ECCV2020 | HoughNet:将投票机制引入自下而上目标检测,整合局部和全局信息
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

本文收录于ECCV2020,从自下而上的角度出发,在目标检测任务中引入了投票机制,使得HoughNet能够集成近距离和远距离的class-conditional evidence进行视觉识别。算是一种融合局部和全局信息的手段,其实可以推广到语义分割领域。代码也开源了,可以多多参考。
论文地址:https://arxiv.org/pdf/2007.02355.pdf
代码地址:https://github.com/nerminsamet/houghnet
本文提出了一种基于anchor-free和投票voting机制的单阶段自底向上的目标检测方法。受通用霍夫变换启发,HoughNet通过在某个位置上投票的总和来确定某个位置上某个目标对象是否存在,同时根据对数极坐标投票机制,从近距离和远距离位置收集选票。得益于这种投票机制,HoughNet能够集成近距离和远距离的class-conditional evidence进行视觉识别,从而推广和增强了目前仅基于local evidence的物体检测方法。在COCO数据集上,HoughNet达到了46.4AP,在自下而上的目标检测方面与最新技术性能相当,并且性能优于大多数主要的一阶段和两阶段方法。同时,在另一项任务(即通过将HoughNet的投票vote模块集成到两个不同的GAN模型中,可以生成“照片标签”图像,并显示在两种情况下准确性都得到了显着提高。
简介
目标检测算法除了可以分为经典的一阶段与两阶段两种之外,还可以将当前方法分为两类:自顶向下和自底向上。在自上而下的方法中,将以矩形框的形式检测目标,并基于这些框以整体方式预测目标。设计假设空间(例如anchor框的参数)本身就是一个问题。另一方面,在自下而上的方法中,目标是通过检测部分结构(或子对象结构)而出现的。例如,在CornerNet 中,首先检测到目标的左上角和右下角,然后再检测它们配对形成整个目标。根据CornerNet,Extremenet [4将极端点(例如最左边等)和中心点进行分组以形成目标对象。CenterNet 与CornerNet 的角点对加了中心点,将每个目标对象建模为三元组。本文的HoughNet遵循自下而上的基于投票策略的方法:从广泛的区域(包括short and long-range evidence)来投票获得object presence score。
当前最先进的基于深度学习的目标检测器(例如:RetinaNet、PANet)主要遵循自顶向下方法,通过矩形区域分类从整体上检测对象。Pre-deep-learning methods不是这种情况。自下而上的方法是其中主要的研究重点,例如基于投票vote的方法(隐式形状模型)和基于part的方法(可变形part模型)。但是,如今,在基于深度学习的目标检测器中,尚未充分探索自下而上的方法。仅在最近,才提出了一些自下而上的方法(例如CornerNet ,ExtremeNet)。
在本文中,提出了一种HoughNet,它是一种基于anchor-free和投票voting机制的单阶段自底向上的目标检测方法。Hough变换是一种基于投票的方法,最初被用于检测分析例如线条,圆形,椭圆形等特征。而广义霍夫变换(GHT)用于检测任意形状。类似地,在HoughNet中,属于某个类的对象在特定位置的存在由在该位置上投射的类条件投票的总和确定(图1)。 HoughNet使用卷积神经网络处理输入图像以生成每个类别的中间分数map(intermediate score map ),这些map中的分数表示存在视觉结构,该视觉结构将支持检测目标实例。这些结构可以是object parts、partial objects 、属于相同或其他类的部分,并将这些分数图命名为“视觉证据”图(“visual evidence” map)。视觉证据图中的每个空间位置都会对可能包含目标对象的目标区域进行投票。目标区域是通过放置一个以对数极点网格( log-polar grid)为中心来确定的,其中心位于选民的位置。使用log-polar vote field的目的是随着投票者位置和目标区域之间的距离增加而降低投票的空间精度。这是受自然界的偏心视觉系统(foveated vision systems)启发的,空间分辨率从中央向周边迅速降低。通过投票处理所有“visual evidence”后,累积的投票将记录在对象所存在地图中,其中的峰值(即局部最大值)表示目标实例的存在。

