Python全栈开发作业Week-1.1—编写登录接口(Pandas.行列数据选取方法,Pandas与Excel交互实例)
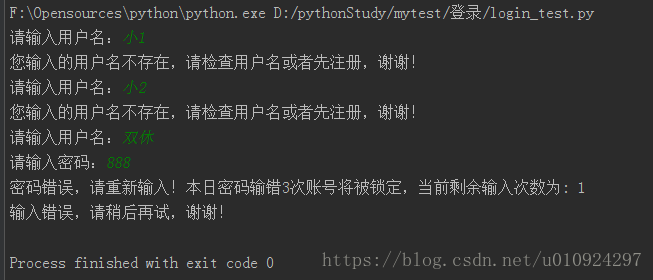
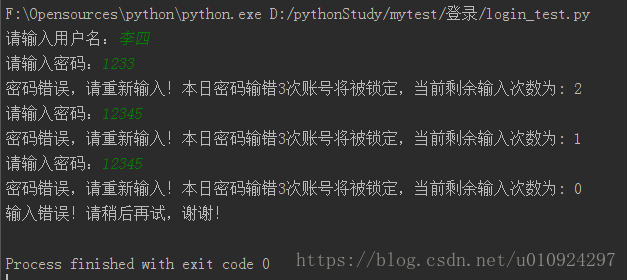
要求:当日用户输入密码次数超过三次,将进行账户锁定,本日不再允许登陆;本次登录连续输错次数三次退出。
知识点:pandas 读取Excel数据,并对数据进行增删改后保存回Excel里面
环境:Python3.6
一、判断准备:
1、用户登录信息表;
2、用户登录错误次数记录表;
3、用户锁定表;
二、Pandas知识准备:
1、Excel数据的读取与保存:
pandas从表中读取数据,是Excel数据的复制版本,增删改数据都不会影响的Excel里面的数据,需要操作生效则需要在最后操作完成后将数据保存回Excel。
import pandas as pd
df = pd.read_excel('文件路径名.xlsx') #文件读取,文件路径名最好用全路径,D:\****\**.xlsx,下同
writer = pd.ExcelWriter('文件路径名.xlsx')#文件保存,注意文件路径名,如果文件不存在则会创建,文件存在则会覆盖
DataFrame.to_excel(writer)#有时候df.to_excel(filepath)就可以了不会报错,有时候会报错。
writer.save2、DataFrame索引行列数据【数据选取】:
行标签/索引:index=XXX部分,索引相当于数据库的主键,唯一确定一行数据,可以用户自己指定的行标签(用户自己指定时,该DataFrame将有两套行索引,一套用户自定义,另一套系统默认索引),不指定则默认0开始编号。--方便起见通俗称行标号
列标签:列名
行编号/列编号 : 统称行列编号,所有行列都是0开始编号,第0行……第N行;注意!当不指定行索引index是,行号和默认行索引是一样的,但索引时候要注意区分,真正理解你用的到底是行索引还是行编号
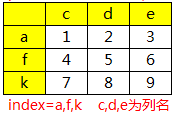
索引数据的三种方式(DataFrame=df)
①通行标签(行索引)以及列标签(列名) 索引数据,固定格式--df.loc[行索引,列名称]
范例:
loc行选择:data.loc[a] / data.loc[a:k] 不会报错--a:k选择a,f,k三行数据,引用了行标签,data.loc[c/d/e]报错,因为cde不是索引,但可以data['c/d/e']---data['index']会报错
loc行列选择:data.loc[a,c]--【索引编号,列名】 如果列名用列编号data['a',0] 则报错
②通过行列编号索引,固定格式-- df.iloc[行编号,列编号]
范例:
iloc行选择:data.iloc[0]--行号是自动编号并非索引,正常切片使用。 如果data.iloc['a']-则报错
iloc行列选择:data.iloc[0,'c/d/e']--报错,行列都必须用编号。
③索引和编号混合使用,综合上两种形式,固定格式--df.ix[行索引,列编号] 或者 df.ix[行编号,列名称]
3、数据查询--已知数值反查数据位置
在实例中,我们需要做到,当用户输入用户名时,则需要判断用户名是否存在用户列表中或者是否存在锁定用户表中,符合条件存在且未锁定用户,还需要提取该用户的密码和输入密码匹配与否。
这里有两种数值是否存在的查询方式:
①数值不多的情况下,在某列中查找是否存在具体的数值:
第一步:df['column_name']=='某个值' ---返回一个布尔类型的df_bool
第二步:索引这个值对应的一行数据,df[df_bool]-----布尔类型数据框同样用来索引数据,true则返回对应位置的数值
综合可以为:df[df['column_name']=='某个值'] 直接返回需要查数值对应的行数据
引申--几个数值条件筛选&条件与,|条件或,df[(df['column_1']=='*') & (df['column_2']=='*')]
范例:
dataFrame下图
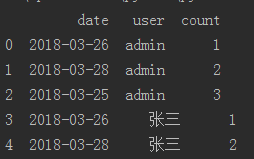
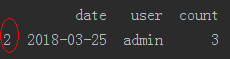
dataFrame[(dataFrame['user']=='admin') & (dataFrame['date']=='2018-03-25')]=下图
②已知若干数据,反查数据框是否存在:
dataFrame[列名称-此处省略则选取整表查询].isin([数值必须是一个列表]) ----返回一个bool型的数据框,isin适用多个数值判断,简化代码。
