共识算法Raft概论
Raft概论
- 共识算法解决的问题
- Raft起源
- 一切从Paxos说起
- 难于理解
- 没有提供工程实现细节
- Raft概览
- 主要流程
- 任期
- 角色转换
- Follower
- Candidate
- Leader
- 数据结构
- 日志结构
- 节点状态
- 选主流程
- 触发条件
- 投票请求
- Candidate发送投票请求
- Follower收到投票请求
- 选举可能结果
- 竞选成功
- 其他节点先竞选成功
- 超时无成功节点
- 日志复制
- 日志状态
- 复制过程
- 变更消息
- 示例
- 处理日志不一致
- 处理未提交日志
- 一致性证明
- 成员变更
- 过渡流程
- **新节点初始化**
- **Leader下线**
- 参考资料
欢迎来我的小站转转~~
分布式系统很大程度上解决了我们在单机系统上遇到的可靠性和扩展性问题。为了解决扩展性,引入了分片;为了解决可靠性,引入了副本。而引入的这两个机制,又带来了更多需要解决的刁钻问题。
在本篇文章中,笔者对分布式一致性算法Raft进行介绍。由于主要介绍大的结构和流程,所以称为“概论”。如果想要知道更多细节,可以下载参考资料中的内容进行更细致的研究。
本文结构:首先简要介绍共识算法可以解决那些问题;接着,对Raft算法的主要流程和数据结构进行概述;对Raft有一个整体印象后,聚焦于选主流程、日志复制中的细节和问题;最后,证明Raft算法的正确性,并描述Raft如何处理成员变更的问题。
共识算法解决的问题
简单来说,共识就是指多个节点对某个信息达成一致。
这里的“信息”可能是一个锁的持有者、集群的领导者、用户名是否注册过、银行账户的一个数值……如果多个节点对信息没有共识,就可能导致不同机器处理的结果不一致,在重要的场景下可能出现转账不一致等情况。
在下面就以简单主从复制的场景来介绍一下共识算法带来了什么样的保证吧~
简单主从复制是非常普遍的一种模式,就算是包括分片的场景下,每个分片也可以看成这样的数据流模式。在一个典型的主从复制系统中,一般都是如下图的从主节点复制到从节点。
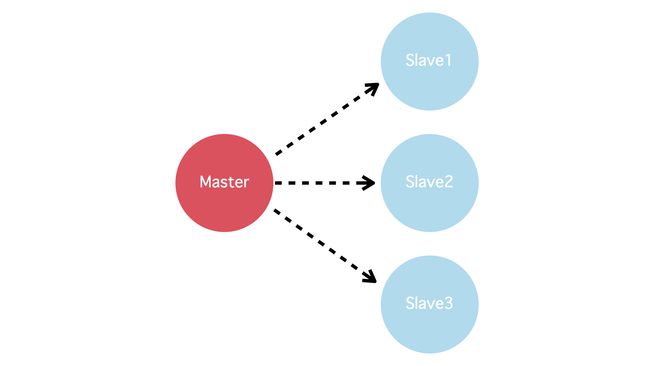
在这样的设计中,所有更改都在主节点上进行。一旦有故障切换等情况,可能选出过时的leader,导致已经写入的记录丢失;若有从节点与主节点的网络断开,又可能认为主节点失败,将自己提升为主节点,造成有两个主节点同时出现的脑裂现象。
共识算法可以在这样的场景下保证成功写入的记录在后面都不丢失,且同一时间最多只会有一个主节点。
除了选主场景,共识算法在分布式锁、唯一性保证、时序依赖等方面都可以提供很强的保证,本篇文章主要以kv存储的场景来描述Raft算法的细节。
由于本篇文章只是概论,笔者的能力也优先,难免挂一漏万。若有任何的问题或意见,欢迎在评论区进行探讨~
Raft起源
一切从Paxos说起
**There is only one consensus protocol, and that’s Paxos”. All other approaches are just broken versions of Paxos. **
By Mike Burrows(Google Chubby作者 )
正如Mike Burrows所说,Paxos 算法可以说是分布式共识算法的代名词,包括Raft在内的其他共识算法大都是在其基础上舍弃一些保证的变种。
那为什么有了Paxos之后大家不收收心,还继续在这基础上推出各种broken version的算法呢?2014年,Raft作者Diego Ongaro在他2014年的博士论文中解释了他观察到的Paxos两个主要缺点:
难于理解
由于Paxos的作者Lamport非常喜欢各种奇奇怪怪的比喻,完整的 Paxos 算法很难让人理解。Diego Ongaro 也是等读了一些 Paxos 算法的简化解释和开始开发自己的一致性算法时,才算真正掌握了 Paxos 算法,这个过程让一名高水平的博士足足花了一年时间。
没有提供工程实现细节
Lamport 的算法描述只提供了一个框架协议和理论上的严格证明,但是没有在工程上进行太多描述。开源社区几乎没有一个被广泛认可的工程实现,很多 Paxos 算法的实现都是对它的近似。这导致真正实现的工程化协议跟论文提及的协议总有或多或少的偏差,虽然Paxos的证明非常严格,但它的工程实现可能反而更没有理论保障。
