flink1.9新特性:维表JOIN解读
Flink 1.9 中维表功能来源于新加入的Blink中的功能,如果你要使用该功能,那就需要自己引入 Blink 的 Planner,而不是引用社区的 Planner。
org.apache.flink
flink-table-planner-blink_${scala.binary.version}
${flink.version}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);由于新合入的 Blink 相关功能,使得 Flink 1.9 实现维表功能很简单,只要自定义实现 LookupableTableSource 接口,同时实现里面的方法就可以进行,下面来分析一下 LookupableTableSource的代码:
public interface LookupableTableSource extends TableSource {
TableFunction getLookupFunction(String[] lookupKeys);
AsyncTableFunction getAsyncLookupFunction(String[] lookupKeys);
boolean isAsyncEnabled();
}
可以看到 LookupableTableSource 这个接口中有三个方法
isAsyncEnabled 方法主要表示该表是否支持异步访问外部数据源获取数据,当返回 true 时,那么在注册到 TableEnvironment 后,使用时会返回异步函数进行调用,当返回 false 时,则使同步访问函数。
getLookupFunction 方法返回一个同步访问外部数据系统的函数,什么意思呢,就是你通过 Key 去查询外部数据库,需要等到返回数据后才继续处理数据,这会对系统处理的吞吐率有影响。
getAsyncLookupFunction 方法则是返回一个异步的函数,异步访问外部数据系统,获取数据,这能极大的提升系统吞吐率。
2.2 同步访问函数getLookupFunction
getLookupFunction 会返回同步方法,这里你需要自定义 TableFuntion 进行实现,TableFunction 本质是 UDTF,输入一条数据可能返回多条数据,也可能返回一条数据。用户自定义 TableFunction 格式如下:
public class MyLookupFunction extends TableFunction {
Jedis jedis;
@Override
public void open(FunctionContext context) throws Exception {
jedis = new Jedis("172.16.44.28");
}
public void eval(Object... paramas) {
String key = "userInfo:userId:" + paramas[0].toString() + ":userName";
String value = jedis.get(key);
collect(Row.of(key, value));
}
}
open 方法在进行初始化算子实例的进行调用,异步外部数据源的client要在类中定义为 transient,然后在 open 方法中进行初始化,这样每个任务实例都会有一个外部数据源的 client。防止同一个 client 多个任务实例调用,出现线程不安全情况。
eval 则是 TableFunction 最重要的方法,它用于关联外部数据。当程序有一个输入元素时,就会调用eval一次,用户可以将产生的数据使用 collect() 进行发送下游。paramas 的值为用户输入元素的值,比如在 Join 的时候,使用 A.id = B.id and A.name = b.name, B 是维表,A 是用户数据表,paramas 则代表 A.id,A.name 的值。
2.3 异步访问函数
getAsyncLookupFunction 会返回异步访问外部数据源的函数,如果你想使用异步函数,前提是 LookupableTableSource 的 isAsyncEnabled 方法返回 true 才能使用。使用异步函数访问外部数据系统,一般是外部系统有异步访问客户端,如果没有的话,可以自己使用线程池异步访问外部系统。至于为什么使用异步访问函数,无非就是为了提高程序的吞吐量,不需要每条记录访问返回数据后,才去处理下一条记录。异步函数格式如下:
public class MyAsyncLookupFunction extends AsyncTableFunction {
private transient RedisAsyncCommands async;
@Override
public void open(FunctionContext context) throws Exception {
RedisClient redisClient = RedisClient.create("redis://172.16.44.28:6379/0");
StatefulRedisConnection connection = redisClient.connect();
async = connection.async();
}
public void eval(CompletableFuture> future, Object... params) {
redisFuture.thenAccept(new Consumer() {
@Override
public void accept(String value) {
future.complete(Collections.singletonList(Row.of(key, value)));
}
});
}
}
维表异步访问函数总体和同步函数实现类似,这里说一下注意点:
1. 外部数据源异步客户端(如RedisAsyncCommands)初始化。如果是线程安全的(多个客户端一起使用),你可以不加 transient 关键字,初始化一次。否则,你需要加上 transient,不对其进行初始化,而在 open 方法中,为每个 Task 实例初始化一个。
2. eval 方法中多了一个 CompletableFuture,当异步访问完成时,需要调用其方法进行处理.
