深度学习笔记(2):caffe 加新层 Attention LSTM layer
上一篇文章,详细地分析了LSTM layer 的源码和流程图,本篇将在caffe加入新层,Attention lstm layer。
在代码之前,我们先分析一下一些论文里的attention model 的公式和流程图。
(1): Recurrent Models of Visual Attention
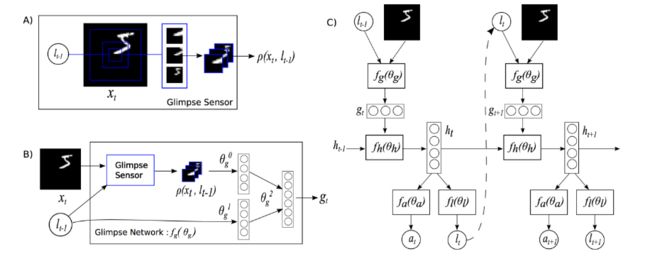
A、Glimpse Sensor: 在t时刻,选取不同大小的区域,组合成数据ρ
B、Glimpse Network:图片局部信息与位置信息整合
C、Model Architecture:ht-1隐藏记忆单元,与gt,生成新的ht,并以此生成attention,即感兴趣的地方。
具体公式推导可以看论文和代码
(2)ACTION RECOGNITION USING VISUAL ATTENTION
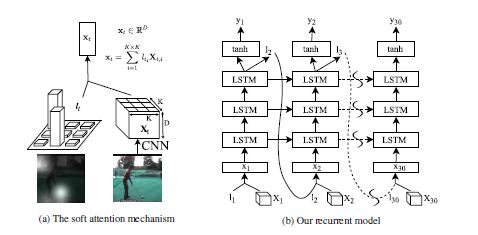
大体思想是对提出的特征分割,即每张图片分割成49个部分(7X7),这样找出每张图片的关注地方,这里的图(b)有问题,作者的代码也反映出这一点。本文主要是在caffe里写出一个这样的Attention Lstm layer.
(3) Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
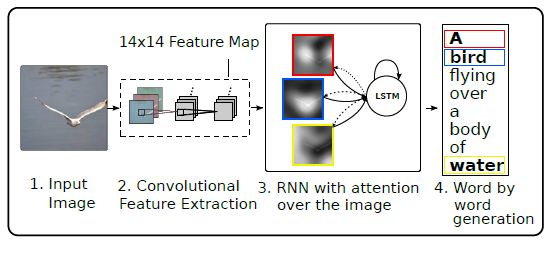
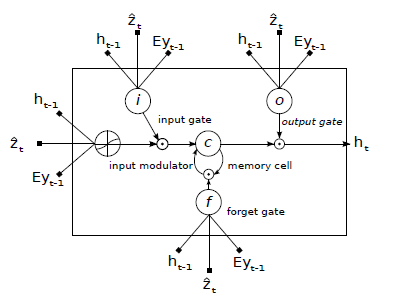
思想一致,具体推导看论文。
二:ALSTM Layer 代码
Alstm.cpp
#include
#include
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/filler.hpp"
#include "caffe/layer.hpp"
#include "caffe/sequence_layers.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
template
void ALSTMLayer::RecurrentInputBlobNames(vector* names) const {
names->resize(2);
(*names)[0] = "h_0";
(*names)[1] = "c_0";
}
template
void ALSTMLayer::RecurrentOutputBlobNames(vector* names) const {
names->resize(2);
(*names)[0] = "h_" + this->int_to_str(this->T_);
(*names)[1] = "c_T";
}
template
void ALSTMLayer::OutputBlobNames(vector* names) const {
names->resize(2);
(*names)[0] = "h";
(*names)[1] = "mask";
}
template
void ALSTMLayer::FillUnrolledNet(NetParameter* net_param) const {
const int num_output = this->layer_param_.recurrent_param().num_output();
CHECK_GT(num_output, 0) << "num_output must be positive";
const FillerParameter& weight_filler =
this->layer_param_.recurrent_param().weight_filler();
const FillerParameter& bias_filler =
this->layer_param_.recurrent_param().bias_filler();
// Add generic LayerParameter's (without bottoms/tops) of layer types we'll
// use to save redundant code.