正是以上两个问题,导致分布式共识算法的应用没有更加快速地铺开。Diego Ongaro在博士论文中提出了自己的简化版分布式共识算法Raft,希望能让共识算法更易于理解,且能快速正确地进行工程化。
Raft概览
主要流程
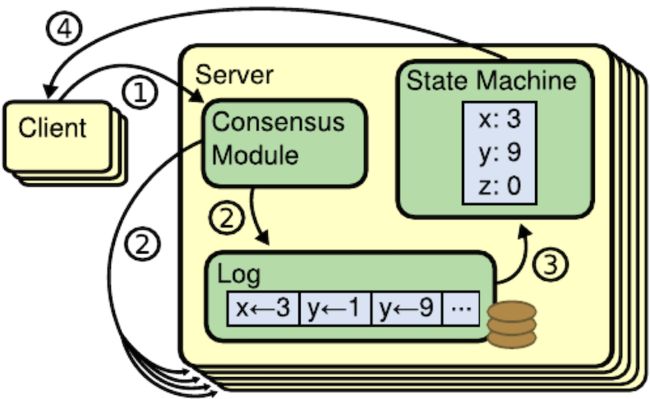
Raft的服务端是主从结构,每个副本都维护一个日志列表和状态机。其中日志是由共识模块维护的,状态机则是客户端可见的数据。所以在日志中存在但没有复制到状态机的那部分数据,对于客户端来说都是不可见的。
在这个例子中,数据都是简单的kv类型。共识模块是Raft算法的核心,通过控制Leader选举流程、日志顺序、通知状态机执行哪些日志来保证一致性。只要各副本日志的顺序一致,状态机的内容就是一致的。一次更改操作的主要流程为:
- client发送变更信息到Leader
- 共识模块保证发送到各个副本的日志是一致的
- 每台服务器上的状态机接收共识模块的通知,从日志中获取对应操作并执行
- 返回操作结果到client
其中client一开始可能将变更请求发送Follower上,Follower会告诉client哪个节点才是Leader,并让client向Leader发送变更信息。
任期
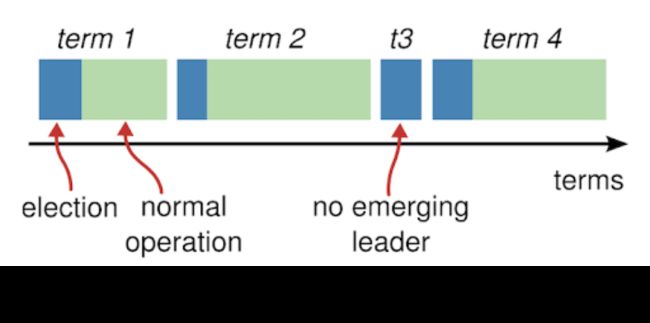
在Raft协议中,时间线被划分为不同的任期(term),每个任期内最多只有一个Leader。在上面的一个任期中,蓝色部分表示进行选举中,绿色部分表示已经选出leader,正在提供服务。不一定每个任期都能选出leader,比如t3阶段就没有选举成功。
角色转换
在Raft中,服务器的节点按照分为三种不同的角色:Leader、Follower、Candidate。
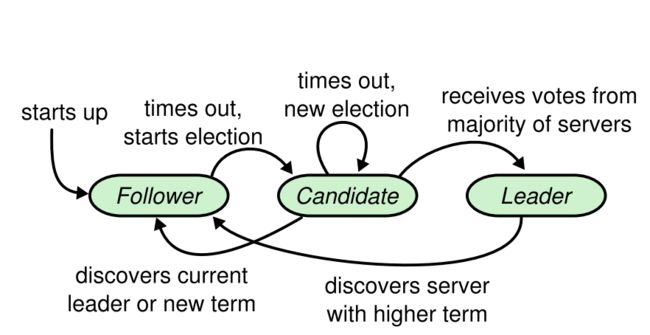
Follower
初始化时,所有的节点都是Follower,只能被动接受Leader和Candidate的消息,不能主动发消息给两者。从Leader处接收变更消息,并返回变更结果。从Candidate处接收到竞选消息,并返回自己是否同意选举其为Leader。
Follower返回的结果会带上当前的term,以供Candidate和Leader检查自己是不是已经落后。
Candidate
如果一个节点发现太久没有收到来自Leader的心跳,则会主动提名自己为候选的Leader,并发送选举的请求。在竞选结果没有确定之前,这个节点就是Candidate节点。
对于Candidate节点来说,如果竞选成功,它就会转变为Leader节点;如果竞选失败,则退回为Follower节点。
Leader
负责接收所有的更新请求,并将更新请求转发给Follower。同时,还会不间断的向外Follower发送心跳。当Leader发现自己落后,则会转变为Follower。
数据结构
在查看Raft算法之前,我们先来了解一下各个数据结构。
日志结构
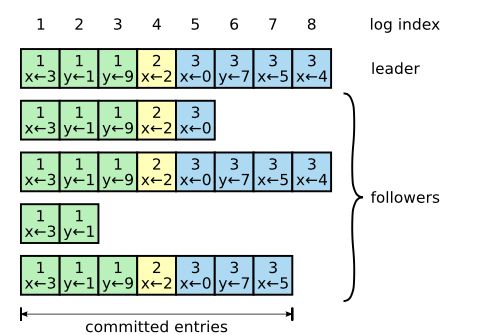
Raft中日志文件可以理解为一个单调递增的数组,数组中每个元素包含term和内容,表示一次客户端请求。其中term可以用于检查其他节点和自己的日志是否一致,内容表示请求的具体内容,一般是kv结构的值,每一个日志通过index表示它在数组中的位置。
在上图中,一共有三个term的记录。第一行的日志代表Leader中日志,下面四行则为Follower中的日志。其中索引1-7的committed状态表示一个日志已经复制到大多数节点,根据Raft的协议可以保证这个日志不会丢失,并最终复制到所有的节点上。
节点状态
Raft协议中每个节点都有一个State数据结构,用于保存节点的日志和状态等信息。为了保证节点重启后还能恢复状态,对于重要的字段都保证持久化,而其他可以通过节点间相互通信获取的信息则只需要存储在内存。

State数据结构包括:
持久化信息:
- CurrentTerm: 当前节点所在的任期,只要成为follower,就会将任期更新为leader的任期。
- VotedFor: 在当前任期内,当前节点投票给了哪个candidate
- Log[]: 日志列表,每一项包括term和内容两个信息
纯内存信息:
- CommitIndex: 表示已经复制到大多数节点的最新位置,在重新启动后可以通过节点之间互相通信重新算出最新位置。