图1 :(左)HoughNet的示例“鼠标”检测(带有黄色边框)。(右)对该检测投票的位置。颜色表示投票强度。除了来自鼠标本身的局部投票外,还有来自“键盘”对象附近的高强度投票,这表明HoughNet能够利用短时和长期证据进行检测。
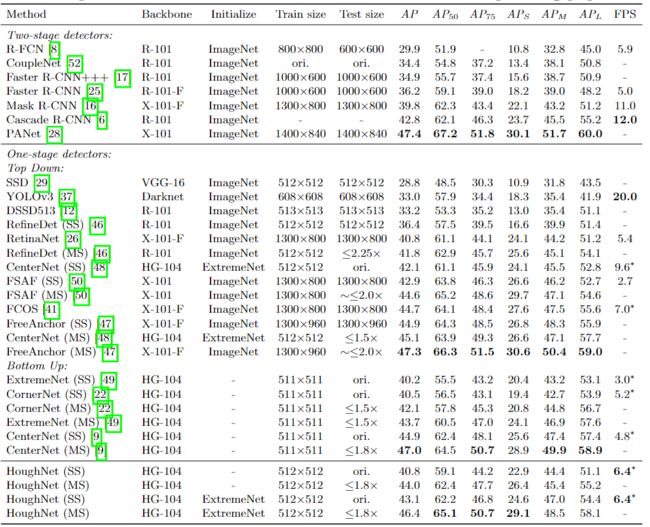
目前最先进的物体检测器依靠局部(或短距离)的visual evidence(如自上而下的方法)或重要的关键点如角点(如自下而上的方法)来决定该位置是否有物体。HoughNet能够通过投票来整合短距离和长距离的视觉证据。图1是一个例子,被检测到的鼠标得到了两个键盘的投票,其中一个键盘就在图像的另一边。在COCO数据集上,HoughNet实现了与CenterNet相当的结果,同时也是检测器中速度最快的对象检测器。它的性能优于著名的单阶段检测器(RetinaNet)和两阶段检测器(Faster RCNN、Mask RCNN)。为了进一步展示本文方法的有效性,在另一个任务中使用了HoughNet的投票模块,即 "标签到照片 "的图像生成。具体来说,将投票模块集成到两个不同的GAN模型(CycleGAN和Pix2Pix)中,结果表明,这两种情况下的性能都有所提高。
本文的方法:oughNet: the method and the models
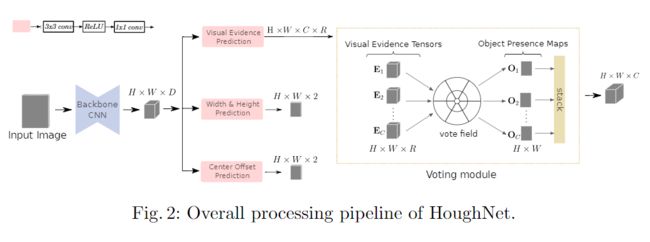
本文的方法的整个处理流程如图2所示。输入图像首先通过主干CNN,其主输出连接到三个不同的分支:(i)进行视觉证据得分的预测, (ii)目标的边界框尺寸(宽度和高度)预测,以及(iii)目标的中心位置偏移预测。其中第一个分支是进行投票的地方。
1、The log-polar “vote field”
使用标准对数极坐标系中的区域集来定义收集投票的区域。一个对数极坐标系是由偏心轴(或环)的数量和半径以及角度轴的数量来定义的,把这种坐标系中形成的单元或区域集称为 "vote field"(图3)。在实验中,使用了不同的vote ∆r(i)表示第i个像素的相对空间坐标。在下文中,R表示vote域中的区域数,Kr表示某一特定区域r中的像素数,Δr(i)表示相对于vote域中心的第i个像素的相对空间坐标。同时,将vote域作为一个固定权重(非学习型)的转置卷积来实现。
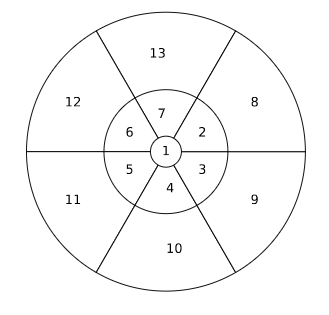
图3:在HoughNet的投票模块中使用的对数极坐标“vote field”。数字表示区域ID。vote field的参数是angle bins,eccentricity bins的数量和半径。在这个特定的投票区域中,总共有13个区域,6个angle bins和3个环。环的半径分别为2、8和16。
2 Voting module
输入的图像通过主干网络和“visual evidence”分支后,HoughNet的投票模块将接收C个张量E1,E2,...,EC,它们的大小分别为H×W×R,其中C是类别数,R是区域数。这些张量中的每个张量均包含类条件的(即针对特定类)“visual evidence”得分。投票模块的工作是生成C个“object presence”map,每个map的大小为H×W。然后,这些图中的峰值将表示目标实例的存在。
投票过程将visual evidence张量(例如Ec)转换为目标存在map,其工作过程如下所述:假设要在证据张量E的第i个行,第j个列和第三个通道上处理visual evidence。将投票字段放置在以位置(i,j)为中心的2D地图上时,区域标记要投票的目标区域,可通过将坐标偏移量∆r(·)加到(i,j)来计算其坐标。然后,将视觉证据分数E(i,j,r)添加到目标存在地图的目标区域中,同时处理来自(i,j)以外位置的视觉证据分数,并在目标存在图下累积分数。在算法1中正式定义了此过程,该过程以视觉证据张量作为输入并生成目标存在图。注意,由于for循环,单纯的算法1实现效率很低,但是,使用“转置卷积”操作可以有效地实现它。

class Hough(nn.Module):
def __init__(self, angle=90, R2_list=[4, 64, 256, 1024], num_classes=80,