LayerParameter hidden_param;
hidden_param.set_type("InnerProduct");
hidden_param.mutable_inner_product_param()->set_num_output(num_output * 4);
hidden_param.mutable_inner_product_param()->set_bias_term(false);
hidden_param.mutable_inner_product_param()->set_axis(1);
hidden_param.mutable_inner_product_param()->
mutable_weight_filler()->CopyFrom(weight_filler);
LayerParameter biased_hidden_param(hidden_param);
biased_hidden_param.mutable_inner_product_param()->set_bias_term(true);
biased_hidden_param.mutable_inner_product_param()->
mutable_bias_filler()->CopyFrom(bias_filler);
LayerParameter attention_param;
attention_param.set_type("InnerProduct");
attention_param.mutable_inner_product_param()->set_num_output(256);
attention_param.mutable_inner_product_param()->set_bias_term(false);
attention_param.mutable_inner_product_param()->set_axis(2);
attention_param.mutable_inner_product_param()->
mutable_weight_filler()->CopyFrom(weight_filler);
LayerParameter biased_attention_param(attention_param);
biased_attention_param.mutable_inner_product_param()->set_bias_term(true);
biased_attention_param.mutable_inner_product_param()->
mutable_bias_filler()->CopyFrom(bias_filler); // weight + bias
LayerParameter sum_param;
sum_param.set_type("Eltwise");
sum_param.mutable_eltwise_param()->set_operation(
EltwiseParameter_EltwiseOp_SUM);
LayerParameter slice_param;
slice_param.set_type("Slice");
slice_param.mutable_slice_param()->set_axis(0);
LayerParameter softmax_param;
softmax_param.set_type("Softmax");
softmax_param.mutable_softmax_param()->set_axis(-1);
LayerParameter split_param;
split_param.set_type("Split");
LayerParameter scale_param;
scale_param.set_type("Scale");
LayerParameter permute_param;
permute_param.set_type("Permute");
LayerParameter reshape_param;
reshape_param.set_type("Reshape");
LayerParameter bias_layer_param;
bias_layer_param.set_type("Bias");
LayerParameter pool_param;
pool_param.set_type("Pooling");
LayerParameter reshape_layer_param;
reshape_layer_param.set_type("Reshape");
BlobShape input_shape;
input_shape.add_dim(1); // c_0 and h_0 are a single timestep
input_shape.add_dim(this->N_);
input_shape.add_dim(num_output);
net_param->add_input("c_0");
net_param->add_input_shape()->CopyFrom(input_shape);
net_param->add_input("h_0");
net_param->add_input_shape()->CopyFrom(input_shape);
LayerParameter* cont_slice_param = net_param->add_layer();
cont_slice_param->CopyFrom(slice_param);
cont_slice_param->set_name("cont_slice");
cont_slice_param->add_bottom("cont");
cont_slice_param->mutable_slice_param()->set_axis(1);
LayerParameter* x_slice_param = net_param->add_layer();
x_slice_param->CopyFrom(slice_param);
x_slice_param->set_name("x_slice");
x_slice_param->add_bottom("x");
// Add layer to transform all timesteps of x to the hidden state dimension.
// W_xc_x = W_xc * x + b_c
/*
{
LayerParameter* x_transform_param = net_param->add_layer();
x_transform_param->CopyFrom(biased_hidden_param);
x_transform_param->set_name("x_transform");
x_transform_param->add_param()->set_name("W_xc");
x_transform_param->add_param()->set_name("b_c");
x_transform_param->add_bottom("x");
x_transform_param->add_top("W_xc_x");
}
if (this->static_input_) {
// Add layer to transform x_static to the gate dimension.
// W_xc_x_static = W_xc_static * x_static
LayerParameter* x_static_transform_param = net_param->add_layer();
x_static_transform_param->CopyFrom(hidden_param);
x_static_transform_param->mutable_inner_product_param()->set_axis(1);
x_static_transform_param->set_name("W_xc_x_static");
x_static_transform_param->add_param()->set_name("W_xc_static");
x_static_transform_param->add_bottom("x_static");
x_static_transform_param->add_top("W_xc_x_static");
LayerParameter* reshape_param = net_param->add_layer();
reshape_param->set_type("Reshape");
BlobShape* new_shape =
reshape_param->mutable_reshape_param()->mutable_shape();
new_shape->add_dim(1); // One timestep.
