python+scrapy+selenium爬京东零食数据+简单分析
一、工具
win8.1
python3.7
pycharm
fiddle
firefox、chrome
MySQL
二、项目简介
本项目爬取了京东的商品编号、商品名称、评论数、价格、好评度等信息。其中评论数、价格、好评度这三个参数是异步加载的,不能直接从页面源代码获取,在这里我采用了fiddle进行抓包分析。
当第一版爬虫从京东获取数据后,发现近半数的商品价格没有获取到。于是针对没有获取到价格的商品重新抓包分析,得到了另外一个存放价格的js,顺利从中得到了价格。
京东商品页存在着懒加载机制,先加载30个商品信息,下拉滚动条,触发ajax请求再加载30个商品信息。这里通过selenium来解决。
数据库表结构如下(商品id,零食名字,评论数,价格,店名,链接,好评度):

注:其实好评度那边本来想写praise_degree的,结果也不知道怎么就写成price_degree,后来为了偷懒也就没改。(p・・q)
三、项目实战
item.py
import scrapy
class JingdongItem(scrapy.Item):
id = scrapy.Field()
name = scrapy.Field()
comment_amount = scrapy.Field()
price = scrapy.Field()
shop_name = scrapy.Field()
link = scrapy.Field()
price_degree = scrapy.Field()jdls.py
# -*- coding: utf-8 -*-
import scrapy
from jingdong.items import JingdongItem
from scrapy.http import Request
import urllib.request
import re
class JdlsSpider(scrapy.Spider):
name = 'jdls'
allowed_domains = ['jd.com']
start_urls = ['http://jd.com/']
def parse(self, response):
try:
key = "零食"
search_url = "https://search.jd.com/Search?keyword=" + key + "&enc=utf-8&wq=" + key
for i in range(1,101):
page_url = search_url + "&page=" + str(i*2-1)
#print("现在第"+str(i)+"页了",end="")
yield Request(url=page_url,callback=self.next,meta={'proxy': '58.210.94.242:50514'})
except Exception as e:
print(e,end="")
print("失败---")
def next(self,response):
id = response.xpath('//ul[@class="gl-warp clearfix"]/li/@data-sku').extract()
for j in range(0,len(id)):
ture_url = "https://item.jd.com/" + str(id[j]) + ".html"
yield Request(url=ture_url,callback=self.next2,meta={'proxy': '58.210.94.242:50514'})
def next2(self,response):
item = JingdongItem()
item["name"] = response.xpath('//head/title/text()').extract()[0].replace('【图片 价格 品牌 报价】-京东','').replace('【行情 报价 价格 评测】-京东','')
tshopname = response.xpath('//div[@class="name"]/a/text()').extract()
item["shop_name"] = tshopname[0] if tshopname else None
item["link"] = response.url
thisid = re.findall('https://item.jd.com/(.*?).html',item['link'])[0]
item["id"] = thisid
priceurl = "https://p.3.cn/prices/mgets?callback=jQuery3630170&type=1&area=1_72_4137_0&pdtk=&pduid=575222872&pdpin=&pin=null&pdbp=0&skuIds=J_" + thisid + "%2CJ_7931130%2CJ_8461830%2CJ_6774075%2CJ_6774155%2CJ_6218367&ext=11100000&source=item-pc"
commenturl = "https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv3575&productId=" + thisid + "&score=0&sortType=5&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1"
pricedata = urllib.request.urlopen(priceurl).read().decode("utf-8", "ignore")
commentdata = urllib.request.urlopen(commenturl).read().decode("utf-8", "ignore")
pricepat = '"p":"(.*?)"'