- LastApplied: 应用到状态机的最新位置,同理,也可以通过互相通信算出来。
Leader特有的纯内存信息:
- NextIndex[]: 每一个follower最新的日志位置
- MatchIndex[]: 每个server和leader匹配的最大index, 默认为0. 处于matchIndex和nextIndex之间的日志就是哪些正在同步中的日志,是Leader已经向Follower发过去的AppendEntries消息还没有得到成功回应的日志列表
选主流程
触发条件
Raft协议通过超时时间来判断节点是否出问题:当Follower超过一段时间没有收到来自leader的请求时,就会认为现在Leader出了问题。
这时候leader可能真的出了问题,也可能只是过于繁忙或网络出了问题。无论如何,Follower都会主动转变为candidate,自增当前节点的term,并且尝试向其他节点发送请求。
投票请求

投票请求包括:
- Term: 当前(candidate)节点的任期,值为之前term+1,表明自己是下一个term的竞选者
- CandidateId: 当前(candidate)节点的id
- LastLogIndex: 当前(candidate)日志的最后一条记录的位置
- LastLogTerm: 当前(candidate)日志的最后一条记录所在的任期
投票返回结果:
- Term: 收到投票请求的节点当前任期
- VoteGranted: 对应节点是否投票给当前candidate
Candidate发送投票请求
一旦判断leader出了问题,Follower就认为应该进入下一个term,进行如下操作
- 首先更新当前term,自增,状态变为candidate
- 投票给自己,更新votedFor
- 发送投票请求给所有的server,等待过半成员同意自己成为新leader
Follower收到投票请求
Follower收到投票请求后,会进行如下操作:
- 判断candidate的term是不是更新,如果比自己term还小,则直接返回false
- 检查自己的votedFor字段,如果当前任期已经投给其他人了,则返回false。这一步保证了同一个任期内Follower只会投票给一个节点
- 到这一步,说明candidate的term是更新的,且当前节点还没有给其他人投票过,通过lastLogIndex和lastLogTerm检查candidate的日志是不是比自己更新。如果candidate更新,则返回true;否则,返回false。
- 这里判断两个日志是否更新的规则是:首先比较lastLogTerm,term越高的日志越新;如果lastLogTerm相同,则lastLogIndex越大的日志越新。
选举可能结果
投票的结果可能有以下几种情况:
竞选成功
每个节点会给新任期的第一个符合要求的candidate投票。如果candidate收到过半的节点都返回true,就认为自己赢得了竞选,转换状态到leader,并马上持续发送心跳给所有的节点以维持自己的leader地位,避免其他节点也跳出来竞选leader。
其他节点先竞选成功
如果在等待过半节点同意的过程中,收到了来自其他Server的心跳或变更信息,且这个信息中携带的term不比自己的任期小,说明已经有其他的节点赢得选举,自己再怎么等待也不可能有半数的同意。此时Candidate就转换状态为Follower,将term更新为心跳中的term,以开始接收leader发布的命令。
超时无成功节点
还有一种情况是没有一个节点成功,比如同时有三个candidate发起投票请求,没有一个candidate获得过半的支持。在这种情况下,candidate如果发现超过一段时间都没有成为leader,会自动进行下一次选举,直到自己成为leader或收到来自其他leader的心跳。
日志复制
日志状态
从发送请求到成功更新在所有节点上,一个日志可能有很多状态。Raft提供的保证是:一旦日志复制到大多数节点,那么就不会再丢失。只要不会再丢失,这个变更日志就可以在状态机中执行,从而被客户端看到。
回顾一下节点状态的数据结构,为了判断一个日志目前在什么状态,Raft引入了两个日志状态:Commited和Applied:
-
Commited:日志已经在过半的节点上持久化,则状态为committed,这时候可以认为日志不会再丢失。
