Spark大数据分析-MLlib:线性代数
目录
- 本地向量和矩阵实现
- 生成本地向量
- 本地向量线性代数运算
- 生成本地密集矩阵
- 生成局部稀疏矩阵
- 分布式矩阵
- RowMatrix
- IndexedRowMatrix
- CoordinateMatrix
- BlockMatrix
- 具有分布式矩阵的线性代数运算
线性代数是数学的分支,专注于向量空间和线性运算,它们之间的映射主要由矩阵表示。Spark中的矩阵和向量可以在本地或以分布式方式进行操作。Spark中分布式矩阵的实现使用户能够跨越大量机器对大量数据进行线性代数运算。对于局部线性代数操作,Spark使用非常快的Breeze和jblas(Python的Numpy),并且它具有自己的分布式实现。
本地向量和矩阵实现
spark中的本地向量和矩阵实现位于org.apache.spark.mllib.linalg中。
生成本地向量
Spark中的本地向量使用DenseVector和SparseVector两个类实现,它们实现了一个名为Vector的通用接口,确保两个实现都支持完全相同的操作集。创建向量可以使用Vector类的dense和sparse方法。对于dense方法可以传入多个元素作为参数,也可以传入Array数组。sparse方法,则需要指定向量大小,索引数组和元素数组。
import org.apache.spark.mllib.linalg.{Vectors,Vector}
val dv1:Vector = Vectors.dense(5.0,6.0,7.0,8.0)
val dv2:Vector = Vectors.dense(Array(5.0,6.0,7.0,8.0))
val sv:Vector = Vectors.sparse(4, Array(0,1,2,3), Array(5.0,6.0,7.0,8.0))
dv2(2)
dv1.size
dv2.toArray
本地向量线性代数运算
可以使用Breeze库完成对局部向量的线性代数运算,toBreeze函数存在于向量和矩阵的本地实现中,但它们是private的,而且Spark社区不允许访问。另一种方法是创建自己的将Spark向量转换成Breeze类的函数。
import org.apache.spark.mllib.linalg.{DenseVector, SparseVector}
import breeze.linalg.{DenseVector => BDV,SparseVector => BSV,Vector => BV}
def toBreezeV(v:Vector):BV[Double] = v match {
case dv:DenseVector => new BDV(dv.values)
case sv:SparseVector => new BSV(sv.indices, sv.values, sv.size)
}
然后使用函数(toBreezeV)和Breeze库添加向量并计算它们的点积。
toBreezeV(dv1) + toBreezeV(dv2)
toBreezeV(dv1).dot(toBreezeV(dv2))
Breeze库提供了更多的线性代数操作,用户可以检查其丰富的功能集。由于Breeze类的名称与Spark类的名称冲突,因此在导入期间最好更改类名。
生成本地密集矩阵
类似于Vectors类,Matrices类也具有用于创建矩阵的dense和sparse方法。Dense方法需要行数、列数和元素数组,例如将以下矩阵创建为DenseMatrix
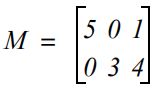
val dm:Matrix = Matrices.dense(2,3,Array(5.0,0.0,0.0,3.0,1.0,4.0))
Matrices对象提供了快速创建恒等矩阵、对角矩阵以及全零和全1矩阵的快捷办法。
eye(n):创建大小为nxn的单位矩阵。
speye:创建主对角线为1,其他元素为0的稀疏矩阵。
ones(m,n):创建大小为mxn的全为1的密集矩阵。
zeros(m,n):创建大小为mxn的全为0的密集矩阵。
此外Matrices对象的rand和randn方法生成一个填充了0~1范围内随机数的DenseMatrix。前者均匀分布生成数字,后者根据高斯分布(正态分布)生成数字。
生成局部稀疏矩阵
生成稀疏矩阵比密集矩阵要复杂,需要将行数和列数和非零元素传递sparse方法。非零元素以压缩稀疏列(csc)格式指定,csc格式由3个数组组成,包含列指针、行索引和非0元素。
val sm:Matrix = Matrices.sparse(2,3,Array(0,1,2,4),Array(0,1,0,1),Array(5.0,3.0,1.0,4.0))
可以使用相应的toDense,toSparse方法实现SparseMatrix和DenseMatrix之间的转换。
sm.asInstanceOf[SparseMatrix].toDense
dm.asInstanceOf[DenseMatrix].toSparse
分布式矩阵
当在大型数据集上使用机器学习算法时,分布式矩阵是必要的。它们存储在许多机器上,并且它们可以具有大量的行和列。分布式矩阵使用Longs而不使用Ints来索引行和列。Spark中有4种类型的分布式矩阵在org.apache.spark.mllib.linalg.distributed中定义:RowMatrix、IndexedRowMatrix、BlockMatrix和CoordinateMatrix。
RowMatrix
RowMatrix将矩阵的行存储在Vector对象的RDD中,可以使用numRows和numCols获得行数和列数,可以使用multiply方法将RowMatrix乘以局部矩阵(生成另一个RowMatrix)
IndexedRowMatrix
IndexedRowMatrix是IndexedRow对象的RDD,每个对象包含行的索引和带有行数据的Vector。
CoordinateMatrix
CoordinateMatrix将其值作为MatrixEntry对象的RDD存储,其中包含矩阵中的各个条目,及其(i,j)位置。
BlockMatrix
BlockMatrix是唯一具有加上和乘以其他分布式矩阵的方法的分布式实现
具有分布式矩阵的线性代数运算
使用分布式矩阵实现的线性代数运算有限,因此需要自己实现一些。比如分布式矩阵的元素加法和乘法仅适用于BlockMatrix。