为了减少每条数据都去访问外部数据系统,提高数据的吞吐量,一般我们会在同步函数和异步函数中加入缓存,如果以前某个关键字访问过外部数据系统,我们将其值放入到缓存中,在缓存没有失效之前,如果该关键字再次进行处理时,直接先访问缓存,有就直接返回,没有再去访问外部数据系统,然后在进行缓存,进一步提升我们实时程序处理的吞吐量。
一般缓存类型有以下几种类型:
数据全部缓存,定时更新。
LRU Cache,设置一个超时时间。
用户自定义缓存。
以下是demo
从HDFS中读取数据源,join Redis维表,最终结果落到kafka。服务器上8个并行度大概可以达到60w+/s。
redis上数据类似于
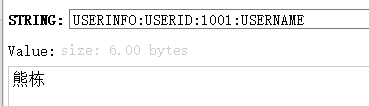
HDFS数据类似于
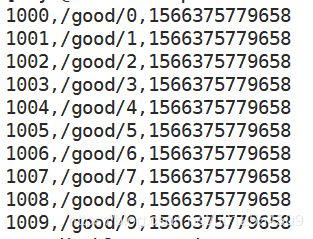
全部依赖项:
UTF-8
1.9.0
1.8
2.11
${java.version}
${java.version}
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-java_${scala.binary.version}
${flink.version}
org.apache.flink
flink-scala_${scala.binary.version}
${flink.version}
org.apache.flink
flink-table-api-java-bridge_${scala.binary.version}
${flink.version}
org.apache.flink
flink-table-planner-blink_${scala.binary.version}
${flink.version}
org.apache.flink
flink-streaming-scala_${scala.binary.version}
${flink.version}
org.apache.flink
flink-table-common
${flink.version}
org.apache.flink
flink-clients_${scala.binary.version}
${flink.version}
mysql
mysql-connector-java
8.0.16
org.apache.flink
flink-connector-wikiedits_2.11
${flink.version}
org.apache.flink
flink-connector-filesystem_2.11
${flink.version}
org.apache.flink
flink-hadoop-compatibility_2.11
${flink.version}
org.apache.hadoop
hadoop-common
2.5.1
org.apache.hadoop
hadoop-hdfs
2.5.1
org.apache.hadoop
hadoop-client
2.5.1
org.apache.flink
flink-connector-rabbitmq_2.11
${flink.version}
org.apache.flink
flink-avro
${flink.version}
org.apache.flink
flink-connector-redis_2.11
1.1.5
org.apache.httpcomponents
httpclient
4.5.2
com.fasterxml.jackson.core
jackson-core
2.9.5
org.apache.flink
flink-metrics-dropwizard
${flink.version}
org.apache.flink
flink-connector-kafka-0.11_${scala.binary.version}
${flink.version}
org.apache.kafka
kafka_${scala.binary.version}
0.11.0.0
io.lettuce
lettuce-core
5.0.5.RELEASE
io.netty
netty-all
4.1.24.Final
import io.lettuce.core.RedisClient;
import io.lettuce.core.RedisFuture;
import io.lettuce.core.api.StatefulRedisConnection;
import io.lettuce.core.api.async.RedisAsyncCommands;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.table.functions.AsyncTableFunction;
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.types.Row;
import java.util.Collection;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
import java.util.function.Consumer;
public class MyAsyncLookupFunction extends AsyncTableFunction {
private final String[] fieldNames;
private final TypeInformation[] fieldTypes;
private transient RedisAsyncCommands async;
public MyAsyncLookupFunction(String[] fieldNames, TypeInformation[] fieldTypes) {
this.fieldNames = fieldNames;
this.fieldTypes = fieldTypes;
}
@Override
public void open(FunctionContext context) {
//配置redis异步连接
RedisClient redisClient = RedisClient.create("redis://172.16.44.28:6379/0");
StatefulRedisConnection connection = redisClient.connect();
async = connection.async();
}
//每一条流数据都会调用此方法进行join
public void eval(CompletableFuture> future, Object... paramas) {
//表名、主键名、主键值、列名
String[] info = {"userInfo", "userId", paramas[0].toString(), "userName"};
String key = String.join(":", info);
RedisFuture redisFuture = async.get(key);
redisFuture.thenAccept(new Consumer() {
@Override
public void accept(String value) {
future.complete(Collections.singletonList(Row.of(key, value)));
//todo
// BinaryRow row = new BinaryRow(2);
}
});
}
@Override
public TypeInformation getResultType() {
return new RowTypeInfo(fieldTypes, fieldNames);
}
public static final class Builder {
private String[] fieldNames;
private TypeInformation[] fieldTypes;
private Builder() {
}
public static Builder getBuilder() {
return new Builder();
}
public Builder withFieldNames(String[] fieldNames) {
this.fieldNames = fieldNames;
return this;
}
public Builder withFieldTypes(TypeInformation[] fieldTypes) {
this.fieldTypes = fieldTypes;
return this;
}
public MyAsyncLookupFunction build() {
return new MyAsyncLookupFunction(fieldNames, fieldTypes);
}
}
}
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.TableSchema;
import org.apache.flink.table.functions.AsyncTableFunction;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.table.sources.LookupableTableSource;
import org.apache.flink.table.sources.StreamTableSource;