new_shape->add_dim(this->N_);
new_shape->add_dim(
x_static_transform_param->inner_product_param().num_output());
reshape_param->add_bottom("W_xc_x_static");
reshape_param->add_top("W_xc_x_static");
}
LayerParameter* x_slice_param = net_param->add_layer();
x_slice_param->CopyFrom(slice_param);
x_slice_param->add_bottom("W_xc_x");
x_slice_param->set_name("W_xc_x_slice");
*/
LayerParameter output_concat_layer;
output_concat_layer.set_name("h_concat");
output_concat_layer.set_type("Concat");
output_concat_layer.add_top("h");
output_concat_layer.mutable_concat_param()->set_axis(0);
LayerParameter output_m_layer;
output_m_layer.set_name("m_concat");
output_m_layer.set_type("Concat");
output_m_layer.add_top("mask");
output_m_layer.mutable_concat_param()->set_axis(0); // out put 2
for (int t = 1; t <= this->T_; ++t) {
string tm1s = this->int_to_str(t - 1);
string ts = this->int_to_str(t);
cont_slice_param->add_top("cont_" + ts);
x_slice_param->add_top("x_" + ts);
// Add a layer to permute x
{
LayerParameter* permute_x_param = net_param->add_layer();
permute_x_param->CopyFrom(permute_param);
permute_x_param->set_name("permute_x_" + ts);
permute_x_param->mutable_permute_param()->add_order(2);
permute_x_param->mutable_permute_param()->add_order(0);
permute_x_param->mutable_permute_param()->add_order(1);
permute_x_param->mutable_permute_param()->add_order(3);
permute_x_param->add_bottom("x_" + ts);
permute_x_param->add_top("x_p_" + ts);
}
//
// Add a layer to generate attention weights
{
LayerParameter* att_m_param = net_param->add_layer();
att_m_param->CopyFrom(biased_attention_param);
att_m_param->set_name("att_m_" + tm1s);
att_m_param->add_bottom("h_" + tm1s);
att_m_param->add_top("m_" + tm1s); // }
{
LayerParameter* permute_x_a_param = net_param->add_layer();
permute_x_a_param->CopyFrom(permute_param);
permute_x_a_param->set_name("permute_x_a_" + ts);
permute_x_a_param->mutable_permute_param()->add_order(0);
permute_x_a_param->mutable_permute_param()->add_order(1);
permute_x_a_param->mutable_permute_param()->add_order(3);
permute_x_a_param->mutable_permute_param()->add_order(2);
permute_x_a_param->add_bottom("x_" + ts);
permute_x_a_param->add_top("x_p_a_" + ts);
} // here is to change!
{
LayerParameter* att_x_param = net_param->add_layer();
att_x_param->CopyFrom(biased_attention_param);
att_x_param->set_name("att_x_" + tm1s);
att_x_param->mutable_inner_product_param()->set_axis(3);
att_x_param->add_bottom("x_p_a_" + ts);
att_x_param->add_top("m_x_" + tm1s);
} // fc layer ,change output,dim
{
LayerParameter* permute_x_a_p_param = net_param->add_layer();
permute_x_a_p_param->CopyFrom(permute_param);
permute_x_a_p_param->set_name("permute_x_a_p_" + ts);
permute_x_a_p_param->mutable_permute_param()->add_order(2);
permute_x_a_p_param->mutable_permute_param()->add_order(0);
permute_x_a_p_param->mutable_permute_param()->add_order(1);
permute_x_a_p_param->mutable_permute_param()->add_order(3);
permute_x_a_p_param->add_bottom("m_x_" + tm1s);
permute_x_a_p_param->add_top("m_x_a_" + tm1s);
}
{
LayerParameter* m_sum_layer = net_param->add_layer();
m_sum_layer->CopyFrom(bias_layer_param);
m_sum_layer->set_name("mask_input_" + ts);
m_sum_layer->add_bottom("m_x_a_" + tm1s);
m_sum_layer->add_bottom("m_" + tm1s);
m_sum_layer->add_top("m_input_" + tm1s);
}
{
LayerParameter* att_x_ap_param = net_param->add_layer();
att_x_ap_param->CopyFrom(biased_attention_param);
att_x_ap_param->set_name("att_x_ap_" + tm1s);
att_x_ap_param->mutable_inner_product_param()->set_axis(3);
att_x_ap_param->mutable_inner_product_param()->set_num_output(1);
att_x_ap_param->add_bottom("m_input_" + tm1s);
att_x_ap_param->add_top("m_x_ap_" + tm1s); //256---->1
}
{
LayerParameter* permute_m_param = net_param->add_layer();
permute_m_param->CopyFrom(permute_param);
permute_m_param->set_name("permute_m_" + ts);
permute_m_param->mutable_permute_param()->add_order(1);
permute_m_param->mutable_permute_param()->add_order(2);