region_num=9, vote_field_size=17):
super(Hough, self).__init__()
self.angle = angle
self.R2_list = R2_list
self.region_num = region_num
self.num_classes = num_classes
self.vote_field_size = vote_field_size
self.deconv_filter_padding = int(self.vote_field_size / 2)
self.deconv_filters = self._prepare_deconv_filters()
def _prepare_deconv_filters(self):
vote_center = torch.tensor([64, 64]).cuda()
logmap = self.calculate_logmap((128, 128), vote_center)
logmap_onehot = torch.nn.functional.one_hot(logmap.long(), num_classes=int(logmap.max()+1)).float()
logmap_onehot = logmap_onehot[:, :, :self.region_num]
weights = logmap_onehot / \
torch.clamp(torch.sum(torch.sum(logmap_onehot, dim=0), dim=0).float(), min=1.0)
start = 63 - int(self.vote_field_size/2) + 1
stop = 63 + int(self.vote_field_size/2) + 2
deconv_filters = weights[start:stop, start:stop,:].permute(2,0,1).view(self.region_num, 1,
self.vote_field_size, self.vote_field_size)
W = nn.Parameter(deconv_filters)
W.requires_grad = False
layers = []
deconv_kernel = nn.ConvTranspose2d(
in_channels=self.region_num,
out_channels=1,
kernel_size=self.vote_field_size,
padding=self.deconv_filter_padding,
bias=False)
with torch.no_grad():
deconv_kernel.weight = W
layers.append(deconv_kernel)
return nn.Sequential(*layers)
def generate_grid(self, h, w):
x = torch.arange(0, w).float().cuda()
y = torch.arange(0, h).float().cuda()
grid = torch.stack([x.repeat(h), y.repeat(w, 1).t().contiguous().view(-1)], 1)
return grid.repeat(1, 1).view(-1, 2)
def calculate_logmap(self, im_size, center, angle=90, R2_list=[4, 64, 256, 1024]):
points = self.generate_grid(im_size[0], im_size[1]) # [x,y]
total_angles = 360 / angle
# check inside which circle
y_dif = points[:, 1].cuda() - center[0].float()
x_dif = points[:, 0].cuda() - center[1].float()
xdif_2 = x_dif * x_dif
ydif_2 = y_dif * y_dif
sum_of_squares = xdif_2 + ydif_2