-
Applied:日志已经在状态机上执行,能被客户端读取到。
Raft要求必须在前面的日志全都没问题的情况下才能处理后一个日志,所以不需要为每一个日志项都维护一个日志状态,只需要通过commitIndex记录最新的已经commited的日志,通过lastApplied记录最新的已经执行、客户端可见的日志。在commitIndex和lastApplied之前的状态必然都已经是committed和applied。
在上图的日志状态中,一共有五个节点。
对于leader来说,从索引1到7的日志都已经复制到过半节点,所以commitIndex即为7,表示前7项日志都可以安全地在状态机中执行。假设已经将前6项日志执行完成,那么leader的lastApplied即为6。
对于第一个follower来说,它相对于leader有一些延迟,最新的日志只到位置4。所以它的commitIndex可能为4,lastApplied则可能是4或者更之前的值。
复制过程
正如 Raft概览 中所描述的,client的请求都会发送到Leader中。Leader将请求追加到本地日志后,发送追加命令到Follower中,如果有Follower执行失败,则Leader会不断尝试直到成功。只要过半的Follower返回追加成功,leader就可以更新commitIndex为这个日志的索引,标记这个日志已经成功持久化。并安全的通知状态机执行对应日志,更新lastApplied,这样client就能看到这个变更。
为什么过半节点追加成功很重要嘞?回顾一下选主流程:如果一个没有追加成功的节点成为candidate,过半的节点在进行投票的时候会发现它的lastLogIndex比自己还要小,因此拒绝选它为主节点。所以一个节点能成为主节点的前提就是它是那过半的节点之一,从而保证了过半成功的日志在今后所有的选举中都能保留下来。也是由于这样的链式判断,只要两个服务器某一个index下的日志term相同,那么之前所有的日志都是一致的。
日志成功持久化之后,Leader发出的心跳就会包含更新的commitIndex和lastApplied。通过这两个字段,Follower能够知道日志已经可以安全的持久化了,就会对应更新commitId,并将旧lastApplied到新lastApplied之间的日志执行到状态机。
在Raft中,为了数据结构尽量精简,使用内容为空的变更消息作为心跳消息。所以心跳消息和变更消息的数据结构都如下一小节所示。
变更消息
变更消息只会由自认为是Leader的节点发出,至于Follower认不认这个节点为Leader则是另一回事情。如果Follower发现这个Leader比自己更落后,则不会执行对应的命令。

变更消息请求数据结构:
- Term: 当前(leader)节点的任期,通过这个字段可以让Follower判断当前节点是不是更落后
- LeaderId: 当前(leader)节点的id,这样可以让落后节点或新节点知道当前leader是谁,这样client在进行变更操作的时候,Follower就可以告诉client谁才是Leader
- PrevLogIndex: 当前日志之前一个位置的index,可以让Follower判断当前节点日志是否与其一致
- PrevLogTerm: 当前(leader)日志中最新消息的Term,可以让Follower判断当前节点是否与其一致
- Entries[]: 此次变更的消息(为了性能考量,一次可能有多个消息),如果是heartbeat,则是空内容。
- LeaderCommit: 当前(leader)节点状态机最新执行到的位置
变更信息返回:
- Term: follower当前的任期
- Success: 消息是否执行成功
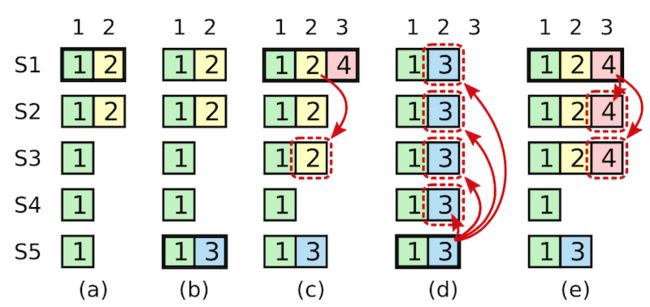
示例
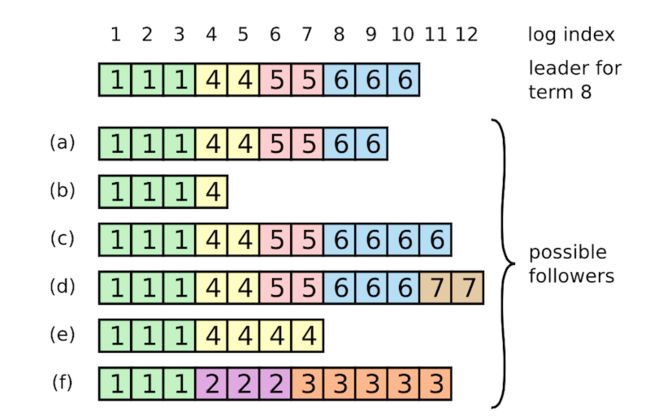
上图就是一种简单的日志可能情况,其中包括一台现任Leader和6台Follower (a)-(f)。探究过程可以更清楚选举和复制的细节,但也相当耗费时间。如果想尽快有个概览的话,可以直接跳过示例。为了增进大家的理解,笔者在过程中引入了魔法背景(单纯为了搞笑来的):
- 在很久很久以前的term1,节点(a) 是统领所有节点的leader,它不断向其他节点发送心跳,维持着自己的Leader地位。
