Spark大数据分析-GraphX:图
目录
- 图基础
- 图的数据类型
- 图的属性
- 图的分区
- 图存储,分布式文件系统与图数据库
- 图的专业术语解释
- 有向图和无向图
- 有环图和无环图
- 有标签的图和无标签的图
- 平行边和环
- 二分图
- RDF图和属性图
- 邻接矩阵
- 图查询系统
- SPARQL
- Cypher
- Tinkerpop Gremlin
- GraphX
图基础
现在图最常用于挖掘社交媒体数据,特别是识别出社交小圈子、推荐新的(社交)连接关系,或推荐产品和广告。这样的社交数据量很大,单机存储能力不够,这时就需要引入Spark,通过集群中的多台机器来存储数据。
图的数据类型
图表示的不同类型数据。网络结构数据(Network),树状结构数据(Tree),类RDBMS数据(RDBMS-like),稀疏矩阵(Sparse matrix),Kitchen sink。
网络结构数据图可以是一个路径网络,或者是一个社交网络,或者是一个计算机网络。树状图是无环图。任何RDBMS都可以被转换成图的格式,如图1.7所示的一个雇员信息数据库被转换成了图。然而要有一些图算法这样做才有价值,如PageRank用于社区发现,或最小生成树算法用于网络规划。
图的属性
在现实世界中,在简单的顶点和边之间的连接之外,还有一些有价值的信息。图因为有了更多数据才更丰富,我们需要一种方式来表示这个丰富性。GraphX用边RDD和顶点RDD这两个RDD来表示一个图,以这种方式表示的图可以让GraphX解决一个处理大图的主要问题:分区。
图的分区
遇到单机的物理内存放不下图的情况时,Spark就可以把这些图划分到集群中的多台机器上。多年来常用的简单切分图的方式是,分配不同的顶点到集群中的不同机器节点上。但这导致了计算瓶颈,因为实际中有一些具有非常高的度的顶点。
度在图中有两个含义。顶点的度的含义是,从一个特定顶点连接出去的边数(出度)和连接进来的边数(入度)之和。
图存储,分布式文件系统与图数据库
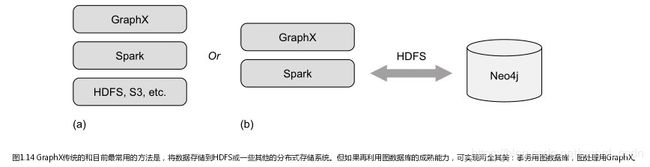
GraphX是一个严格的内存处理系统,所以需要一个存储图数据的地方。Spark要求分布式存储,如HDFS、Cassandra或S3,分布式存储是通常采用的方式。组合GraphX这个图数据系统与图数据库一起使用,充分利用二者的长处,虽然GraphX与Neo4j的优劣对比有激烈的争论,但是要认识到对一些使用场景,将二者结合使用比单独使用一个要好很多。
图的专业术语解释
有向图和无向图
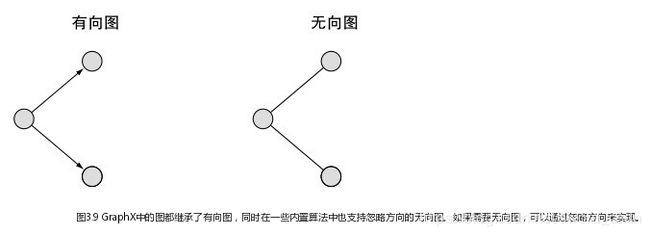
在一个有向图中,联系是从源顶点到目标顶点。万维网中的一个页面到另一个页面的链接,学术论文中的引用,都是比较典型的例子。在有向图中,一条边的两个顶点一般扮演着不同的角色,如父子关系,页面A链接向页面B。在一个无向图中,边没有方向;关系都是对称的。社交网络中一个典型的联系是,通常A如果是B的朋友,我们很可能认为B也是A的朋友。GraphX中的一个重要概念是,所有的边都有一个方向,那么图就是有向图;如果忽略边的方向,就是无向图。