# find angle
arc_angle = (torch.atan2(y_dif, x_dif) * 180 / PI).long()
arc_angle[arc_angle < 0] += 360
angle_id = (arc_angle / angle).long() + 1
c_region = torch.ones(xdif_2.shape, dtype=torch.long).cuda() * len(R2_list)
for i in range(len(R2_list) - 1, -1, -1):
region = R2_list[i]
c_region[(sum_of_squares) <= region] = i
results = angle_id + (c_region - 1) * total_angles
results[results < 0] = 0
return results.view(im_size[0], im_size[1])
def forward(self, voting_map, targets=None):
batch_size, channels, width, height = voting_map.shape
voting_map = voting_map.view(batch_size, self.region_num, self.num_classes, width, height)
heatmap = torch.zeros((batch_size, self.num_classes, width, height), dtype=torch.float).cuda()
for i in range(self.num_classes):
heatmap[:, i, :, :] = self.deconv_filters(voting_map[:, :, i, :, :]).squeeze(dim=1)
return heatmap3、 Network architecture
主干网络选用CenterNet,输出是尺寸为H×W×D的特征图,这是输入尺寸为4H×4W×3的图像的结果。主干网络的输出被送到所有三个分支。每个分支具有一个3×3的卷积层,然后是ReLU层和另一个1×1卷积层。这些转换层的权重不在分支之间共享。Visual evidence分支输出的尺寸为H×W×C×R的特征图,其中C和R分别对应于类别数和投票字段区域数。宽度/高度预测分支输出H×W×2大小的特征图,该输出预测每个可能的目标中心的高度和宽度。最后,中心偏移分支可预测中心位置在空间轴上的相对位移。
损失函数:为了优化visual evidence分支,使用了在CornerNet 中引入的修改后的Focal loss。为了恢复由于通过网络进行下采样操作而导致的中心点精度损失,中心偏移预测分支会输出与目标中心无关的位置偏移,并像其他自下而上的检测器一样,我们使用L1 loss优化此分支。最后,宽度和高度预测分支按照CenterNet 的建议通过将损失缩放0.1来使用L1 loss。总损失是每个分支所计算的损失总和。
def compute_bin_loss(output, target, mask):
mask = mask.expand_as(output)
output = output * mask.float()
return F.cross_entropy(output, target, reduction='elementwise_mean')
def compute_rot_loss(output, target_bin, target_res, mask):
# output: (B, 128, 8) [bin1_cls[0], bin1_cls[1], bin1_sin, bin1_cos,
# bin2_cls[0], bin2_cls[1], bin2_sin, bin2_cos]
# target_bin: (B, 128, 2) [bin1_cls, bin2_cls]
# target_res: (B, 128, 2) [bin1_res, bin2_res]
# mask: (B, 128, 1)
# import pdb; pdb.set_trace()
output = output.view(-1, 8)
target_bin = target_bin.view(-1, 2)