commentpat = '"goodRateShow":(.*?),'
comment_amountpat = '"goodCount":(.*?),'
tprice = re.compile(pricepat).findall(pricedata)
item["price"] = tprice[0] if tprice else None
if item["price"] ==None:
newpriceurl = "https://c0.3.cn/stock?skuId="+thisid+"&cat=1320,1583,1591&venderId=88149&area=1_72_4137_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&pdpin=&callback=jQuery9513488"
newpricedata = urllib.request.urlopen(newpriceurl).read().decode("utf-8", "ignore")
newtprice = re.compile(pricepat).findall(newpricedata)
item["price"] = newtprice[0] if newtprice else None
tdegree = re.compile(commentpat).findall(commentdata)
item["price_degree"] = tdegree[0] if tdegree else None
item["comment_amount"] = re.compile(comment_amountpat).findall(commentdata)[0]
print("读取成功")
yield itemmiddlewares.py
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from scrapy.http.response.html import HtmlResponse
import time
class ProxyMiddleware(object):
def process_request(self, request, spider):
# Set the location of the proxy
request.meta['proxy'] = "http://119.101.116.12:9999"
class JingdongSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class JingdongDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class JingdongspiderDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
#设置随机请求头
class MyUserAgentMiddleware(object):
MY_USER_AGENT = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
]
def process_request(self, request, spider):
import random
request.headers['User-Agent'] = random.choice(self.MY_USER_AGENT)
# 构建chromedriver 并模拟下滑
class ChromeDriverMiddleware(object):
chrome_options = Options()
chrome_options.add_argument('window-size=1920x3000') # 指定浏览器分辨率
chrome_options.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--hide-scrollbars') # 隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false')#不加载图片, 提升速度
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
def __del__(self):
self.browser.quit()
def process_request(self, request, spider):
browser = self.browser
browser.get(request.url)
time.sleep(1)
# 模拟滚动条下滑
js = 'var q=document.documentElement.scrollTop=100000'#设置滚动条的垂直偏移:
browser.execute_script(js)
time.sleep(1)#设置等待时间
#获取网页源代码
page_source = browser.page_source
#根据网页源代码,创建htmlresponse对象
#因为返回的是文本内容,指定字符编码格式
response = HtmlResponse(request.url, body=page_source, encoding='utf-8', request=request)
return responsepipelines.py
# -*- coding: utf-8 -*-
import pymysql.cursors
class JingdongPipeline(object):
def process_item(self, item, spider):
conn = pymysql.connect(host="localhost", user="用户名",
password="密码", db="数据库名字", port=端口号)
cur = conn.cursor()
print("正在写入数据库...")
sql = "INSERT INTO newls_copy(id,lsname,comment_amount,price,shop_name,link,price_degree) VALUES ('%s','%s','%s','%s','%s','%s','%s')"
data = (item["id"],item["name"],item["comment_amount"],item["price"],item["shop_name"],item["link"],item["price_degree"])