permute_m_param->mutable_permute_param()->add_order(0);
permute_m_param->mutable_permute_param()->add_order(3);
permute_m_param->add_bottom("m_x_ap_" + tm1s);
permute_m_param->add_top("m_f_" + tm1s); //10*8*30*1
}
// Add a softmax layers to generate attention masks
{
LayerParameter* softmax_m_param = net_param->add_layer();
softmax_m_param->CopyFrom(softmax_param);
softmax_m_param->mutable_softmax_param()->set_axis(2);
softmax_m_param->set_name("softmax_m_" + tm1s);
softmax_m_param->add_bottom("m_f_" + tm1s);
softmax_m_param->add_top("mask_" + tm1s);
}
{
LayerParameter* reshape_m_param = net_param->add_layer();
reshape_m_param->CopyFrom(reshape_layer_param);
BlobShape* shape = reshape_m_param->mutable_reshape_param()->mutable_shape();
shape->Clear();
shape->add_dim(0);
shape->add_dim(0);
shape->add_dim(0);
reshape_m_param->set_name("reshape_m_" + tm1s);
reshape_m_param->add_bottom("mask_" + tm1s);
reshape_m_param->add_top("mask_reshape_" + tm1s);
}
//Reshape mask from 1*6*36 to 1*6*6*6
/*
{
LayerParameter* reshape_param = net_param->add_layer();
reshape_param->set_type("Reshape");
BlobShape* new_shape =
reshape_param->mutable_reshape_param()->mutable_shape();
new_shape->add_dim(1); // One timestep.
new_shape->add_dim(6);
new_shape->add_dim(6);
new_shape->add_dim(6);
reshape_param->add_bottom("mask_" +tm1s);
reshape_param->add_top("mask_reshape_" +tm1s);
}*/
// Conbine mask with input features
{
LayerParameter* scale_x_param = net_param->add_layer();
scale_x_param->CopyFrom(scale_param);
scale_x_param->set_name("scale_x_" + tm1s);
scale_x_param->add_bottom("x_p_" + ts);
scale_x_param->add_bottom("mask_reshape_" + tm1s);
scale_x_param->add_top("x_mask_" + ts);
}
{
LayerParameter* permute_x_mask_param = net_param->add_layer();
permute_x_mask_param->CopyFrom(permute_param);
permute_x_mask_param->set_name("permute_x_mask_" + ts);
permute_x_mask_param->mutable_permute_param()->add_order(1);
permute_x_mask_param->mutable_permute_param()->add_order(2);
permute_x_mask_param->mutable_permute_param()->add_order(0);
permute_x_mask_param->mutable_permute_param()->add_order(3);
permute_x_mask_param->add_bottom("x_mask_" + ts);
permute_x_mask_param->add_top("x_mask_p_" + ts);
}
{
LayerParameter* reshape_x_param = net_param->add_layer();
reshape_x_param->CopyFrom(reshape_param);
reshape_x_param->set_name("reshape_x_" +ts);
BlobShape* new_shape =
reshape_x_param->mutable_reshape_param()->mutable_shape();
new_shape->add_dim(this->N_);
new_shape->add_dim(512);//512//384
new_shape->add_dim(7);//7//6
new_shape->add_dim(7);//7//6
reshape_x_param->add_bottom("x_mask_p_" + ts);
reshape_x_param->add_top("x_mask_reshape_"+ts);
}
{
LayerParameter* pool_x_param = net_param->add_layer();
pool_x_param->CopyFrom(pool_param);
pool_x_param->set_name("pool_x_"+ts);
pool_x_param->mutable_pooling_param()->set_pool(PoolingParameter_PoolMethod_SUM);
pool_x_param->mutable_pooling_param()->set_kernel_size(7);//7//6
pool_x_param->add_bottom("x_mask_reshape_"+ts);
pool_x_param->add_top("x_pool_"+ts);
}
{
LayerParameter* x_transform_param = net_param->add_layer();
x_transform_param->CopyFrom(biased_hidden_param);
x_transform_param->set_name("x_transform_" + ts);
x_transform_param->add_param()->set_name("W_xc_" + ts);
x_transform_param->add_param()->set_name("b_c" + ts);
x_transform_param->add_bottom("x_pool_" +ts );
x_transform_param->add_top("W_xc_x_"+ts);
}
{
LayerParameter* x_transform_reshape_param = net_param->add_layer();
x_transform_reshape_param->CopyFrom(reshape_param);
x_transform_reshape_param->set_name("x_transform_reshape_" +ts);
BlobShape* new_shape_r =
x_transform_reshape_param->mutable_reshape_param()->mutable_shape();
new_shape_r->add_dim(1);
new_shape_r->add_dim(this->N_);
new_shape_r->add_dim(num_output * 4);
x_transform_reshape_param->add_bottom("W_xc_x_" + ts);
x_transform_reshape_param->add_top("W_xc_x_r_"+ts);
}
// Add layers to flush the hidden state when beginning a new
// sequence, as indicated by cont_t.