- 在term1期间,魔仙堡收到了来自客户端的三个变更请求,(a)节点成功把三个请求日志复制到所有的节点,客户端也收到三条变更执行成功的结果。
- 由于魔法波动,(a) 和大家临时失去了联系,虽然不久即恢复,但距离上一次心跳已经过了足够长时间,在此期间剩余节点进行了一次新的选举。
- 节点(f) 成为了term2的leader,并收到三条请求。无奈(f)刚成为leader,网线就黑魔仙拔了,其他节点根本没来得及收到这三条消息。在客户端看来,这三条变更没有被成功执行。
- 巴啦啦小魔仙识破了阴谋,又把网线接回去了。(f) 凭借最新的lastLogIndex和lastLogTerm,成功连任term3的leader,并收到五条term3的请求。天不遂人愿,网线又被剪断,新收到的五条请求也都没有被发出去。由客户端发送的五条新消息又更新失败,(f) 节点则陷入了长眠。
- (e) 节点看不下去,背负魔仙堡的期望成为了term4的leader。
- (e)节点收到客户端的两条请求,它兢兢业业将term4的第一个请求复制到除(f)外所有的节点上,第二个请求也复制到(b)和(f)之外的所有节点,均实现了过半复制。所以客户端收到了term4前两条变更执行成功的结果。
- 正在(e)节点不断要求(b)和(f)学习其他节点,更新到最新日志时,它的网线也惨遭毒手。但客户端此时还不知道(e)的遭遇,继续向它发送了两条变更请求。(e)在更新了本地日志后,却发现也联系不上外界了,只能眼睁睁看着其他节点举行新的竞选。
- 其实(b)节点在更新第二条请求的时候就已经被黑魔法波及,可怜的它在没人注意的角落被冻成了冰冻服务器。
- 此时还能联系到的节点只剩4个,它们分别是(a)、©、(d)和现任Leader。魔仙堡不可一日无魔仙王,(a)节点挺身而出竞选term5的Leader。©、(d)、现任Leader当然全力支持,于是(a)节点成为term5的Leader。
- 不愧是term1曾经的Leader,(a)节点在收到客户端两个新的变更请求后,又将日志成功复制到四台存活的节点中,并返回客户端变更成功的消息。
- 但是(a)的老毛病又犯了,它身上的魔法扰动越来越强烈,一不小心又没有及时发送心跳包。
- 见(a)又没有及时发送心跳,©节点认为还是自己来做Leader比较合适,便主动发起了新一轮term6的投票。(d)节点和现任Leader发现©节点的日志状态是最新的,便同意它出任新的Leader。等(a)节点反应过来的时候,已经收到了©节点的投票消息。既然©节点的日志状态和自己一样新,那让它当Leader也一样!所以©节点也投出了同意票。拿到了4个节点的支持票,©节点已经取得7个节点中的过半票数,成功当选term6的Leader。
- 客户端又发来了四个变更请求,节点©将这四个日志保存在本地后,不断发送给剩余的节点让其更新。除了无法应答的三个节点,剩余的四个节点或多或少的执行了新的变更消息。
- ©节点还是难逃魔咒,在一个时间点它也没能成功让所有节点成功收到心跳。在举办下一次选举的时候,客户端知道四个变更中的前两个已经成功执行,后两个变更则不一定成功。
- ©节点忙着让其他节点执行变更时,已经收到来自(d)节点的投票请求。但由于©节点的日志比(d)节点更新,©节点并不同意让(d)成为Leader。正当(d)节点一筹莫展时,默默无闻的(b)节点突然解除了冰冻魔法!一觉醒来的(b)节点也收到了(d)的投票请求,既然日志比自己新,term也比自己高,(b) 毫不犹豫地投了赞成票,(d)节点成功当选了term7的Leader。
- 客户端的消息又来了,这次是两个变更消息,(d)节点开心的将这两个消息添加到本地的日志,正要发送到其他节点时,断电了…
- 此时(e) 和 (f) 也从长眠中苏醒过来了
- 终于,现任Leader出场了。它发现(d)节点好久没有发心跳消息了,就提出新一轮竞选。这一次,它的状态比除了©和(d)之外的其他节点都新,成功获得了5个投票,成为了term8的leader。
以上就是八代目魔仙王的上位史,如果你读完了上面的过程,请先为自己的耐心点18个赞。
处理日志不一致
So far so good! 在这个完美的流程中谁都不会出错或断线。但要是世间的事这么简单,我们的 Diego Ongaro 何必写他那400多页的博士论文呢?
我们现在知道这种情况是可能发生的,那么Raft使用什么样的机制,让所有节点的日志状态最终都一致呢?
