pytorch基于RNN实现文本情感分析并用C++加载模型预测
文本情感分析是机器学习自然语言处理NLP中常见的应用场景,给定一段文本,识别其中的情绪或态度,对其进行分类并标签化。这个手段可以应用于书籍电影评价、用户对产品满意度调查、人机对话感情色彩提取和金融研报分析。
本文以美国IMDB电影网站的评论数据为例,用pytorch构建和训练基于循环神经网络LSTM的模型,然后用C++ libtorch加载模型对于给定的电影评论文本进行预测,判断改评论是正面的还是负面的,代码和数据实例参考了动手学机器学习pytorch版
环境
开发工具
- windows7/ubuntu16.04
- vs2017/gcc5.4
- pytorch1.5 (cpu version)
- libtorch1.5 (cpu version)
依赖项
在python环境需要安装
- pytorch
- torchtext
准备数据
预先下载好以下数据集
- 电影评论数据aclImdb,地址:http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
- glove 6B预训练语料库词向量,地址:https://nlp.stanford.edu/projects/glove/
模型训练
主要是用python代码加载数据,训练和导出模型
先引入用到的所有包
import os
import time
import random
import collections
import tarfile
import torch
from torch import nn
import torchtext.vocab as Vocab
import torch.utils.data as Data
from tqdm import tqdm
# settings
kDevice = "cpu"
kDataDir = "data" # put in the current directory加载和处理数据
# read data
def readImdb(data_dir, part_folder):
text_data_list = []
# pos and neg are sub folders and show the label info
for label in ["pos", "neg"]:
folder_path = os.path.join(data_dir, "aclImdb", part_folder, label)
for file in tqdm(os.listdir(folder_path)):
with open(os.path.join(folder_path, file), "rb") as f:
movie_review = f.read().decode("utf-8").replace('\n', '').lower()
text_data_list.append([movie_review, 1 if label == "pos" else 0])
random.shuffle(text_data_list)
return text_data_list
train_data, test_data = readImdb(kDataDir, "train"), readImdb(kDataDir, "test")
# pre process data
def tokenizer(text):
return [tok.lower() for tok in text.split(' ')]
def getTokenizedImdb(data):
# data: list of [string, int]
return [tokenizer(review) for review, _ in data]
def getImdbVocab(data):
tokenized_data = getTokenizedImdb(data)
counter = collections.Counter([tk for st in tokenized_data for tk in st])
return Vocab.Vocab(counter, min_freq=5) # filter out the words count less than 5
vocab = getImdbVocab(train_data)
def pad(x, max_len):
return x[:max_len] if len(x) > max_len else x + [0] * (max_len - len(x))
def preprocessImdb(data, vocab):
max_len = 500 # pading to 500 words for each review
tokenized_data = getTokenizedImdb(data)
features = torch.tensor([pad([vocab.stoi[word] for word in words], max_len) for words in tokenized_data])
labels = torch.tensor([score for _, score in data])
return features, labels
batch_size = 64
train_set = Data.TensorDataset(*preprocessImdb(train_data, vocab))
test_set = Data.TensorDataset(*preprocessImdb(test_data, vocab))
train_iter = Data.DataLoader(train_set, batch_size, shuffle=True)
test_iter = Data.DataLoader(test_set, batch_size)- 将数据下载放在指定目录
- 将文本里每个单词转成索引
- 按照标签分成不同的部分
- 建立语料库
定义模型
每个句子拆成词向量,传入嵌入层,使用嵌入式词向量。通过嵌入层后传入LSTM,这是个双向的神经网络,最后经由线性层输出
其中LSTM如下
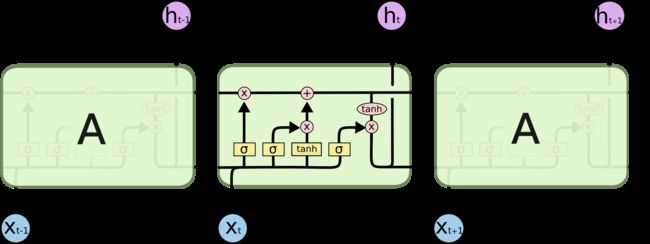
class TextRNN(nn.Module):
def __init__(self, vocab_len, embed_size, num_hiddens, num_layers):
super(TextRNN, self).__init__()
self.embedding = nn.Embedding(vocab_len, embed_size)
# bidrectional lstm
self.encoder = nn.LSTM(input_size=embed_size,
hidden_size=num_hiddens,
num_layers=num_layers,
bidirectional=True)
# full connect layer
self.decoder = nn.Linear(4 * num_hiddens, 2)
def forward(self, inputs):
# inputs shape: (batch_size, words_len)
# inverse inputs and fetch the attributes, outputs shape: (words_len, batch_size, word_vec_dim)
embeddings = self.embedding(inputs.permute(1, 0))
outputs, _ = self.encoder(embeddings)