// h_conted_{t-1} := cont_t * h_{t-1}
//
// Normally, cont_t is binary (i.e., 0 or 1), so:
// h_conted_{t-1} := h_{t-1} if cont_t == 1
// 0 otherwise
{
LayerParameter* cont_h_param = net_param->add_layer();
cont_h_param->CopyFrom(sum_param);
cont_h_param->mutable_eltwise_param()->set_coeff_blob(true);
cont_h_param->set_name("h_conted_" + tm1s);
cont_h_param->add_bottom("h_" + tm1s);
cont_h_param->add_bottom("cont_" + ts);
cont_h_param->add_top("h_conted_" + tm1s);
}
// Add layer to compute
// W_hc_h_{t-1} := W_hc * h_conted_{t-1}
{
LayerParameter* w_param = net_param->add_layer();
w_param->CopyFrom(hidden_param);
w_param->set_name("transform_" + ts);
w_param->add_param()->set_name("W_hc");
w_param->add_bottom("h_conted_" + tm1s);
w_param->add_top("W_hc_h_" + tm1s);
w_param->mutable_inner_product_param()->set_axis(2);
}
// Add the outputs of the linear transformations to compute the gate input.
// gate_input_t := W_hc * h_conted_{t-1} + W_xc * x_t + b_c
// = W_hc_h_{t-1} + W_xc_x_t + b_c
{
LayerParameter* input_sum_layer = net_param->add_layer();
input_sum_layer->CopyFrom(sum_param);
input_sum_layer->set_name("gate_input_" + ts);
input_sum_layer->add_bottom("W_hc_h_" + tm1s);
input_sum_layer->add_bottom("W_xc_x_r_" + ts);
if (this->static_input_) {
input_sum_layer->add_bottom("W_xc_x_static");
}
input_sum_layer->add_top("gate_input_" + ts);
}
// Add LSTMUnit layer to compute the cell & hidden vectors c_t and h_t.
// Inputs: c_{t-1}, gate_input_t = (i_t, f_t, o_t, g_t), cont_t
// Outputs: c_t, h_t
// [ i_t' ]
// [ f_t' ] := gate_input_t
// [ o_t' ]
// [ g_t' ]
// i_t := \sigmoid[i_t']
// f_t := \sigmoid[f_t']
// o_t := \sigmoid[o_t']
// g_t := \tanh[g_t']
// c_t := cont_t * (f_t .* c_{t-1}) + (i_t .* g_t)
// h_t := o_t .* \tanh[c_t]
{
LayerParameter* lstm_unit_param = net_param->add_layer();
lstm_unit_param->set_type("LSTMUnit");
lstm_unit_param->add_bottom("c_" + tm1s);
lstm_unit_param->add_bottom("gate_input_" + ts);
lstm_unit_param->add_bottom("cont_" + ts);
lstm_unit_param->add_top("c_" + ts);
lstm_unit_param->add_top("h_" + ts);
lstm_unit_param->set_name("unit_" + ts);
}
output_concat_layer.add_bottom("h_" + ts);
output_m_layer.add_bottom("mask_" + tm1s);
} // for (int t = 1; t <= this->T_; ++t)
{
LayerParameter* c_T_copy_param = net_param->add_layer();
c_T_copy_param->CopyFrom(split_param);
c_T_copy_param->add_bottom("c_" + this->int_to_str(this->T_));
c_T_copy_param->add_top("c_T");
}
net_param->add_layer()->CopyFrom(output_concat_layer);
net_param->add_layer()->CopyFrom(output_m_layer);
}
INSTANTIATE_CLASS(ALSTMLayer);
REGISTER_LAYER_CLASS(ALSTM);
} // namespace caffe
#ifndef CAFFE_SEQUENCE_LAYERS_HPP_
#define CAFFE_SEQUENCE_LAYERS_HPP_
#include
#include
#include
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/layer.hpp"
#include "caffe/net.hpp"
#include "caffe/proto/caffe.pb.h"
namespace caffe {
template class RecurrentLayer;
/**
* @brief An abstract class for implementing recurrent behavior inside of an
* unrolled network. This Layer type cannot be instantiated -- instaed,
* you should use one of its implementations which defines the recurrent
* architecture, such as RNNLayer or LSTMLayer.