在Raft中,leader会强行要求Follower与自己的日志完全一致,如果有冲突则以leader为准。在leader发送消息到Follower的时候,会附带prevLogIndex和prevLogTerm,表示当前消息之前一个消息的位置和term。
-
如果Follower发现自己prevLogIndex上的日志term与这prevLogTerm不匹配,说明当前的log和leader的log并不一致,返回false。
-
Leader发现不一致之后会尝试将更早的消息发送出去,不断重复直到Follower对应位置的日志term与leader一致
-
Follower检查发现对应位置的前一个日志匹配,就会将本地对应位置的的日志覆盖为leader发来的值,并返回true。
-
Leader收到追加成功的消息,不断增加index,直到所有的消息都成功同步到Follower
在这个例子中,对于现任Leader,会将(a)、(b)、(e)、(f)的旧数据全部覆盖到和自己一致,且如果有后续term=8的日志,©和(d)中位置为11和12的日志也会被覆盖。因为这些日志都没有复制到过半的节点,所以不可能应用到状态机上,就算被覆盖也不会产生实质影响。
以(f)为例,它与Leader的同步过程可能经过下面的过程:
第一步:回顾 变更消息 ,Leader使用内容为空变更消息作为心跳消息,向 (f) 发送心跳时,会带上最新的prevLogIndex和prevLogTerm,目前最新的prevLogIndex=10,prevLogTerm=6。
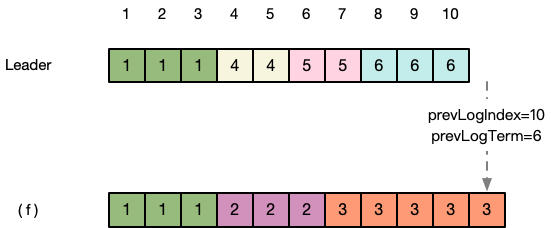
第二步:(f) 发现本地位置10的term为3,小于Leader发来的prevLogTerm,返回fasle,表示与Leader不一致。
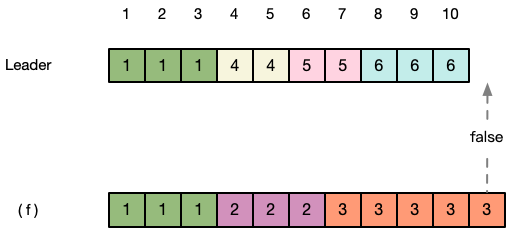
第三步:Leader收到 (f) 返回的false,知道在位置10的日志还没有与自己一致。于是更新 节点状态 中(f)节点的nextIndex为9,继续向(f)发送prevLogIndex=9,prevLogTerm=6的消息。
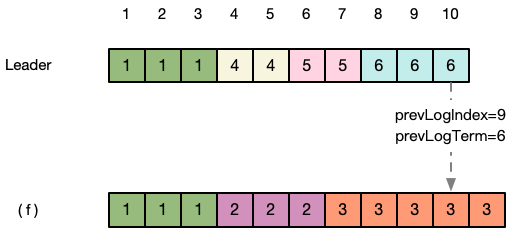
第四步:(f) 继续检查位置9的term,发现仍然与Leader不一致,返回false。
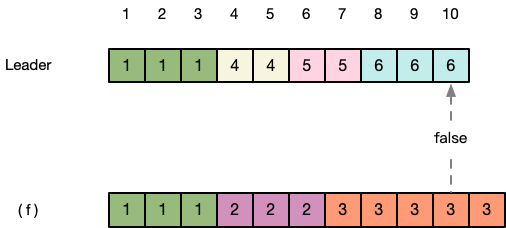
第五步:Leader继续发送更向前日志的index和term。
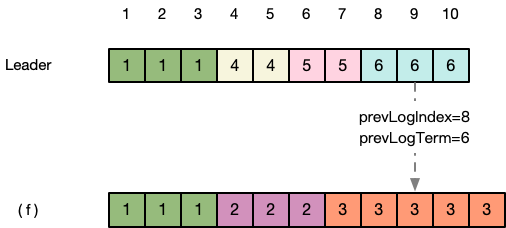
第六步:依此方式,不断前溯。直到 (f) 在prevLogIndex=3的地方,prevLogTerm=1 与Leader一致
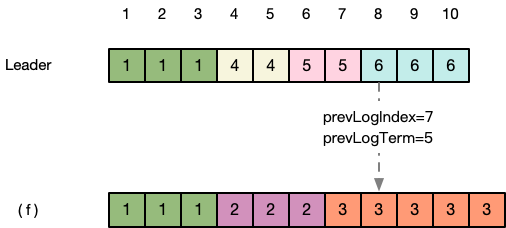
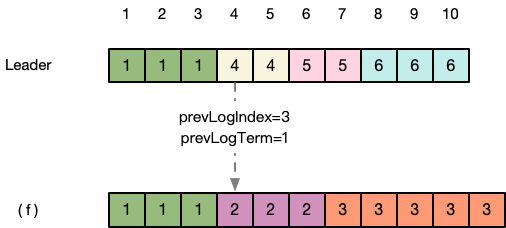
第七步:(f) 发现此时发来的新消息prevLogIndex=3,prevLogTerm=1与Leader一致。于是认为Leader发来的这个消息可以应用到日志中,清空了后面的日志后,将index=4处的日志与Leader同步,返回success。
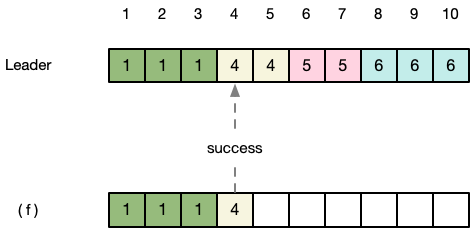
第八步:Leader收到success的消息,知道(f)已经将index=4的日志与Leader同步,于是更新nextIndex数组中(f)的位置更新为5,并将位置为5的日志变更发送到(f)。
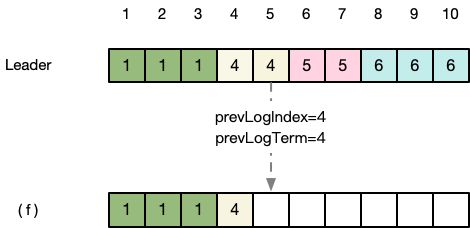
第九步:(f)继续与Leader同步,返回suceess。
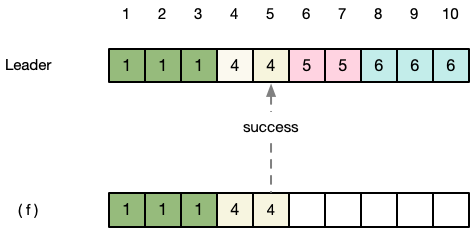
继续如此n步,直到(f)与Leader的日志状态同步,在Leader的nextIndex数组中(f)的位置已经为最新的11。
