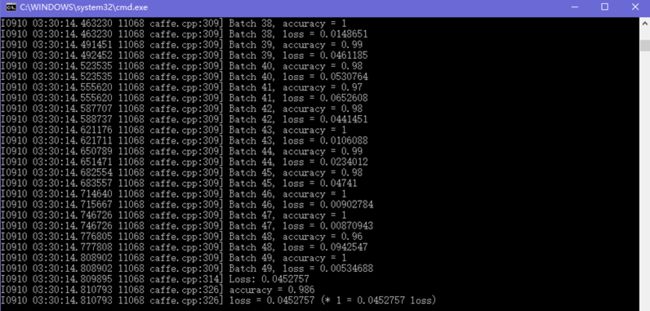
左侧的内容依旧是GLOG的记录日志,右侧中的Batch需要和网络参数初始中的batch_size一起理解。每个Batch中包含了batch_size张测试图片,所以每个Batch的准确率是对这batch_size张测试图片整体而言的。而不是像我最初一样先入为主地以为准确率应该是对每张测试图片而言,故只有0和1两种情况。
这边个人也有个小问题,Batch之所以为0-49共50个是由caffe.cpp中一个叫做FLAGS_iterations的变量指定的。
这个准确率不能说特别好,因为我有空也尝试过Tensorflow,Tensorflow官方文档中的一个多层卷积网络对mnist测试集的准确率为99.2%左右。不过到此为止我们已经完成了mnist测试集在caffe上的运行和测试。
三、利用自己的手写数字进行测试
主要参考了http://blog.csdn.net/zb1165048017/article/details/52217772这篇文章,不过还是有些细节需要更改。
(1)首先可以按照上面网址教程中的第六和第七步在\examples\mnist目录下生成手写的一个28*28像素数字的bmp文件和一个标签文件label.txt。比如我手写的数字如下图所示:

这里需要注意的是上述教程中的matlab代码最后一句需要更改。例如我已经将matlab的工作目录设为\caffe-windows\examples\mnist,就可以直接输入(test1为我的手写数字文件名):
![]()
(2)之后就可以调用之前生成的classification.exe进行分类。同样的在caffe-windows目录下新建test_personaldig.txt并写入如下内容:

中间的三行其实是每个加一个空格后跟在examples\mnist\lenet.prototxt的后面,这里为了显示地更加清楚而进行了换行。更改后缀为bat后就可以双击运行,会出现类似下面的内容:

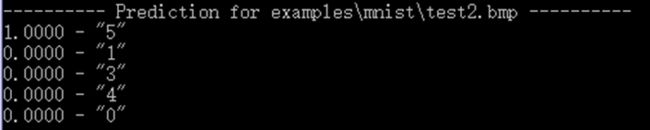
可见分类结果正确。让我们再来测试一个下图写得一个比较飘逸的5。

分类结果还是正确的。
主要参考:
1. http://www.cnblogs.com/yixuan-xu/p/5858595.html
2. https://www.cnblogs.com/yixuan-xu/p/5862657.html
3. http://blog.sina.com.cn/s/blog_15927bda90102x5nk.html
3. http://blog.sina.com.cn/s/blog_15927bda90102x5nj.html