target_res = target_res.view(-1, 2)
mask = mask.view(-1, 1)
loss_bin1 = compute_bin_loss(output[:, 0:2], target_bin[:, 0], mask)
loss_bin2 = compute_bin_loss(output[:, 4:6], target_bin[:, 1], mask)
loss_res = torch.zeros_like(loss_bin1)
if target_bin[:, 0].nonzero().shape[0] > 0:
idx1 = target_bin[:, 0].nonzero()[:, 0]
valid_output1 = torch.index_select(output, 0, idx1.long())
valid_target_res1 = torch.index_select(target_res, 0, idx1.long())
loss_sin1 = compute_res_loss(
valid_output1[:, 2], torch.sin(valid_target_res1[:, 0]))
loss_cos1 = compute_res_loss(
valid_output1[:, 3], torch.cos(valid_target_res1[:, 0]))
loss_res += loss_sin1 + loss_cos1
if target_bin[:, 1].nonzero().shape[0] > 0:
idx2 = target_bin[:, 1].nonzero()[:, 0]
valid_output2 = torch.index_select(output, 0, idx2.long())
valid_target_res2 = torch.index_select(target_res, 0, idx2.long())
loss_sin2 = compute_res_loss(
valid_output2[:, 6], torch.sin(valid_target_res2[:, 1]))
loss_cos2 = compute_res_loss(
valid_output2[:, 7], torch.cos(valid_target_res2[:, 1]))
loss_res += loss_sin2 + loss_cos2
return loss_bin1 + loss_bin2 + loss_res实验与结果
数据集: Mini COCO
为了在消融实验中更快地进行分析,本文创建了“ COCO mini train”作为经过统计验证的迷你训练集。它是COCO train2017数据集的子集,包含25K个图像(约占COCO train2017的20%数据量)和80个类别中约184K个样本。本文从全套样本中随机抽取这些图像,同时尽可能保留以下三个数量:(i)每个类别的对象实例所占的比例(ii)小,中和大型物体的总体比例(iii)每个小、中大型物体类别的比例。
消融实验
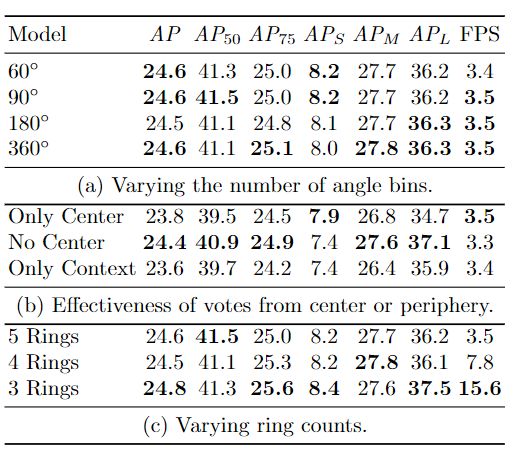
可视化实验

图4:HoughNet及其投票图的样本检测。在“检测”列中,显示了对感兴趣的对象的正确检测,并标有黄色边框。在“投票者Voter”列中,显示了为检测投票的位置。颜色表示基于标准颜色图的投票强度,其中红色对应最高值,蓝色对应最低值(见图1)。在最上面的一行中,有三个“鼠标”检测。在所有情况下,除了位置投票(在鼠标本身上)之外,还有来自附近“键盘”对象的强大投票。考虑到鼠标和键盘对象经常同时出现,这种投票方式是合理的。在第二行的“棒球棒”、“棒球手套”和“网球拍”的检测中观察到类似的行为。这些对象从遥远的“球”对象中获得了强大的vote。同样,在第三行中,“花瓶”检测得到鲜花的强烈支持。在底行的第一个示例中,“可餐桌”检测从蜡烛对象中获得了强烈的支持,这可能是因为它们经常同时发生。蜡烛不属于COCO数据集的80个类别。类似地,在底部行的第二个示例中,“餐桌”具有来自标准客厅的对象和部分的强烈支持。在最后一个示例中,部分遮挡的鸟从树枝上获得了较高的票数(强于鸟本身的票数)
迁移实验

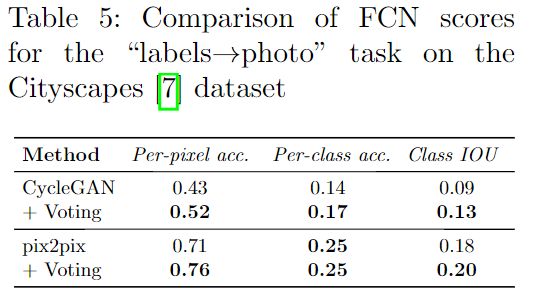
更多细节可参考论文原文。