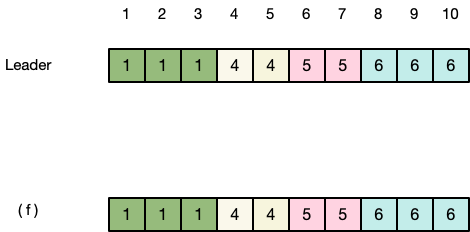
处理未提交日志
如果一个leader将日志复制到过半机器之后,在本地已经更新commitId且apply到状态机,但其他几台机器还没有通过心跳接收到通知,那在下一轮选举后,新的leader可能并不知道之前term的日志是否已经commit。考虑以下场景:
在如上的场景中,各阶段可能的情况如下
A) S1是term2的leader,并且成功将日志复制到S2上
B) S1挂了,S5成为term3的leader,并且收到新的变更请求
C) S5挂了,S1重启并成为term4的leader,接收到新的变更请求,继续将之前的日志复制到S3上,这时候term2日志已经过半,S1放心地提交了term2的日志。
D) 如果此时S1又挂了,S5又一次选举成为term5的leader,开始将自己之前的日志复制到所有的服务器上,覆盖了已经复制到大多数的term2和term4日志。这就导致S1上已经commit的term2日志被覆盖了,违反了已经commit的日志不能被覆盖的规则。
E) 如果在C)的情况中,S1已经将term4的日志复制到过半机器,那么S5就不可能当选为leader,因为S5的lastLogTerm比term4更小,不可能拿到过半支持。
为了避免D中的情况,Raft规定leader只能commit当前term的日志,如果Follower发现新的commitId之前有未apply的日志,会一起apply到状态机。以图C为例,S1在复制term2日志时不会更新commitId,只有term4复制到大多数之后才会更新commitId。Follower收到新的commitId之后,会将term2和term4日志一起apply到状态机。
这么做之后,可能有以下情况:
-
一切顺利,term2和term4成功在大部分节点上commit并apply
-
S1在更新commitId到term4,将term2和term4日志apply到状态机之后挂掉,其他Server还没有更新commitId。此时过半的Server必然都已经更新了term4日志,下一个leader必然不会丢失已经apply的日志。
-
Term2已经过半,term4还没有过半,S1的commitId没有更新,term2和term4也没有被状态机Apply。
- 此时可能让不包含term4的S5成为leader,并覆盖掉term2和term4。但是由于term2和term4没有在任何状态机上apply,所以不会违反规则,不会导致问题。
- 此时也可能让包含term4的S2成为leader,S2会在自己的term有新日志提交到过半机器之后,更新commitId,并apply到机器。这时候其他的机器也会apply term2和term4。
- 如果3.2中,client不再提交任何的请求,则term2和term4可能永远只会在S1的状态机上apply。和3.1一样,不会造成实质影响。
一致性证明
本小节主要证明Raft算法的正确性,如果对于逻辑证明没兴趣的话,可以直接跳过~
首先回顾一下,Raft提供如下保证:
-
选举安全:一个任期内最多只有一个节点被选为leader(抽屉原理,但可能有两个任期同时存在,此时老任期的节点日志永远不可能被apply)
-
Leader的追加型日志:leader的日志只会在后面追加新内容,不会删改已有的内容
-
日志匹配:如果两个副本包含index和term都相同的日志,那么在这个index之前的所有日志都是匹配的(通过日志复制规则保证)
-
Leader完整性:如果一个日志在某个任期被commit了,那么在之后所有任期的leader中,这个日志都保证存在。
-
状态机安全:如果一个服务器将某个index下的日志执行到状态机了,那么所有服务器在这个index下都只可能执行那一条日志。
迄今为止的流程,能不能保证每一台状态机上的顺序都是一样的呢?