*/
template
class RecurrentLayer : public Layer {
public:
explicit RecurrentLayer(const LayerParameter& param)
: Layer(param) {}
virtual void LayerSetUp(const vector*>& bottom,
const vector*>& top);
virtual void Reshape(const vector*>& bottom,
const vector*>& top);
virtual void Reset();
virtual inline const char* type() const { return "Recurrent"; }
virtual inline int MinBottomBlobs() const { return 2; }
virtual inline int MaxBottomBlobs() const { return 3; }
//virtual inline int ExactNumTopBlobs() const { return 2; }
virtual inline int MinTopBlobs() const {return 1; }
virtual inline int MaxTopBlobs() const {return 2; }
virtual inline bool AllowForceBackward(const int bottom_index) const {
// Can't propagate to sequence continuation indicators.
return bottom_index != 1;
}
protected:
/**
* @brief Fills net_param with the recurrent network arcthiecture. Subclasses
* should define this -- see RNNLayer and LSTMLayer for examples.
*/
virtual void FillUnrolledNet(NetParameter* net_param) const = 0;
/**
* @brief Fills names with the names of the 0th timestep recurrent input
* Blob&s. Subclasses should define this -- see RNNLayer and LSTMLayer
* for examples.
*/
virtual void RecurrentInputBlobNames(vector* names) const = 0;
/**
* @brief Fills names with the names of the Tth timestep recurrent output
* Blob&s. Subclasses should define this -- see RNNLayer and LSTMLayer
* for examples.
*/
virtual void RecurrentOutputBlobNames(vector* names) const = 0;
/**
* @brief Fills names with the names of the output blobs, concatenated across
* all timesteps. Should return a name for each top Blob.
* Subclasses should define this -- see RNNLayer and LSTMLayer for
* examples.
*/
virtual void OutputBlobNames(vector* names) const = 0;
/**
* @param bottom input Blob vector (length 2-3)
*
* -# @f$ (T \times N \times ...) @f$
* the time-varying input @f$ x @f$. After the first two axes, whose
* dimensions must correspond to the number of timesteps @f$ T @f$ and
* the number of independent streams @f$ N @f$, respectively, its
* dimensions may be arbitrary. Note that the ordering of dimensions --
* @f$ (T \times N \times ...) @f$, rather than
* @f$ (N \times T \times ...) @f$ -- means that the @f$ N @f$
* independent input streams must be "interleaved".
*
* -# @f$ (T \times N) @f$
* the sequence continuation indicators @f$ \delta @f$.
* These inputs should be binary (0 or 1) indicators, where
* @f$ \delta_{t,n} = 0 @f$ means that timestep @f$ t @f$ of stream
* @f$ n @f$ is the beginning of a new sequence, and hence the previous
* hidden state @f$ h_{t-1} @f$ is multiplied by @f$ \delta_t = 0 @f$
* and has no effect on the cell's output at timestep @f$ t @f$, and
* a value of @f$ \delta_{t,n} = 1 @f$ means that timestep @f$ t @f$ of
* stream @f$ n @f$ is a continuation from the previous timestep
* @f$ t-1 @f$, and the previous hidden state @f$ h_{t-1} @f$ affects the
* updated hidden state and output.
*
* -# @f$ (N \times ...) @f$ (optional)
* the static (non-time-varying) input @f$ x_{static} @f$.
* After the first axis, whose dimension must be the number of
* independent streams, its dimensions may be arbitrary.