已查询出数据在数据框存在,返回该数据的行号位置:
已知dataFrame表,查看所有行位置列表=dataFrame.index.tolist() --返回为一个列表,列表元素为行索引编号。
考虑到登录过程中需要反复的判断和查询,我自己变写了一个函数,方便调用:
def find_pd_values(valist,DataFrame,columnsl):
"""
适用已知某一行记录数值,查找该行记录是否存在,返回该行记录行号。
:param valist: 数据值列表,数值顺序可无序--已知的行记录数值
:param DataFrame: 查找的目标数据框
:param columnsl: 已知数据对应的已知数据列名列表-可无序
:return:查找是否存在,数据记录对应的行索引编号
"""
df_temp = DataFrame[columnsl][ DataFrame[columnsl].isin(valist)].dropna(axis=0,how='any').index.tolist()
#DataFrame[columnsl].isin(valist) 查询df中指定数据列是否有数值,返回一个bool类型数据框
#DataFrame[columnsl][ DataFrame[columnsl].isin(valist)]查询出来将是一个具有NaN值得列表,我们只想要一行都是数值的目标数据。
#DataFrame[columnsl][ DataFrame[columnsl].isin(valist)].dropna(axis=0,how='any') 只要含有NAN的数据就丢弃
#最后返回该数据行的 index值
if df_temp:
if_exist = True
des_cloc = df_temp
return if_exist,des_cloc
else:
if_exist = False
des_cloc = None
return if_exist,des_cloc为了方便理解,下面一个范例:
print(df[['date','user']][df[['date','user']].isin(['张三','2018-04-02'])])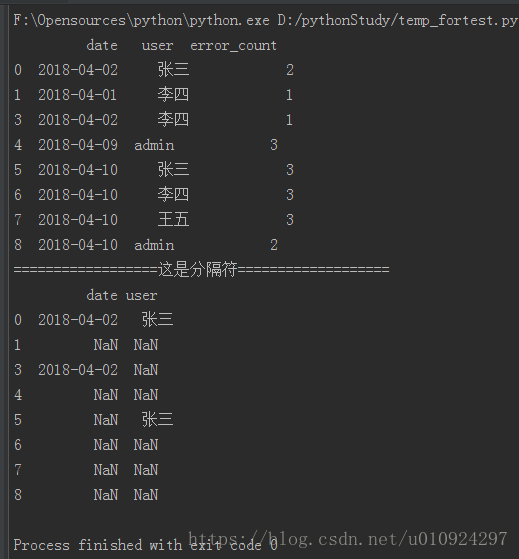
3、增删改
增加以及修改操作会修改当前的df数据,但是删除操作需要外加一个参数inplace=True来指定是否操作本df,默认操作后产生新的df,True表示本df操作覆盖。
增加:
指定的行号新增一行数据:
df.loc[行索引编号] = {'column1': 值1, 'column2': 值2,'column3': 值3,}
新增列数据:
df['new_colname'] = new_coldata
df.loc[9] =['2018-04-10','小增加',2]
df['new_column'] = None
print(df)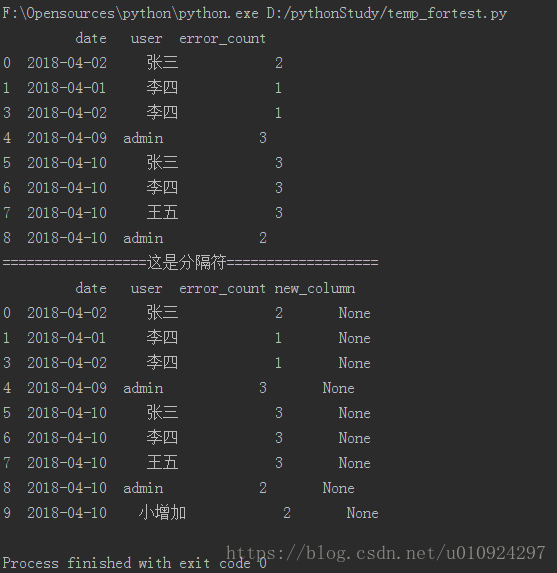
(下面方法就不在举栗子)
删除指定特定数据:
df.drop( [行索引index列表] , inplace=True ) # inplace不指定默认FALSE 下同
删除所有行:
df.drop(df.index ,inplace=True )
修改:
df.ix[ a, b] = new_data
查看索引(行):
print(DataFrame.index)
删除索引:--原来表上操作inplace=True
DataFrame.reset_index(drop=True ,inplace=True) #索引删除后会自动另外生成新的索引。
三、实现代码
代码版本V2.0: 在1的版本上优化,转化为类,方便模块调用
#!/usr/bin/evn python
# -*-coding:utf8 -*-
import xlsxwriter
import pandas as pd
import time,getpass
class Login(object):
def __init__(self, userdfp, ulogdfp, date = time.strftime('%Y-%m-%d',time.localtime(time.time()))):
self.userdf = pd.read_excel(userdfp)
self.ulogdf = pd.read_excel(ulogdfp)
self.date = date
self.userdfp = userdfp
self.ulogdfp = ulogdfp
def find_pd_values(self,valist,DataFrame,columnsl=None):