有环图和无环图
有环图是包含循环的,一系列顶点连接成一个环。一个无环图没有环。需要了解有环图和无环图的区别的原因是,如果你有一个算法,通过连接的顶点,沿着连接的边,有向图就会造成这样的风险:不恰当的算法实现会卡住,在环上永远循环下去。
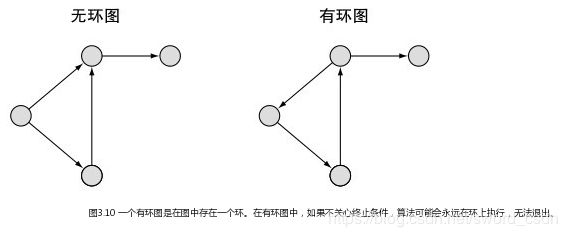
有环图的一个有趣的特征是,其形成一个三角形关系,即每个顶点都与其他两个顶点相连。三角形关系的用途之一是作为一个预测特征来区分垃圾邮件和非垃圾邮件。
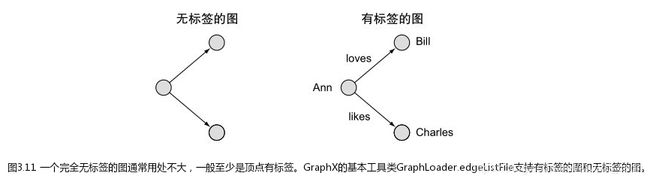
有标签的图和无标签的图
对顶点做了标签的称为顶点标签图,对边做了标签的称为边标签图。
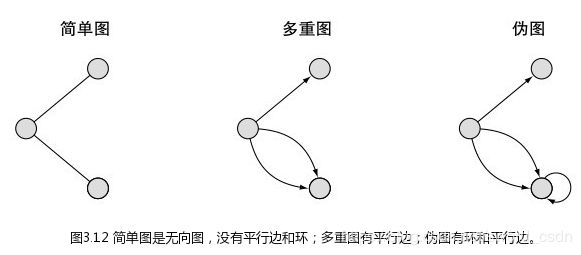
平行边和环
平行边和环的区别在于,是否允许在同一对顶点上同时存在多条边,还是边的起点和终点都是同一个顶点。
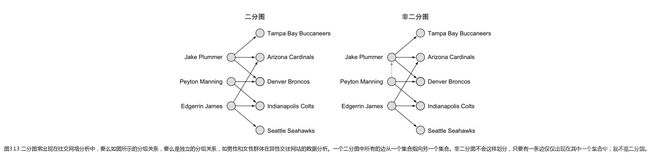
二分图
二分图有一个特定的结构,整个图的顶点被分成两个不同的集合,所有的源顶点是一个集合(所有源顶点之间没有联系),所有的目标顶点是一个集合(目标顶点之间没有联系),在两个集合内都不存在相连的边。
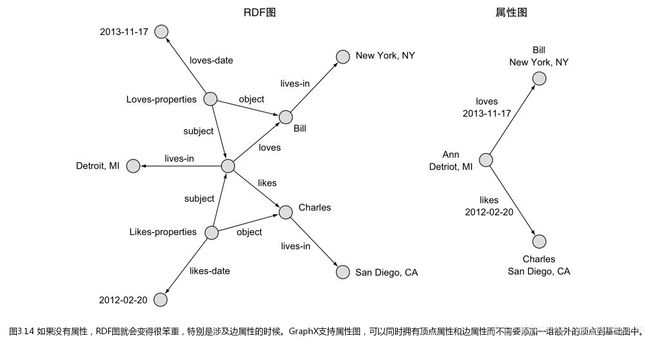
RDF图和属性图
资源描述框架(RDF)是由万维网联盟(W3C)在1997年首次提出的针对语义Web的图标准。它实现了一部分2004年开始更新的RDFa标准。旧的图数据库/图处理系统只支持RDF三元组(主体、谓词、对象),而新的图数据库/图处理系统(包括GraphX)支持属性图。
邻接矩阵
另一种表示图论的方式是邻接矩阵,这不是GraphX表示图的方式。抛开GraphX,Spark的MLlib机器学习库已经支持邻接矩阵,还有更通用的稀疏矩阵。如果你不需要边属性,可以在MLlib找到比GraphX性能更好的算法。例如,推荐系统,从性能的角度来看,mllib.recommendation.ALS会是比graphx.lib.SVDPlusPlus更好的选择,虽然不同场景适用不同算法。

图查询系统
SPARQL
SPARQL是一个类SQL语言,由W3C为了查询RDF图而推出。
Cypher
Cypher是属性图数据库Neo4j使用的查询语言
Tinkerpop Gremlin
Tinkerpop努力创建一个图数据库和图处理系统的接口标准,就像JDBC一样,只不过比JDBC更复杂。Tinkerpop由多个组件构成,而Gremlin是查询系统。有一个把Gremlin整合到GraphX的尝试,即Spark-Gremlin工程,可在https://github.com/kellrott/spark-gremlin上查看,截止到2015年1月,这个工程的最新状态是:没什么要做的了。
GraphX
截止到Spark 1.6,GraphX还没有查询语言。GraphX API更适合在一个大图上运行一些算法,而不是查找一些特定顶点和一些直接的边和顶点。虽然如此,但也可以实现类似的查询功能