cur.execute(sql % data)
conn.commit()
print("写入成功!")
conn.close()
return itemsettings.py
BOT_NAME = 'jingdong'
SPIDER_MODULES = ['jingdong.spiders']
NEWSPIDER_MODULE = 'jingdong.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/68.0.3440.106 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'jingdong.middlewares.JingdongDownloaderMiddleware': 543,
'jingdong.middlewares.MyUserAgentMiddleware': 553,
'jingdong.middlewares.ChromeDriverMiddleware': 563,
}
ITEM_PIPELINES = {
'jingdong.pipelines.JingdongPipeline': 300,
}四、参考
https://blog.csdn.net/weixin_38654336/article/details/79747544
https://blog.csdn.net/xing851483876/article/details/80817578
https://blog.csdn.net/qq_33517374/article/details/81664054
五、分析
本项目共爬到数据5828条,对此进行如下简单分析。
5.1价格、好评度、评论数的分布状况
5.2价格与评论数之间的关系
5.1.1统计价格在各区间的分布量,绘制柱状图
| 价格范围 | 个数 | 百分比(保留2位小数) |
| [0,10) | 698 | 11.98% |
| [10,20) | 1467 | 25.17% |
| [20,30) | 1110 | 19.05% |
| [30,40) | 711 | 12.20% |
| [40,50) | 371 | 6.37% |
| [50,60) | 277 | 4.75% |
| [60,70) | 201 | 3.45% |
| [70,80) | 173 | 2.97% |
| [80,90) | 128 | 2.20% |
| [90,100) | 133 | 2.28% |
| [100,410) | 559 | 9.59% |
分析项目爬到的项目数据,发现其价格最小值为0,最大值为408元。因此设定统计范围为[0,410),间距为10,得到左侧表,并绘制柱状图,见下图1。
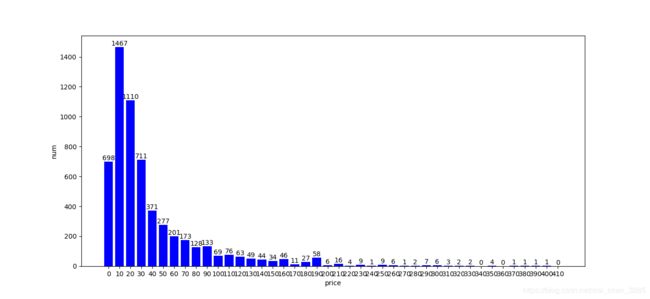 图1:商品数量与价格区间分布图
图1:商品数量与价格区间分布图
发现商品数量与价格图有点像服从卡方分布。
等下用spss检测下。
5.1.2统计价格在各区间的分布量,绘制柱状图
 图2:商品数量与好评度区间分布图
图2:商品数量与好评度区间分布图
分析项目爬到的项目数据,发现其好评度最小值为85%,最大值为100%。因此设定统计范围为[85,101),间距为1,绘制柱状图,如图2。
分析:好评度为97%的商品数量占2.93%
好评度为98%的商品数量占16.44%
好评度为99%的商品数量占76.25%
好评度为100%的商品数量占3.04%
因为好评度这一指标区分度不够明显,所以不能用好评度作为主要指标来衡量商品的优劣性。
5.1.3统计评论数在各区间的分布量,绘制柱状图
 图3:商品数量与评论数区间分布图
图3:商品数量与评论数区间分布图
嗷,这张图横坐标太恐怖了,主要是因为评论数跨度太大,从0~2380000,这张图我设定的间隔是60000。从中,可以发现评论数在[0,60000)这个范围内的商品占绝大部分,但这个间隔跨度太大不易分析,故再一次分析这个范围内的商品数量与价格的关系。
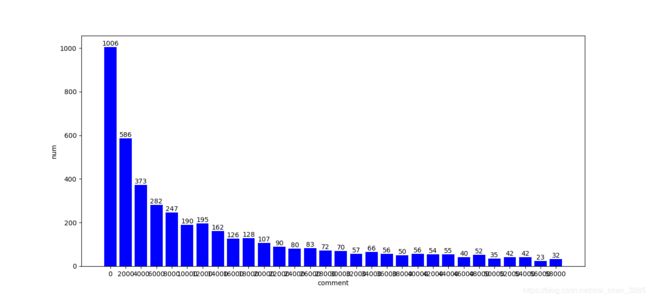 图4:商品数量在某一评论数区间内的分布图
图4:商品数量在某一评论数区间内的分布图
在图4中,横坐标范围是[0,60000),间隔为2000。可以看出,商品数量随着评论数的增多呈递减趋势,即大部分的商品评论数比较少,随着评论数要求的提高,越来越少的商品能满足这个要求。
5.2价格与评论数之间的关系
因为好评度这一指标区分度不够明显,故暂不考虑好评度与价格、好评度与评论数之间的关系。
根据获取的数据,绘制关于价格与评论数的散点图
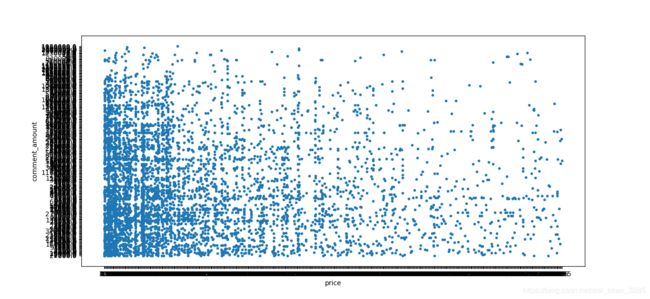 价格与评论数的散点图
价格与评论数的散点图
我们可以看出,一般价格较低的商品,评论数较多(这里猜想原因为价格较低的商品销量较高),随着价格的上升,商品评论数会下降。(因为购买人数也可能下降了),但从图中也可以发现有部分点处于价格高、评论数也高的区域,那么是不是可以猜想该商品刷单了呢?๑乛v乛๑
5.3代码
analysis.py
import pymysql.cursors
import matplotlib.pylab as pyl
import numpy as np
import pandas as pd
conn = pymysql.connect(host='localhost', user='用户名', passwd='密码', db='数据库名字',port=端口号)
cur = conn.cursor()
selectsql = "select * from 你的数据表"
cur.execute(selectsql.encode('utf-8'))
data_tuple = cur.fetchall()
data_array = np.array(data_tuple)
data_list = list(data_tuple)
def draw_odd(mydata,start,end,step):
x = []
y = []
begin = start
for i in range(start,end,step):
x.append(i)
y.append(0)
while (start+step) <= end:
num = 0
for j in range(len(mydata)):
if float(mydata[j])>=start and float(mydata[j])本人才疏学浅,如有谬误,欢迎在评论区提出,大家一起讨论,一起学习!