"""
适用已知某一行记录数值,查找该行记录是否存在,返回该行记录行号。
:param valist: 数据值列表,数值顺序可无序--已知的行记录数值
:param DataFrame: 查找的目标数据框
:param columnsl: 已知数据对应的已知数据列名列表-可无序
:return:查找是否存在,数据记录对应的行索引编号
"""
df_temp = DataFrame[columnsl][DataFrame[columnsl].isin(valist)].dropna(axis=0,how='any').index.tolist()
if df_temp:
if_exist = True
des_loc = df_temp
else:
if_exist = False
des_loc = None
return if_exist, des_loc
def login(self):
counter = 0
username = None
while counter < 3:
counter += 1
if not username:
username = input("请输入用户名:")
if self.find_pd_values([username],self.userdf,['user'])[0]:
while counter < 4:
if self.find_pd_values([username,self.date],self.ulogdf,['date', 'user'])[0]:
if self.ulogdf['if_lock'][self.find_pd_values([username,self.date],self.ulogdf,['date', 'user'])[1][0]] == 1:
print("因您输入密码错误次数太多,账号被锁定,请明日再尝试登陆,不便之前请谅解谢谢!")
exit()
password = input('请输入密码:')
if password == str(self.userdf['password'][self.find_pd_values([username],self.userdf,['user'])[1][0]]):
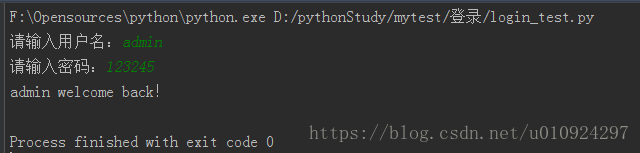
print(username + ' welcome back!')
exit()
else:
if self.find_pd_values([username,self.date],self.ulogdf,['date', 'user'])[0]:
self.ulogdf['error_count'][self.find_pd_values([username,self.date],self.ulogdf,['date', 'user'])[1][0]] += 1
self.ulogdf.to_excel(self.ulogdfp)
print('密码错误,请重新输入!本日密码输错3次账号将被锁定,当前剩余输入次数为:',3-self.ulogdf['error_count'][self.find_pd_values([username,self.date],self.ulogdf,['date', 'user'])[1][0]])
if self.ulogdf['error_count'][self.find_pd_values([username,self.date],self.ulogdf,['date', 'user'])[1][0]] == 3:
self.ulogdf['if_lock'][self.find_pd_values([username,self.date],self.ulogdf,['date', 'user'])[1][0]] = 1
self.ulogdf.to_excel(self.ulogdfp)
counter += 1
continue
else:
print('密码错误,请重新输入!本日密码输错3次账号将被锁定,当前剩余输入次数为:2')
self.ulogdf.loc[len(self.ulogdf.index)+1] = {'user': username, 'date': self.date, 'error_count':1, 'if_lock': 0}
self.ulogdf.to_excel(self.ulogdfp)
counter += 1
continue
else:
username = None
if counter < 3:
print("您输入的用户名不存在,请检查用户名或者先注册,谢谢!")
continue
else:
print("输入错误!您输入错误次数太多,请稍后再试,谢谢!")