import org.apache.flink.table.types.DataType;
import org.apache.flink.table.types.utils.TypeConversions;
import org.apache.flink.types.Row;
public class RedisAsyncLookupTableSource implements StreamTableSource, LookupableTableSource {
private final String[] fieldNames;
private final TypeInformation[] fieldTypes;
public RedisAsyncLookupTableSource(String[] fieldNames, TypeInformation[] fieldTypes) {
this.fieldNames = fieldNames;
this.fieldTypes = fieldTypes;
}
//同步方法
@Override
public TableFunction getLookupFunction(String[] strings) {
return null;
}
//异步方法
@Override
public AsyncTableFunction getAsyncLookupFunction(String[] strings) {
return MyAsyncLookupFunction.Builder.getBuilder()
.withFieldNames(fieldNames)
.withFieldTypes(fieldTypes)
.build();
}
//开启异步
@Override
public boolean isAsyncEnabled() {
return true;
}
@Override
public DataType getProducedDataType() {
return TypeConversions.fromLegacyInfoToDataType(new RowTypeInfo(fieldTypes, fieldNames));
}
@Override
public TableSchema getTableSchema() {
return TableSchema.builder()
.fields(fieldNames, TypeConversions.fromLegacyInfoToDataType(fieldTypes))
.build();
}
@Override
public DataStream getDataStream(StreamExecutionEnvironment environment) {
throw new UnsupportedOperationException("do not support getDataStream");
}
public static final class Builder {
private String[] fieldNames;
private TypeInformation[] fieldTypes;
private Builder() {
}
public static Builder newBuilder() {
return new Builder();
}
public Builder withFieldNames(String[] fieldNames) {
this.fieldNames = fieldNames;
return this;
}
public Builder withFieldTypes(TypeInformation[] fieldTypes) {
this.fieldTypes = fieldTypes;
return this;
}
public RedisAsyncLookupTableSource build() {
return new RedisAsyncLookupTableSource(fieldNames, fieldTypes);
}
}
}
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.junit.Test;
import java.util.Properties;
public class LookUpAsyncTest {
@Test
public void test() throws Exception {
LookUpAsyncTest.main(new String[]{});
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
final ParameterTool params = ParameterTool.fromArgs(args);
String fileName;
if (params.get("f") != null)
fileName = params.get("f");
else
fileName = "/flink/userClick_Random_100W";
DataStream source = env.readTextFile("hdfs://172.16.44.28:8020" + fileName, "UTF-8");
TypeInformation[] types = new TypeInformation[]{Types.STRING, Types.STRING, Types.LONG};
String[] fields = new String[]{"id", "user_click", "time"};
RowTypeInfo typeInformation = new RowTypeInfo(types, fields);
DataStream stream = source.map(new MapFunction() {
private static final long serialVersionUID = 2349572544179673349L;
@Override
public Row map(String s) {
String[] split = s.split(",");
Row row = new Row(split.length);
for (int i = 0; i < split.length; i++) {
Object value = split[i];
if (types[i].equals(Types.STRING)) {
value = split[i];
}
if (types[i].equals(Types.LONG)) {
value = Long.valueOf(split[i]);
}
row.setField(i, value);
}
return row;
}
}).returns(typeInformation);
tableEnv.registerDataStream("user_click_name", stream, String.join(",", typeInformation.getFieldNames()) + ",proctime.proctime");
RedisAsyncLookupTableSource tableSource = RedisAsyncLookupTableSource.Builder.newBuilder()
.withFieldNames(new String[]{"id", "name"})
.withFieldTypes(new TypeInformation[]{Types.STRING, Types.STRING})
.build();
tableEnv.registerTableSource("info", tableSource);
String sql = "select t1.id,t1.user_click,t2.name" +
" from user_click_name as t1" +
" join info FOR SYSTEM_TIME AS OF t1.proctime as t2" +
" on t1.id = t2.id";
Table table = tableEnv.sqlQuery(sql);
DataStream result = tableEnv.toAppendStream(table, Row.class);
// result.print().setParallelism(1);
DataStream printStream = result.map(new MapFunction() {
@Override
public String map(Row value) throws Exception {
return value.toString();
}
});
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "172.16.12.148:9094");
FlinkKafkaProducer011 kafkaProducer = new FlinkKafkaProducer011<>(// broker list
"user_click_name", // target topic
new SimpleStringSchema(),
properties);
printStream.addSink(kafkaProducer);
tableEnv.execute(Thread.currentThread().getStackTrace()[1].getClassName());
}
}
参考:https://zhuanlan.zhihu.com/p/79800113