【CVPR2018】ERFNet: Efficient Residual Factorized ConvNet for Real-time Semantic Segmentation
- 作者
![]()
- 摘要
语义分割网络可以端到端训练,并准确地在像素级对多种目标分类。本文提出一个可实时运行且结果准确的语义分割架构。本架构核心是一个新层,使用residual connections和factorized convolutions,得以保证准确和高效。在单卡Titan X可达83FPS,Jetson TX1(英伟达GPU开发板)可达7FPS。在公开数据集Cityscapes上准确率类似于sota,速度却有数量级的提升。
- 代码
https://github.com/Eromera/erfnet
- 介绍
自动驾驶中传统的基于视觉的方法,希望检测特定的目标,比如道路线、行人、车辆、交通灯、交通标示等。现在深度学习的发展允许在单独的语义分割中完成这些任务。
语义分割需要在图像中像素级标注类别,是一个具有挑战的任务。卷积神经网络起初用于分类任务,但在语义分割任务中也表现良好。但现在的sota方法无法兼顾性能和计算资源。
最近,卷积网络设计的新趋势残差层(K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” arXiv preprint arXiv:1512.03385, 2015.),能够使层数较多的网络避免退化,达到很高的准确率,在分类和语义分割的应用都取得了很高性能,但耗费巨大计算资源,只较小的提升了准确率。
Intelligent Vehicles (IV)需要算法可靠和实时,适用于嵌入式设备(空间限制),低能源消耗。因此,很多ConvNets去降低参数量,但也极大地降低了精度。
本文希望达到速度和精度的平衡,我们提出ERFNet (Efficient Residual Factorized Network),一个实时准确的语义分割卷积网络。架构的核心元素是一个新层,利用跳跃连接和1D卷积核。跳跃连接允许卷积层学习residual方程去促进训练的同时,1D 因子分解卷积能够极大降低计算消耗,并保持与2D卷积相同的精度。提出的block依次排列构建encoder-decoder结构,生成与输入相同分辨率的语义分割结果,如下图。
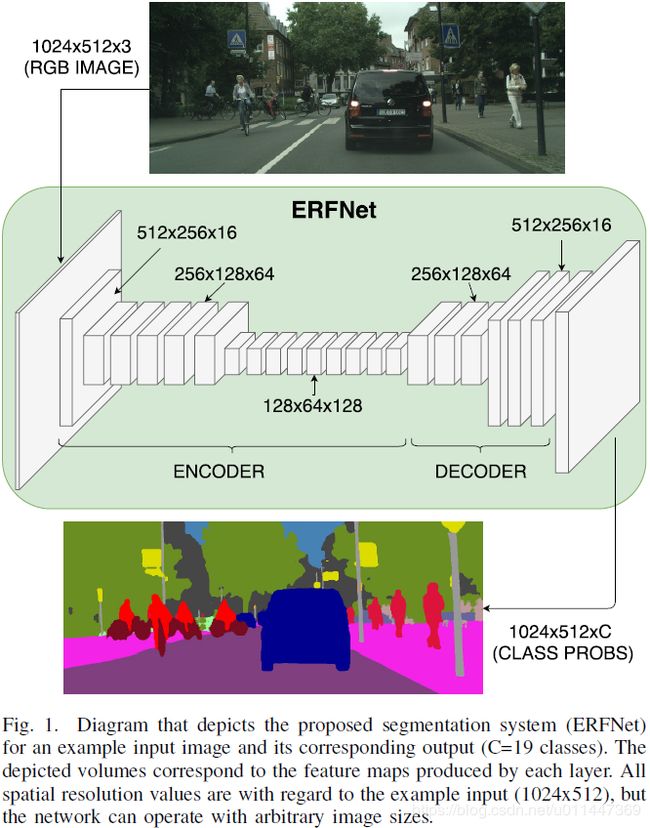
这篇文章是本篇会议文章的扩展(E. Romera, J. M. A´ lvarez, L. M. Bergasa, and R. Arroyo, “Efficient convent for real-time semantic segmentation,” in IEEE Intelligent Vehicles Symp. (IV), 2017, pp. 1789–1794.)更加详细地描述了提出的残差块和ERFNet整个架构,以及更全面的实验。
- 相关工作