if __name__== '__main__':
user_info_filepath=r"D:\pythonStudy\mytest\登录\user_info.xlsx"
login_info_filepath = r"D:\pythonStudy\mytest\登录\login_info.xlsx"
login = Login(user_info_filepath,login_info_filepath)
login.login()
代码运行结果:同版本1相同,但结果展示将会有警告~警告错误可忽略,警告内容因追求代码精简(虽然觉得还是有点长),直接一步到位在copy的数据框修改数据。
代码版本V1.0:
密文输入:password=getpass.getpass("请输入密码:") !该模块可以实现密文输入,但是在pycharm中支持比较差
#!/usr/bin/evn python
# -*-coding:utf8 -*-
import xlsxwriter
import pandas as pd
import time,getpass
def find_pd_values(valist,DataFrame,columnsl):
"""
适用已知某一行记录数值,查找该行记录是否存在,返回该行记录行号。
:param valist: 数据值列表,数值顺序可无序--已知的行记录数值
:param DataFrame: 查找的目标数据框
:param columnsl: 已知数据对应的已知数据列名列表-可无序
:return:查找是否存在,数据记录对应的行索引编号
"""
df_temp = DataFrame[columnsl][ DataFrame[columnsl].isin(valist)].dropna(axis=0,how='any').index.tolist()
#DataFrame[columnsl].isin(valist) 查询df中指定数据列是否有数值,返回一个bool类型数据框
#DataFrame[columnsl][ DataFrame[columnsl].isin(valist)]查询出来将是一个具有NaN值得列表,我们只想要一行都是数值的目标数据。
#DataFrame[columnsl][ DataFrame[columnsl].isin(valist)].dropna(axis=0,how='any') 只要含有NAN的数据就丢弃
#最后返回该数据行的 index值
if df_temp:
if_exist = True
des_cloc = df_temp
return if_exist,des_cloc
else:
if_exist = False
des_cloc = None
return if_exist,des_cloc
def login(username, password):
if password == str(user_info['password'][find_pd_values([username],user_info,['user'])[1][0]]):
print(username +' welcome back!')
return True
else:
if find_pd_values([username,date],login_info,['user', 'date'])[0]:
error_loc=find_pd_values([username,date],login_info,['user', 'date'])[1][0]
error_count=login_info.ix[error_loc, 'error_count']
login_info.ix[error_loc, 'error_count'] = error_count+1
error_count +=1
print('密码错误,请重新输入!本日密码输错3次账号将被锁定,当前剩余输入次数为:',3-error_count)
writer = pd.ExcelWriter(login_info_filepath)
login_info.to_excel(writer)
writer.save
if error_count == 3:
if find_pd_values([username,date],lock_user,['user', 'date'])[0]:
print('系统错误!or 数据被篡改,锁定表已锁定账户:{username},不允许登录!'.format(username=username))
else:
lock_user.loc[len(lock_user.index)+1] = {'user': username, 'date': date}
writer = pd.ExcelWriter(lock_user_filepath)
lock_user.to_excel(writer)
writer.save
# return error_count
else:
error_count = 1
login_info.loc[len(login_info.index)+1] = {'user': username, 'date': date,'error_count':error_count}
writer = pd.ExcelWriter(login_info_filepath)
login_info.to_excel(writer)
writer.save
print('密码错误,请重新输入!本日密码输错3次账号将被锁定,当前剩余输入次数为:',3-error_count)
return False
user_info_filepath=r"D:\pythonStudy\mytest\登录\user_info.xlsx"
lock_user_filepath =r"D:\pythonStudy\mytest\登录\lock_user.xlsx"
login_info_filepath = r"D:\pythonStudy\mytest\登录\login_info.xlsx"
import pandas as pd
user_info = pd.read_excel(user_info_filepath)
lock_user = pd.read_excel(lock_user_filepath)
login_info = pd.read_excel(login_info_filepath)
date = time.strftime('%Y-%m-%d',time.localtime(time.time()))
counter=0
username = ''
while counter<3:
if username == '':
username=input("请输入用户名:")
else:
pass
if find_pd_values([username],user_info,['user'])[0]:
if find_pd_values([username,date],lock_user,['user','date'])[0]:
print("因您输入密码错误次数太多,账号被锁定,请明日再尝试登陆,不便之前请谅解谢谢!")
break
else:
password = input('请输入密码:')
result = login(username,password)
if result:
break
else:
username = username
counter+=1
continue
else:
username=''
counter+=1
if counter==3:
continue
else:
print("您输入的用户名不存在,请检查用户名或者先注册,谢谢!")
else:
print('输入错误!请稍后再试,谢谢!')
# password='123245'
# username='李四'
运行结果:


代码运行结果: