Web Scraping with Python: 使用 Python 爬 Baidu 关键词
一、引言
自从开始看《Web Scraping with Python》这本书之后,我就天天想着给自己创造需求练习爬虫实践。
我相信每一个学习爬虫的人,都曾经想过在搜索引擎上爬些有趣的东西。在自己实现了 GitHub Star 数、CSDN 博客信息的爬取之后,自然而然,就想要去爬取一下百度。
想要了解前两个实例的实现的同学,可以点击这里:
Web Scraping with Python: 使用 Python 爬 GitHub Star 数
Web Scraping with Python: 使用 Python 爬 CSDN 博客
先给自己定一个需求吧:
输入指定关键词,输入指定的条目数,最后爬虫程序将爬取到的结果信息写入到本地的一个 MarkDown 文件中,以表格形式显示出来
在经历了之前两个实例的实践之后,这个需求看起来也不会很难。
接下来,让我们开始吧!
二、分析:爬取规则
我们想要爬取指定关键词的搜索条目,就需要了解一些规则信息,通过这些规则信息,我们就可以编写指定的爬虫程序完成我们想要的需求。
在这里,我们需要的信息如下:
1. 入口网址是什么?
这是一个非常重要的问题。接下来让我们打开网址测试下,我们在百度一下中输入 python 测试词条,发现其生成了复杂的 url:
https://www.baidu.com/s?wd=python&rsv_spt=1&rsv_iqid=0xf2a1a84300027a1e&issp=1&f=8&rsv_bp=0&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_sug3=10&rsv_sug1=11&rsv_sug7=100&rsv_sug2=0&inputT=2354&rsv_sug4=2354这么复杂?!通过查询资料,发现百度会通过环境信息对于你搜索的结果进行一些适配的变化,而我们不需要这些信息,因此,我们可以输入这么一个 url:
https://www.baidu.com/s?wd=python那么,这个就是我们的入口网址了,https://www.baidu.com/s?wd= 后加上关键词即可。
2. 我们如何实现多页的跳转?
这个问题涉及到了我们大量信息的收集。这里,我查看了下百度的下一页按钮的样式:
<a href="/s?wd=asdfafdsasdfasdfffffffffffffffffffff&pn=10&oq=asdfafdsasdfasdfffffffffffffffffffff&ie=utf-8&rsv_pq=b5e8070300006cbc&rsv_t=d4cbSiBUdx2J%2BXs6yKLuS3IvH8QA0fg9TcrRwpbwp0WASJ1szyVs5a20HdU&rsv_page=1" class="n">下一页>a>而当最后一页的时候,就不会有下一页按钮出现。我们可以通过这个信息来遍历循环,查询当前页是否有 text=“下一页”的 a 标签,即可了解当前页是否有下一页内容。
而有关页面的切换,从这个 a 标签中获取 href 是一个不那么简单的方法,这里我通过多次尝试发现:
https://www.baidu.com/s?wd=python&pn=0
https://www.baidu.com/s?wd=python&pn=10
https://www.baidu.com/s?wd=python&pn=20
https://www.baidu.com/s?wd=python&pn=30通过在 url 后面加上 &pn= 数字即可实现翻页,其中 0 是第一页,10 是第二页,20 是第三页,依次类推。
3. 我们如何抽取每一个搜索结果的信息?
这一块就是这个爬虫程序的核心之处了。通过搜索 python 词条进行测试,我打开了 Chrome 浏览器的 F12 模式中,对于相对应的元素进行查看,发现了以下规则:
- 所有搜索结果都在 id 为 content_left 的 div 中
- 一般的搜索结果都是 class 为 result c-container 的 div 组成的
- 与百度官方产品有关的搜索结果,其 div 的 class 都是会在 result 后面加上一个 -op 的,即 result-op c-container,百度百科还会在后面加上 xpath-log 即 result-op c-container xpath-log
通过上述规则,我们就可以抽取出搜索结果,并且将其每个搜索结果的标题、简介、url 都抽取出来(主要还是分析 html 的特征)
至此,我们基本上已经拥有了写出这个爬虫程序的知识。但是这里还有一个坑,那就是百度的反爬虫机制。
三、分析:爬虫伪装浏览器
如果你只是简简单单考虑上述的逻辑,写出来的代码可能还是会出问题:
比如说你会发现你 urlopen 之后返回的内容竟然没有包含你想要的网页布局信息!
这是为什么呢?