encoding = torch.cat((outputs[0], outputs[-1]), -1)
outs = self.decoder(encoding)
return outs
# build a 2 hidden layer bidirectional nural network
embed_size, num_hiddens, num_layers = 100, 100, 2
net = TextRNN(len(vocab), embed_size, num_hiddens, num_layers) # make sure the model args are convienient for C++- 输入形状适配语料库的尺寸
- 包含嵌入层、LSTM层、线性层
添加预训练词向量
数据集不是很大,为了防止过拟合,这里直接用更大规模语料库预训练好的词向量。
def loadPretrainedEmbedding(words, pretrained_vocab):
embed = torch.zeros(len(words), pretrained_vocab.vectors[0].shape[0])
oov_count = 0 # out of vocabulary
for i, word in enumerate(words):
try:
idx = pretrained_vocab.stoi[word]
embed[i, :] = pretrained_vocab.vectors[idx]
except KeyError:
oov_count += 1 # ?
if oov_count > 0:
print ("there are %d oov words" % oov_count)
return embed
net.embedding.weight.data.copy_(loadPretrainedEmbedding(vocab.itos, glove_vocab))
net.embedding.weight.requires_grad = False # pretrained data no need to udpate- 如果在线下载困难,可以将预训练数据放在指定目录然后通过缓存加载
- 有一些不在预训练集合里面就剔除
训练
# train
def evaluate_accuracy(data_iter, net, device=None):
if device is None:
# if not specified device, use net device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
net.eval() # eval mode will close dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # back to train mode
n += y.shape[0]
return acc_sum / n
def train(net, train_iter, test_iter, batch_size, loss, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, batch_count, start = 0.0, 0.0, 0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
lr = 0.01
num_epochs = 5
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, net.parameters()), lr=lr)
loss = nn.CrossEntropyLoss()
train(net, train_iter, test_iter, batch_size, loss, optimizer, kDevice, num_epochs) # the training may take a long time in cpu
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))结果如下
training on cpu
epoch 1, loss 0.5575, train acc 0.679, test acc 0.814, time 3846.4 sec
epoch 2, loss 0.3534, train acc 0.846, test acc 0.856, time 3324.9 sec
epoch 3, loss 0.3027, train acc 0.872, test acc 0.862, time 3457.4 sec
epoch 4, loss 0.3248, train acc 0.864, test acc 0.780, time 3245.0 sec
epoch 5, loss 0.3798, train acc 0.839, test acc 0.811, time 4137.3 sec可以在pytorch里面用训练好的模型输入两句电影评论直接预测进行测试
# predict
def predict(net, vocab, sentence):
device = list(net.parameters())[0].device
words = tokenizer(sentence)
sentence_tensor = torch.tensor([vocab.stoi[word] for word in words], device=device)
output = net(sentence_tensor.view((1, -1)))
label = torch.argmax(output, dim=1)
print ("output:", output)
print ("label:", label.item())
return "positive" if label.item() == 1 else "negative"
sentence1 = "I feel the movie kind of great and to my taste"
sentence_tensor1 = torch.tensor([vocab.stoi[word] for word in tokenizer(sentence1)], device=list(net.parameters())[0].device).view(1, -1) # display the input tensor for C++ use
print ("input:", sentence_tensor1)
res = predict(net, vocab, sentence1)
print (res)
sentence2 = "the movie has bad experience"
sentence_tensor2 = torch.tensor([vocab.stoi[word] for word in tokenizer(sentence2)], device=list(net.parameters())[0].device).view(1, -1) # display the input tensor for C++ use
print ("input:", sentence_tensor2)
res = predict(net, vocab, sentence2)
print (res)结果如下
input: tensor([[ 9, 223, 2, 20, 232, 5, 88, 4, 6, 57, 1743]])
output: tensor([[-1.7009, 1.5822]], grad_fn=)
label: 1
positive
input: tensor([[ 2, 20, 41, 97, 802]])
output: tensor([[ 0.2492, -0.2555]], grad_fn=)
label: 0
negative 导出模型
利用pytorch和jit特性将模型导出到文件保存
# export model
example_sentence = "funny movie and make me exciting"
example_sentence_tensor = torch.tensor([vocab.stoi[word] for word in tokenizer(sentence2)], device=list(net.parameters())[0].device).view(1, -1)
traced_script_module = torch.jit.trace(net, example_sentence_tensor)
traced_script_module.save("text_rnn.pt")甚至可以用导出的模型再次检验下导出的正确性
# use the exported model to predict
predict(traced_script_module, vocab, sentence2)模型预测
使用pytorch的C++版本libtorch构建C++工程加载已导出的模型文件做预测
工程构建
目录
libtorch_nlp_demo
├── build
│ ├── nlp_predicator
│ └── text_rnn.pt
├── CMakeLists.txt
├── libtorch
├── README.md
└── src
└── nlp_predicator.cpp此处要提前将系统对应版本的libtorch下载好放在指定的目录,cmake会自动找到并建立好头文件和库的依赖关系
nlp_predicator.cpp
#include
#include
#include
#include "torch/script.h"
int main(int argc, char* argv[])
{
torch::jit::script::Module net;
try
{
std::cout << "===== predict begin ====" << std::endl;
// read model from file
std::string model_file_path = "text_rnn.pt";
net = torch::jit::load(model_file_path);
// optional: set device
torch::DeviceType device_type = torch::kCPU; // default run on cpu, you may use kCUDA
torch::Device device(device_type, 0);
net.to(device);
// create inputs, watch out that a::Tensor and torch::Tensor is the same type
// sentence1: "I feel the movie to kind of great and to my taste"
torch::Tensor input1 = torch::tensor({ {9, 223, 2, 20, 232, 5, 88, 4, 6, 57, 1743} }); // adapt the shape as a batch fo samples
torch::Tensor output1 = net.forward({ input1 }).toTensor();
int64_t label1 = output1.argmax(1).item().toInt();
std::cout << "output1: " << output1 << std::endl;
std::cout << "label1: " << label1 << std::endl;
std::cout << "res1: " << (label1 == 1 ? "positive" : "negative") << std::endl;
// sentence2: "the movie has bad experience"
torch::Tensor input2 = torch::tensor({ {2, 20, 41, 97, 802} }); // adapt the shape as a batch fo samples
std::vector inputs{ input2 };
torch::Tensor output2 = net.forward(inputs).toTensor();
int64_t label2 = output2.argmax(1).item().toInt();
std::cout << "output2: " << output2 << std::endl;
std::cout << "label2: " << label2 << std::endl;
std::cout << "res2: " << (label2 == 1 ? "positive" : "negative") << std::endl;
std::cout << "===== predict end ====" << std::endl;
}
catch (const c10::Error& e)
{
std::cerr << "error loading the model, error: " << e.what() << std::endl;
return -1;
}
return 0;
}
CMakeLists.txt
cmake_minimum_required(VERSION 3.0)
project(nlp_predicator)
if (UNIX)
add_definitions(-std=c++11)
endif()
set(CMAKE_PREFIX_PATH ${CMAKE_CURRENT_SOURCE_DIR}/libtorch)
find_package(Torch REQUIRED)
set (SRC
src/nlp_predicator.cpp
)
add_executable(${PROJECT_NAME} ${SRC})
target_link_libraries(${PROJECT_NAME}
${TORCH_LIBRARIES}
)
set_property(TARGET ${PROJECT_NAME} PROPERTY CXX_STANDARD 14) # here must specify 14
这个工程是跨windows和linux平台编译运行的,将模型文件放在程序可以读取的目录
使用cmake和make编译运行,结果
===== predict begin ====
output1: -1.7009 1.5822
[ CPUFloatType{1,2} ]
label1: 1
res1: positive
output2: 0.2492 -0.2555
[ CPUFloatType{1,2} ]
label2: 0
res2: negative
===== predict end ====可以看出用C++ libtorch加载模型预测的结果跟pytorch是一致的
代码
csdn:https://download.csdn.net/download/u012234115/12588959
github:https://github.com/tashaxing/libtorch_nlp_demo
 支持是知识分享的动力,有问题可扫码哦
支持是知识分享的动力,有问题可扫码哦