使用反证法进行证明:
如果第四条leader完整性不成立,那么我们可以推导出矛盾,反正第四条是成立的。
设term T的Leader commit了一个当前任期的日志,但是这个日志没有被后面term的leader存储。设不再存储这个日志的leader的最小任期为U。
-
已提交的日志肯定在选举的时候就不在 l e a d e r U leader_U leaderU 里面
-
l e a d e r T leader_T leaderT 肯定已经将日志复制到大部分节点上,否则日志不会被commit。由于后面 l e a d e r U leader_U leaderU 被选举为leader,所以一定有一个机器既收到了日志,又给 l e a d e r U leader_U leaderU 投票了。
-
投票者一定是先收到日志,再进行投票的。否则它一定会因为投票规则拒绝给leader_U投票。
-
这里就导出矛盾,由于投票给candidate的前提是candidate的日志至少比当前日志更新,为了拿到过半投票,candidate必须包含被提交的日志。又因为leader不会删除自己的日志,所以被提交的日志一定在任期U存在,与题设矛盾。
证明了第四条之后,我们就可以证明第五条:
一旦一个服务器将日志apply到状态机,这个日志和之前的日志必然都已经和leader一致,且日志已经被commit。那么今后的leader必然包含这个日志,所以今后所有节点收到的日志必然跟已经apply的日志一致。
成员变更
过渡流程
之前的讨论都基于节点不变的情况进行,由于不同服务器的配置更新时间必然有差异,有导致脑裂的可能(两个节点都认为自己获得了过半支持)。
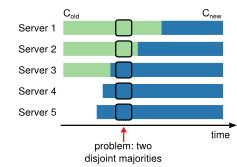
为了保证安全,节点更新的过程必须使用两阶段提交。cluster首先切换到一个过渡的状态,在过渡状态中包含新旧两个节点集合(有节点同时在两个集合中)
-
在过渡阶段中的请求都会同时提交到新旧集合中的服务器
-
在两个集合中的服务器都可以竞选为leader
-
一个commit需要新旧两个集合中均达到过半服务器的复制
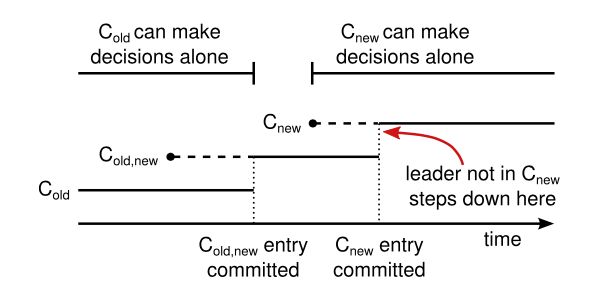
当leader收到更改节点配置 C n e w C_{new} Cnew 之后,将会把合并配置 C o l d , n e w C_{old,new} Cold,new 作为一个特殊的日志发布到新旧节点中。一旦一个节点收到 C o l d , n e w C_{old,new} Cold,new ,它就会使用新的服务器列表。 这之后如果在 C o l d C_{old} Cold 中的服务器挂了,新的leader可能在 C o l d , n e w C_{old,new} Cold,new 或者 C o l d C_{old} Cold 中产生,这时候单凭 C n e w C_{new} Cnew 中的节点还不能单方面做决定。
一旦 C o l d , n e w C_{old,new} Cold,new 被commit,就保证了只有收到 C o l d , n e w C_{old,new} Cold,new 的节点可以被选举为leader。这时候创建一个 C n e w C_{new} Cnew 消息就是安全的,因为leader知道 C o l d , n e w C_{old,new} Cold,new ,消息会保证复制到 C n e w C_{new} Cnew 中的大部分节点。所有节点收到 C n e w C_{new} Cnew 之后就会使用 C n e w C_{new} Cnew 的配置,一旦 C n e w C_{new} Cnew 中过半的机器都收到配置,那么把不再需要的 C o l d C_{old} Cold 节点下线就不会有任何问题,因为以后leader必然从 C n e w C_{new} Cnew 中产生,新的日志在 C n e w C_{new} Cnew 中也必然需要过半才能commit,符合条件。
新节点初始化
在配置更改之前,所有节点需要首先保证自己的log能跟上当前进度。所以节点在启动时首先成为没有投票权的节点,被动接收leader的日志,直到日志同步完成才会开始以上的配置变更流程。
Raft协议中有相应的快照模块,此处不再展开。
Leader下线
如果leader不是 C n e w C_{new} Cnew 中的成员的话,一旦 C n e w C_{new} Cnew 被commit,leader就会主动下线。
参考资料
文末列出了Raft算法的论文《In Search of an Understandable Consensus Algorithm(Extended Version)》,本文的大部分配图都来自于论文,如果配合原文来看,相信可以对包括日志压缩、快照等在内的细节有更清楚的理解。
如果想要查看更多的示例,可以登录文末列出的 可视化网页,这是一个github上的项目,专门为了学习Raft算法而创建,其中的例子生动形象,很利于理解。
工程上,有名的ectd即基于Raft,与之有类似功能的ZooKeeper则使用了另一种共识算法Zab。如果想要对包括Paxos、Zab、Raft在内的共识性算法和工程有系统的了解,可以参考Raft作者的博士论文《CONSENSUS: BRIDGING THEORY AND PRACTICE》。
最后,如果你对自己写一个Raft实现感兴趣,可以看一下MIT的《分布式系统》公开课 6.824,其中Lab2即为Raft的工程实现,有兴趣可以一起探讨作业答案哈~
参考资料与网站
Raft论文:https://raft.github.io/raft.pdf
Raft算法可视化: http://thesecretlivesofdata.com/raft/
Raft作者的博士论文《共识: 连接理论与实践》: https://web.stanford.edu/~ouster/cgi-bin/papers/OngaroPhD.pdf
MIT分布式系统公开课6.824: https://pdos.csail.mit.edu/6.824/schedule.html