通过查询了相关资料,我发现原来百度是会拒绝爬虫程序的访问的,而我们想要继续我们的爬行之旅,就必须要使我们的爬虫程序伪装成浏览器。
在参考了这篇博客:
Python3 爬虫实例(二) – 伪装浏览器
我使用 Fiddler 查看了自己的 Chrome 浏览器访问百度的请求头信息,然后在之前使用 urlopen 打开网址之前,先设置请求的 header 信息,将其 User-Agent 设置为图中看到的信息。

...
url = 'https://www.baidu.com/s?wd=' + keyword + '&pn=' + str(page)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36'}
req = Request(url=url, headers=headers)
html = urlopen(req)
...这样尝试之后,果然就不再出现之前返回数据异常的问题了。
四、代码编写
现在,万事俱备,我们可以开始编写代码了,先展示我的代码吧:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import re
import pprint
print('Please input keyword:')
keyword = input()
print('Please input results limit:')
limit = input()
info = []
page = 0
while True:
# 1. Pretend Browser, Open first page.
try:
url = 'https://www.baidu.com/s?wd=' + keyword + '&pn=' + str(page)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36'}
req = Request(url=url, headers=headers)
html = urlopen(req)
except HTTPError:
print('Open ' + 'https://www.baidu.com/s?wd=' + keyword + ' failed')
break
# 2. Record data in one page.
bsObj = BeautifulSoup(html)
for result in bsObj.find('div', {'id': 'content_left'})\
.findAll('div', class_=re.compile('^result(.)*c-container(.)*')):
try:
newResult = {}
newResult['title'] = result.find('h3', class_=re.compile('t(.)*')).get_text().strip().replace('|', '\|')
newResult['brief'] = result.find('div', {'class': 'c-abstract'}).get_text().strip().replace('|', '\|')
newResult['url'] = result.find('h3').find('a').attrs['href']
if len(info) < int(limit):
info.append(newResult)
else:
break
except AttributeError:
print('This reuslt missing something! No worries though!')
continue
# 3. Move to new page
if len(info) >= int(limit):
break
nextPage = bsObj.find('a', text='下一页>')
if nextPage is None:
print('No more results!')
break
else:
page += 10
with open('record.md', 'w', encoding='utf-8') as md:
md.write('| 标题 |' + ' 简介 |' + ' 链接 |\n')
md.write('| --- |' + ' --- |' + ' --- |\n')
for result in info:
md.write(('| ' + str(result['title']) + ' | ' +
str(result['brief']) + ' |' +
str(result['url']) + ' |\n'))
pprint.pprint(info)这段代码中,我做了以下的事情:
1. 接受用户输入关键词和指定书目信息
2. 伪装浏览器,打开入口网址
3. 读取当页的所有条目信息,以 dict 的结构将其存储到 info 这个全局的 list 中去
4. 判断是否达到了指定的数目,判断是否有下一页信息,然后跳转到下一页,重复进行第 2、3、4 步,直到数目达到或者没有信息了为止
5. 最后,将数据写入了一个 MarkDown 文件,并且以表格形式显示。注意,这里因为条目标题中可能带有 | 符号,这个符号在 MarkDown 中被解析为表格分隔符,因此需要提前替换,这里我就替换成了转义的 |
最后,看一看我们搜索 python 出来的结果吧:
控制台输出
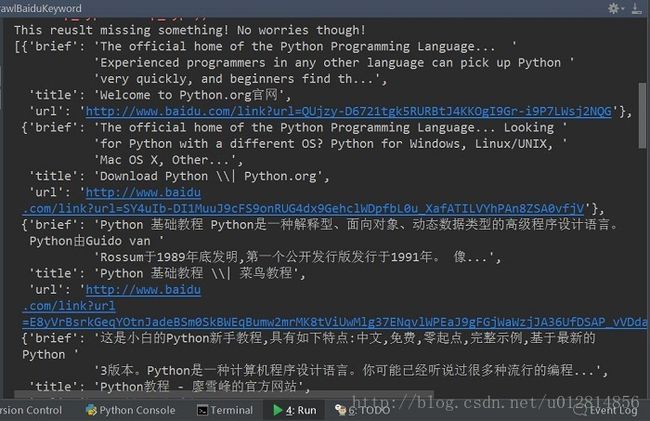
MarkDown

很有趣,对吧!
至此,完结撒花:)
五、总结
爬取百度关键词其实并不难,在爬取之前需要总结需要爬取的信息的规律,这才是关键所在,也是一个爬虫程序最核心的地方。
另外,各大网站对于爬虫程序都或多或少有些防范。我们在抱着学习的态度的时候,不应该使用爬虫程序操作太多数据或者进行太频繁的操作,这样或许会对该网站带来不好的影响,这并不是我们想要的。
最后,Python 的学习不止,折腾不息 ^_^
To be Stronger!
ps: 想要获取本博客的实验代码的同学可以点击这里
wangying2016/CrawlBaiduKeyword