FCN最先将分类网络VGG16用于端到端语义分割,将网络变为全卷积,并上采样了输出的特征图。但是,由于在分类任务中执行了较高的下采样以收集更多上下文,因此直接调用这些网络会导致像素输出粗糙,从而降低像素精度。为了优化这些输出,有人提出使用跳跃连接与浅层的特征图融合。
近期使用ResNet的工作获得了顶尖的语义分割准确度,核心是残差块,包含了从输入到输出的特性连接,以缓解深层网络中存在的退化问题。但是这些工作的计算量太大。
- 方法细节
为了提升架构效率,我们更加高效地运用参数,获得高分割准确度的同时满足IV的应用需要。
A. Factorized Residual Layers
残差层使得输出向量y和一个层向量输入x的关系为:
![]()
WS为特性映射,![]() 是要学习的残差映射。残差表示能够促进特征学习,并极大减缓网络结构层数太多造成的梯度消失问题。原始的残差网络提出两种残差层实例,如下图的a和b。二者参数量和准确性相似,但是bottlenet需要更少的计算资源,随着层数增加,这种做法更加经济。因此bottlenet设计更常用在sota方法中。但是据说non-bottlenect ResNets随着层数增加准确率更高,而且bottlenect仍然有退化问题。
是要学习的残差映射。残差表示能够促进特征学习,并极大减缓网络结构层数太多造成的梯度消失问题。原始的残差网络提出两种残差层实例,如下图的a和b。二者参数量和准确性相似,但是bottlenet需要更少的计算资源,随着层数增加,这种做法更加经济。因此bottlenet设计更常用在sota方法中。但是据说non-bottlenect ResNets随着层数增加准确率更高,而且bottlenect仍然有退化问题。
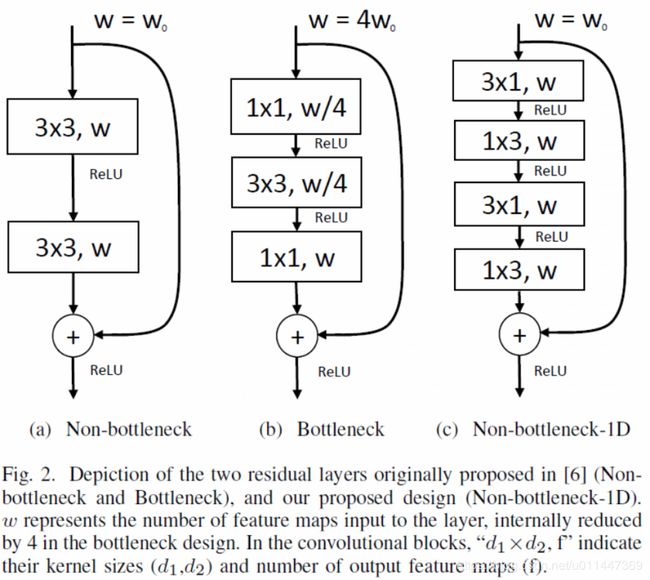
我们提出c模型,将a的2维过滤器表示为1维过滤器的组合。![]() 表示标准2维卷积层的权重,F是输出feature maps个数,
表示标准2维卷积层的权重,F是输出feature maps个数,![]() 表示每个feature map的kernel size,一般来说
表示每个feature map的kernel size,一般来说![]() 。
。![]() 是滤波器的偏置向量。
是滤波器的偏置向量。![]() 表示第i个核。常用方法首先根据数据学习这些滤波器,然后找到低秩数近似解作为后处理步骤。然而,这方法需要额外的finetune,并且结果滤波器不可分离。相反,有证明可以放松1秩约束,将滤波器作为1维滤波器的组合。可以降低计算损耗和复杂度,此外一维组合可提升模型紧密度,提升学习能力。一个二维滤波器d*d可分解为两个一维滤波器,用在3*3卷积可降低33%的参数量。
表示第i个核。常用方法首先根据数据学习这些滤波器,然后找到低秩数近似解作为后处理步骤。然而,这方法需要额外的finetune,并且结果滤波器不可分离。相反,有证明可以放松1秩约束,将滤波器作为1维滤波器的组合。可以降低计算损耗和复杂度,此外一维组合可提升模型紧密度,提升学习能力。一个二维滤波器d*d可分解为两个一维滤波器,用在3*3卷积可降低33%的参数量。
