我的结果

销量最高
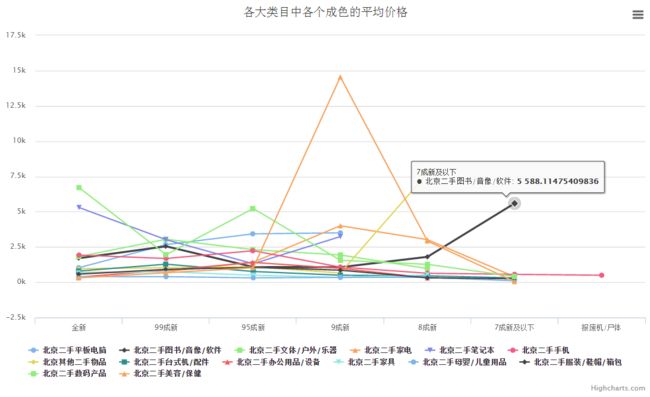
平均价格
我的代码
- 各个城区中,发帖量最高的三大类目
这一pa目前还没有找到可以批量处理的方法,除非把所有区域花在一张图表中……可那样太难看
# -*- coding:utf-8 -*-
import pymongo
import charts
client = pymongo.MongoClient('localhost',27017)
walden = client['walden']
item_info = walden['item_info']
def area_top3(area):
pipeline = [
{'$match':{'area':area}},
{'$group':{'_id':{'$slice':['$cates',2,1]},'counts':{'$sum':1}}},
{'$sort':{'counts':-1}},
{'$limit':3}
]
for i in item_info.aggregate(pipeline):
data = {
'name':i['_id'][0],
'data':[i['counts']],
'type':'column'
}
yield data
# 画图
series = [i for i in area_top3('朝阳')]
options = {
'chart':{'zoomType':'xy'},
'title':{'text':'朝阳'},
'yAxis':{'title':{'text':'数量'}},
'subtitle':{'text':'销量最高的三类商品'}
}
charts.plot(series, options=options, show='inline')
中间过程中的一些检查
area_set = set()
for i in item_info.find():
area_set.add(i['area'][0])
print(area_set)
# 打印结果如下:
{'通州', '宣武', '东城', '北京周边', '延庆', '西城', '海淀', '平谷',
'不明', '朝阳', '房山', '丰台', '密云', '门头沟', '昌平', '附近', '怀柔',
'大兴', '燕郊', '石景山', '顺义', '崇文'}
- 各大类目中,不同成色对应的平均价格
import pymongo
import charts
client = pymongo.MongoClient('localhost', 27017)
walden = client['walden']
item_info = walden['item_info']
def draw_line(ca, qua):
for cate in ca:
price = []
for qual in qua:
pipeline = [
{'$match':{'$and':[{'look':qual},{'cates':cate}]}},
{'$group':{'_id':'$look', 'average':{'$avg':'$price'}}},
{'$sort':{'average':-1}}
]
for p in item_info.aggregate(pipeline):
price.append(p['average'])
data = {
'name':cate,
'type':'line',
'data':price
}
yield data
# 画图
que = ['全新', '99成新', '95成新', '9成新', '8成新', '7成新及以下', '报废机/尸体']
options = {
'chart:':{'zoomType':'xy'},
'title':{'text':'各大类目中各个成色的平均价格'},
'yAxis':{'title':'价格'},
'xAxis':{'categories':[i for i in que]}
}
series = [i for i in draw_line(category, que)]
charts.plot(series, options=options, show='inline')
中间过程中的一些检查
# 检查“成色”内容
quality= set()
for i in item_info.find():
quality.add(i['look'])
print(quality)
# {'全新', '报废机/尸体', '9成新', '7成新及以下', '99成新', '-', '95成新', '8成新', '${info.paramsMap.oldlevel}'}
# 手动调整为重排顺序的列表
['全新', '99成新', '95成新', '9成新', '8成新', '7成新及以下', '报废机/尸体']
# 检查‘品类’
category = set()
for i in item_info.find():
category.add(i['cates'][2])
print(category)
# {'北京二手平板电脑', '北京二手图书/音像/软件', '北京二手文体/户外/乐器', '北京二手家电',
'北京二手笔记本', '北京二手手机', '北京其他二手物品', '北京二手台式机/配件',
'北京二手办公用品/设备', '北京二手设备', '北京二手家具', '北京二手母婴/儿童用品',
'北京二手服装/鞋帽/箱包', '北京二手数码产品', '北京二手美容/保健'}
# 经试验,列表化后删除“北京二手设备”(这一pa数据和其他差别太大)
category = list(category)
del category[9]
print(category)
# 最终
['北京二手平板电脑', '北京二手图书/音像/软件', '北京二手文体/户外/乐器', '北京二手家电',
'北京二手笔记本', '北京二手手机', '北京其他二手物品', '北京二手台式机/配件',
'北京二手办公用品/设备', '北京二手家具', '北京二手母婴/儿童用品', '北京二手服装/鞋帽/箱包',
'北京二手数码产品', '北京二手美容/保健']