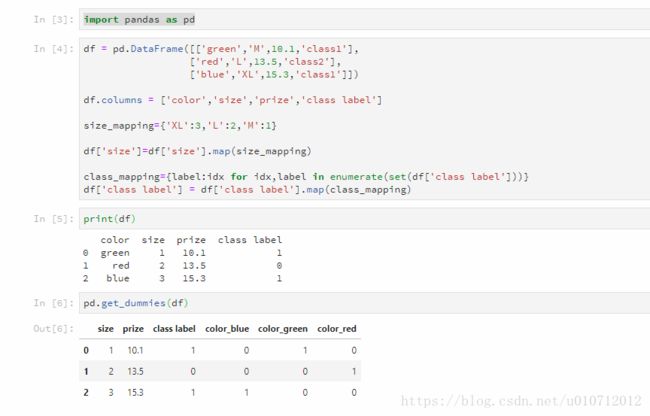
pandas中的get_dummies方法
参考:https://blog.csdn.net/u010665216/article/details/78635664?utm_source=copy
https://blog.csdn.net/lujiandong1/article/details/52836051
pandas中有一种get_dummies的方法:
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)
参数说明:
data : array-like, Series, or DataFrame
输入的数据
prefix : string, list of strings, or dict of strings, default None
get_dummies转换后,列名的前缀
columns : list-like, default None
指定需要实现类别转换的列名
dummy_na : bool, default False
增加一列表示空缺值,如果False就忽略空缺值
drop_first : bool, default False
获得k中的k-1个类别值,去除第一个
离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}