通过上述分解,我们提出一个新的残差层实现方案,使用一维因式分解来加速和降低参数量,称为“non-bottleneck-1D”(non-bt-1D)。快速、参数量少、保持学习能力和准确性。下表总结了各设计的权重维度。实验证明比bottleneck-1D更快。

虽然本文聚焦于分割任务,但提出的新设计可用于任何残差网络中,包括分类和分割架构。此外,本设计增加了网络“宽度”(可看做滤波器个数),同时保持最少的计算资源。
B. 网络结构设计
本文希望网络能最大可能的平衡准确率和高效。使用encoder-decoder结构,不同于FCN使用不同层的feature maps去融合一个细粒度输出,本文使用一种更有序的架构,encoder部分生成降采样特征图,随后的解码部分将特征图上采样到输入分辨率。本文没有使用encoder和decoder之间的远距离跳跃连接,因为经过实验对于提升准确率无效。
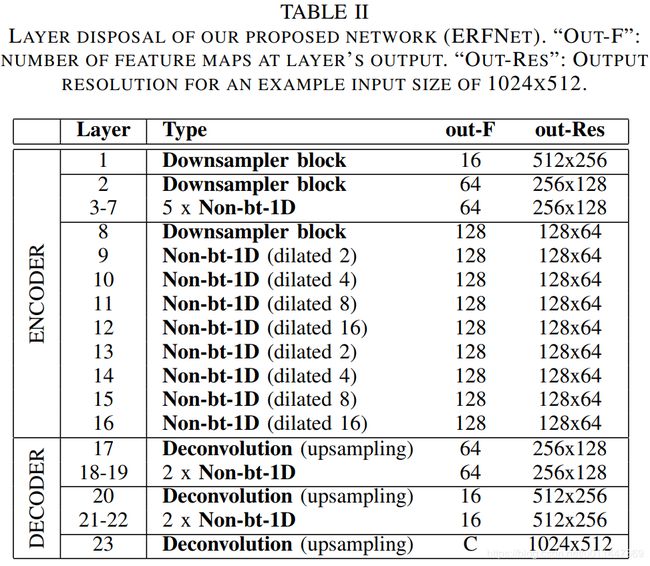
encoder为1到16层,由downsampling blocks和residual blocks组成。本文的downsampling blocks受ENet的初始化模块启发,如下图a所示。此外,本文也使用了一些膨胀卷积在non-bt-1D层,以便收集更多信息提升准确率。相比使用更大的核,膨胀卷积在计算量消耗核参数量方面更高效。我们将blocks的第二对3*1和1*3卷积使用膨胀一维卷积。在所有non-bt-1D层也使用Dropout,概率0.3。

decoder为了将特征图尺寸匹配输入分辨率,使用简单的反卷积stride为2。(为啥这么搞,没有为啥,实验结果好使,效率还高,炼丹呗,没什么道道)
- 实验结果
- 常规设置
使用Cityscapes数据集,城市场景图像集,常用于语义分割任务,有19类标注。IoU使用像素级评价,分类别计算。使用Torch7,adam优化的随机梯度下降。batch size为12,momentum为0.9,weight decay为2e-4,学习率初始为5e-4,训练错误率停滞时除以2。
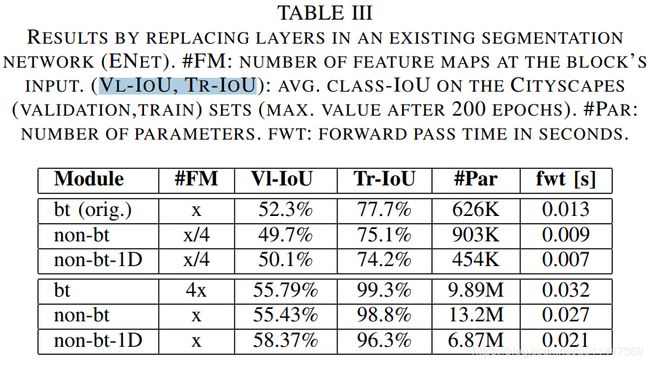
- 残差层比较
在ENet中替换三种残差层,比较训练结果。说明feature maps个数越高,模型的性能越高,让网络变宽是有效提升学习能力的方式。4倍的过滤器个数带来16倍的参数量增长。
- 架构评价
我们使用预训练策略,首先使用encoder的最后一层加上pooling层和全连接层,生成分类结果,然后用这个在ImageNet上训练过的encoder,再接上decoder训练语义分割任务。

- sota比较
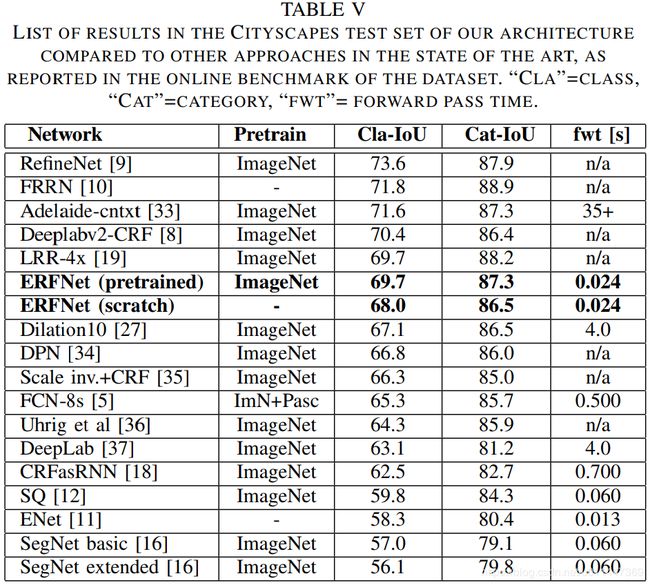
性能还行,主要是速度快,做到了性能和速度的最佳平衡。速度最快的ENet。
- 计算资源
640*360分辨率,在单片TitanX能达到83FPS;1024*512可达24ms(41FPS)。因此本网络能做到实时准确的语义分割。
- 分割性能