* This is mathematically equivalent to using a time-varying input of
* @f$ x'_t = [x_t; x_{static}] @f$ -- i.e., tiling the static input
* across the @f$ T @f$ timesteps and concatenating with the time-varying
* input. Note that if this input is used, all timesteps in a single
* batch within a particular one of the @f$ N @f$ streams must share the
* same static input, even if the sequence continuation indicators
* suggest that difference sequences are ending and beginning within a
* single batch. This may require padding and/or truncation for uniform
* length.
*
* @param top output Blob vector (length 1)
* -# @f$ (T \times N \times D) @f$
* the time-varying output @f$ y @f$, where @f$ D @f$ is
* recurrent_param.num_output().
* Refer to documentation for particular RecurrentLayer implementations
* (such as RNNLayer and LSTMLayer) for the definition of @f$ y @f$.
*/
virtual void Forward_cpu(const vector*>& bottom,
const vector*>& top);
virtual void Forward_gpu(const vector*>& bottom,
const vector*>& top);
virtual void Backward_cpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
/// @brief A helper function, useful for stringifying timestep indices.
virtual string int_to_str(const int t) const;
/// @brief A Net to implement the Recurrent functionality.
shared_ptr > unrolled_net_;
/// @brief The number of independent streams to process simultaneously.
int N_;
/**
* @brief The number of timesteps in the layer's input, and the number of
* timesteps over which to backpropagate through time.
*/
int T_;
/// @brief Whether the layer has a "static" input copied across all timesteps.
bool static_input_;
vector* > recur_input_blobs_;
vector* > recur_output_blobs_;
vector* > output_blobs_;
Blob* x_input_blob_;
Blob* x_static_input_blob_;
Blob* cont_input_blob_;
};
/**
* @brief Processes sequential inputs using a "Long Short-Term Memory" (LSTM)
* [1] style recurrent neural network (RNN). Implemented as a network
* unrolled the LSTM computation in time.
*
*
* The specific architecture used in this implementation is as described in
* "Learning to Execute" [2], reproduced below:
* i_t := \sigmoid[ W_{hi} * h_{t-1} + W_{xi} * x_t + b_i ]
* f_t := \sigmoid[ W_{hf} * h_{t-1} + W_{xf} * x_t + b_f ]
* o_t := \sigmoid[ W_{ho} * h_{t-1} + W_{xo} * x_t + b_o ]
* g_t := \tanh[ W_{hg} * h_{t-1} + W_{xg} * x_t + b_g ]
* c_t := (f_t .* c_{t-1}) + (i_t .* g_t)
* h_t := o_t .* \tanh[c_t]
* In the implementation, the i, f, o, and g computations are performed as a
* single inner product.
*
* Notably, this implementation lacks the "diagonal" gates, as used in the
* LSTM architectures described by Alex Graves [3] and others.
*
* [1] Hochreiter, Sepp, and Schmidhuber, J黵gen. "Long short-term memory."
* Neural Computation 9, no. 8 (1997): 1735-1780.
*
* [2] Zaremba, Wojciech, and Sutskever, Ilya. "Learning to execute."
* arXiv preprint arXiv:1410.4615 (2014).
*
* [3] Graves, Alex. "Generating sequences with recurrent neural networks."
* arXiv preprint arXiv:1308.0850 (2013).
*/
template
class LSTMLayer : public RecurrentLayer {
public:
explicit LSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "LSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class LSTMStaticLayer : public RecurrentLayer {
public:
explicit LSTMStaticLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "LSTMStatic"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class LSTMStaticNewLayer : public RecurrentLayer {
public:
explicit LSTMStaticNewLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "LSTMStaticNew"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class ASLSTMLayer : public RecurrentLayer {
public:
explicit ASLSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "ASLSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class ADLSTMLayer : public RecurrentLayer {
public:
explicit ADLSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "ADLSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class ALSTMLayer : public RecurrentLayer {
public:
explicit ALSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "ALSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
//coupled LSTM layer
template
class CLSTMLayer : public RecurrentLayer {
public:
explicit CLSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "CLSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
//coupled LSTM layer
template
class ACLSTMLayer : public RecurrentLayer {
public:
explicit ACLSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "ACLSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class ACTLSTMLayer : public RecurrentLayer {
public:
explicit ACTLSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "ACTLSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class ACSLSTMLayer : public RecurrentLayer {
public:
explicit ACSLSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "ACSLSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class ACSSLSTMLayer : public RecurrentLayer {
public:
explicit ACSSLSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "ACSSLSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class ACSSLSTMStaticLayer : public RecurrentLayer {
public:
explicit ACSSLSTMStaticLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "ACSSLSTMStatic"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
template
class ATLSTMLayer : public RecurrentLayer {
public:
explicit ATLSTMLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "ATLSTM"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
/**
* @brief A helper for LSTMLayer: computes a single timestep of the
* non-linearity of the LSTM, producing the updated cell and hidden
* states.
