Go复习笔记3-并发(goroutine&channel)
Go并发机制(goroutine&channel)
- 理论基础:Communication Sequential Process(CSP)
- Don`t communicate by sharing memory;share memory by communicating
goroutine
协程Coroutine:
- 轻量级“线程”
- 非抢占式多任务处理,由协程主动交出控制权
- 编译器/解释器/虚拟机层面的多任务
- 多个协程可能在一个或多个线程上运行
子程序是协程的一个特例
协程非抢占式:
package main
import (
"fmt"
"runtime"
"time"
)
func main(){
var a[10]int
for i:=0;i<10;i++{
go func(i int){
//非抢占式,一个goroutine不交出控制权,
//其他goroutine就无法执行,阻死在第一个协程上
for{
a[i]++
}
}(i)
}
time.Sleep(time.Millisecond)
fmt.Println(a)
}
主动让出控制权,使其他协程运行:
package main
import (
"fmt"
"runtime"
"time"
)
func main(){
var a[10]int
for i:=0;i<10;i++{
go func(i int){
for{
a[i]++
//手动让出控制权,让其他协程也有机会运行
runtime.Gosched()//手动让出控制权
}
}(i)
}
time.Sleep(time.Millisecond)
fmt.Println(a)
}
协程引用循环变量,形成闭包:
package main
import (
"fmt"
"runtime"
"time"
)
func main(){
var a[10]int
for i:=0;i<10;i++{
go func(){
for{
//会出错,这里是一个闭包,引用自由变量i,
// 外部i最后更新到10,已经超过数组便捷
//用go run . -race
a[i]++
runtime.Gosched()//手动让出控制权
}
}()
}
time.Sleep(time.Millisecond)
fmt.Println(a)
}
可以通过-race参数,查看数据的访问冲突:
liudeMacBook-Pro:goroutine liu$ go run -race goroutine.go
==================
WARNING: DATA RACE
Read at 0x00c00009a008 by goroutine 6:
main.main.func1()
/Users/liu/work/go/src/studygo/google_pg_go/goroutine/goroutine.go:44 +0x70
Previous write at 0x00c00009a008 by main goroutine:
main.main()
/Users/liu/work/go/src/studygo/google_pg_go/goroutine/goroutine.go:38 +0x11b
Goroutine 6 (running) created at:
main.main()
/Users/liu/work/go/src/studygo/google_pg_go/goroutine/goroutine.go:39 +0xf1
我们通过该回参数的形式,不使用闭包,上述问题解决,但仍存在数据冲突:
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
var a[10]int
for i:=0;i<10;i++{
go func(i int){
//非抢占式,一个goroutine不交出控制权,
//其他goroutine就无法执行
for{
a[i]++
runtime.Gosched()//手动让出控制权
}
}(i)
}
time.Sleep(time.Millisecond)
fmt.Println(a)
}
通过-race发现仍有数据冲突,其实是多个协程a[i]++写,和主协程的fmt.Println(a)读之间的数据访问冲突,这个就需要我们用channel来解决,也正是go推荐的用通信替代共享内存的同步方式。
liudeMacBook-Pro:goroutine liu$ go run -race goroutine.go
==================
WARNING: DATA RACE
Read at 0x00c0000a2000 by main goroutine:
main.main()
/Users/liu/work/go/src/studygo/google_pg_go/goroutine/goroutine.go:65 +0xfb
Previous write at 0x00c0000a2000 by goroutine 6:
main.main.func1()
/Users/liu/work/go/src/studygo/google_pg_go/goroutine/goroutine.go:59 +0x68
Goroutine 6 (running) created at:
main.main()
/Users/liu/work/go/src/studygo/google_pg_go/goroutine/goroutine.go:55 +0xc3
==================
[3434 2777 2389 449 487 491 510 499 439 529]
Found 1 data race(s)
exit status 66
子程序是协程的一个特例:
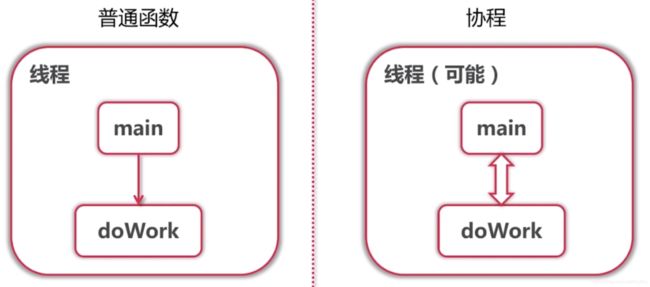
其他语言中的协程:
- C++: Boost.Coroutine
- Java: 不支持
- Python中的协程:
- 使用yield关键字实现协程
2)Python3.5引入了async def对协程原生支持
- 使用yield关键字实现协程
goroutine:
- 任何函数只需加上go就能送给调度器运行
- 不需要在定义时区分是否是异步函数
- 调度器在合适的点进行切换
- 使用-race来检测数据访问冲突
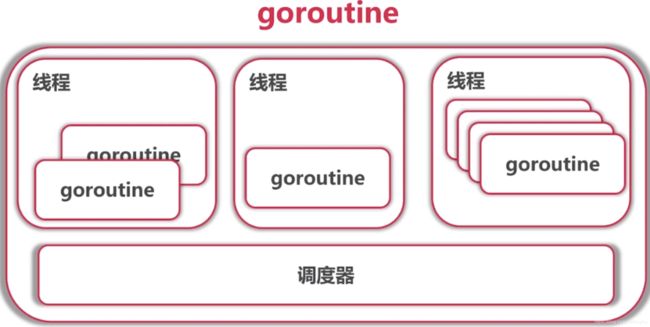
goroutine可能的切换点:
- I/O,select
- channel
- 等待锁
- 函数调用(有时)
- runtime.Gosched()
- 以上只是参考,不能保证切换,不能保证在其他地方不切换
go协程会映射到几个线程上,可通过top查看,这里映射了7个线程,最多4个活动的线程(本机是四核cpu)。
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
var a[10]int
for i:=0;i<10;i++{
go func(i int){
//非抢占式,一个goroutine不交出控制权,
//其他goroutine就无法执行
a[i]++
runtime.Gosched()//手动让出控制权
}(i)
}
time.Sleep(time.Minute)
}
PID COMMAND %CPU TIME #TH #WQ #PORT MEM PURG CMPRS PGRP PPID STATE BOOSTS %CPU_ME %CPU_OTHRS UID FAULTS COW
9905 top 4.4 00:01.52 1/1 0 25 5268K 0B 0B 9905 9337 running *0[1] 0.00000 0.00000 0 9652+ 101
9902 goroutine 323.4 01:15.57 6/4 0 15 732K 0B 0B 9891 9891 running *0[1] 0.00000 0.00000 501 523 42
9891 go 0.0 00:00.14 11 0 20 8228K 0B 0B 9891 5481 sleeping *0[1] 0.00000 0.00000 501 6065 703
...
channel
Go并发,可以启动很多goroutine,而goroutine之间的双向通道就是channel。channel也是go的一等公民,可以用作参数、返回值等。关于Go的并发机制,这里主要涉及如下内容:
- 无缓冲/带缓冲channel
- range遍历channel
- 理论基础:Communication Sequential Process(CSP)
- Don`t communicate by sharing memory;share memory by communicating(不要通过共享内存来通信,通过通信来共享内存)
这里是一个小trick,创建一个接收函数,接收的通信手段用channel,该channel由接收函数创建,以返回值的形式给发送者,接收者会启动一个协程处理发送来的消息。
带缓冲和不带缓冲的,buffer:make(chan int,3),带缓冲的只有发满缓冲,才会阻塞,带缓冲channel可提高性能。
Close(),数据有个非常明确的结尾,告诉接收方,没有数据要发送了,接收方会收到0。
判断关闭的两个方法:
- 用第二个参数判断通道是否关闭,即
if n,ok:=<-c;ok{}else{}。 - 用range的方式
package main
import (
"fmt"
)
func receive()chan<-int{
c:=make(chan int)
//该协程的生命周期是外边的那个下协程,即main函数结束后,到期
//而不是receive函数
go func(){
//n:=<-c
//fmt.Println(n)
/*v1
for{
if n,ok:=<-c;ok{
fmt.Println(n)
}
}
*/
for n:=range c{
fmt.Println(n)
}
}()
return c
}
func send(){
c:=receive()
//n:<-c //这里不能接收,类型不匹配
//fmt.Println(n)
c<-10
c<-9
close(c)
}
func main() {
send()
time.Sleep(time.Millisecond)
}
输出:
10
9
两个例子:
- 使用channel来等待goroutine结束,以及可以用WaitGroup的使用。
- 使用Channel来实现树的遍历。
使用Select来进行调度,谁先到,先处理谁;可以通过select+default实现非阻塞式的获取。
- select的使用
- 定时器的使用
- 在select中使用Nil Channel,在数据还没有准备好时,将channel置为nil,这样就不会通过该case
package main
import (
"fmt"
"math/rand"
"time"
)
func generator() chan int{
out:=make(chan int)
go func(){
i:=0
for{
time.Sleep(time.Duration(rand.Intn(1500))*time.Millisecond)
out<-i
i++
}
}()
return out
}
func worker(id int, c chan int){
for n:=range c{
fmt.Printf("worker %d received %d \n",id,n)
time.Sleep(1 *time.Second)
}
}
func createWorker(id int)chan <-int{
c:=make(chan int)
go worker(id,c)
return c
}
func main() {
var c1,c2 =generator(),generator()
var worker =createWorker(0)
n:=0
var values []int
tm:=time.After(10*time.Second)
//每个一段时间,送来一个值
tick:=time.Tick(time.Second)
for{
var activeValue int
var activeWorker chan<- int
if len(values)>0{
activeWorker=worker
activeValue=values[0]
}
select {
//这里有个问题,就是生产和消费的速度不匹配,会丢失数据
//丢失原因在于接收放到了n上,会重复接收,即覆盖掉
case n=<-c1:
values=append(values,n)
case n=<-c2:
values=append(values,n)
//当activeWorker!=nil时,才可能通过此case
case activeWorker<-activeValue:
values=values[1:]
//每次select的时间
case <-time.After(400*time.Millisecond):
fmt.Println("timeout")
//每秒钟看一下队列的长度
case <-tick:
fmt.Println("queue len=",len(values))
//总体的时间
case <-tm://10s后从这里结束
fmt.Println("bye")
return
}
}
}
Go一般不使用传统的同步机制,一般使用chan,但也提供传统的同步机制:
- WaitGroup
- Mutex
- Cond
package main
import (
"fmt"
"sync"
"time"
)
type atomicInt struct{ //模拟原则操作
value int
lock sync.Mutex
}
func (a*atomicInt)increment(){
a.lock.Lock()
defer a.lock.Unlock()
a.value++
}
func (a*atomicInt)increment2(){
fmt.Println("safe increment")
func(){
a.lock.Lock()
//这里的defer相对于外层的increment会起作用
defer a.lock.Unlock()
a.value++
}()
}
func (a*atomicInt)get()int{
a.lock.Lock()
defer a.lock.Unlock()
return a.value
}
func main() {
var a atomicInt
a.increment()
go func(){
//a.increment()
a.increment2()
}()
time.Sleep(time.Millisecond)
fmt.Println(a.get())
}
详情见imooc/Google资深工程师深度讲解Go语言