*/
template
class LSTMUnitLayer : public Layer {
public:
explicit LSTMUnitLayer(const LayerParameter& param)
: Layer(param) {}
virtual void Reshape(const vector*>& bottom,
const vector*>& top);
virtual inline const char* type() const { return "LSTMUnit"; }
virtual inline int ExactNumBottomBlobs() const { return 3; }
virtual inline int ExactNumTopBlobs() const { return 2; }
virtual inline bool AllowForceBackward(const int bottom_index) const {
// Can't propagate to sequence continuation indicators.
return bottom_index != 2;
}
protected:
/**
* @param bottom input Blob vector (length 3)
* -# @f$ (1 \times N \times D) @f$
* the previous timestep cell state @f$ c_{t-1} @f$
* -# @f$ (1 \times N \times 4D) @f$
* the "gate inputs" @f$ [i_t', f_t', o_t', g_t'] @f$
* -# @f$ (1 \times 1 \times N) @f$
* the sequence continuation indicators @f$ \delta_t @f$
* @param top output Blob vector (length 2)
* -# @f$ (1 \times N \times D) @f$
* the updated cell state @f$ c_t @f$, computed as:
* i_t := \sigmoid[i_t']
* f_t := \sigmoid[f_t']
* o_t := \sigmoid[o_t']
* g_t := \tanh[g_t']
* c_t := cont_t * (f_t .* c_{t-1}) + (i_t .* g_t)
* -# @f$ (1 \times N \times D) @f$
* the updated hidden state @f$ h_t @f$, computed as:
* h_t := o_t .* \tanh[c_t]
*/
virtual void Forward_cpu(const vector*>& bottom,
const vector*>& top);
virtual void Forward_gpu(const vector*>& bottom,
const vector*>& top);
/**
* @brief Computes the error gradient w.r.t. the LSTMUnit inputs.
*
* @param top output Blob vector (length 2), providing the error gradient with
* respect to the outputs
* -# @f$ (1 \times N \times D) @f$:
* containing error gradients @f$ \frac{\partial E}{\partial c_t} @f$
* with respect to the updated cell state @f$ c_t @f$
* -# @f$ (1 \times N \times D) @f$:
* containing error gradients @f$ \frac{\partial E}{\partial h_t} @f$
* with respect to the updated cell state @f$ h_t @f$
* @param propagate_down see Layer::Backward.
* @param bottom input Blob vector (length 3), into which the error gradients
* with respect to the LSTMUnit inputs @f$ c_{t-1} @f$ and the gate
* inputs are computed. Computatation of the error gradients w.r.t.
* the sequence indicators is not implemented.
* -# @f$ (1 \times N \times D) @f$
* the error gradient w.r.t. the previous timestep cell state
* @f$ c_{t-1} @f$
* -# @f$ (1 \times N \times 4D) @f$
* the error gradient w.r.t. the "gate inputs"
* @f$ [
* \frac{\partial E}{\partial i_t}
* \frac{\partial E}{\partial f_t}
* \frac{\partial E}{\partial o_t}
* \frac{\partial E}{\partial g_t}
* ] @f$
* -# @f$ (1 \times 1 \times N) @f$
* the gradient w.r.t. the sequence continuation indicators
* @f$ \delta_t @f$ is currently not computed.
*/
virtual void Backward_cpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
virtual void Backward_gpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
/// @brief The hidden and output dimension.
int hidden_dim_;
Blob X_acts_;
};
/**
* @brief Processes time-varying inputs using a simple recurrent neural network
* (RNN). Implemented as a network unrolling the RNN computation in time.
*
* Given time-varying inputs @f$ x_t @f$, computes hidden state @f$
* h_t := \tanh[ W_{hh} h_{t_1} + W_{xh} x_t + b_h ]
* @f$, and outputs @f$
* o_t := \tanh[ W_{ho} h_t + b_o ]
* @f$.
*/
template
class RNNLayer : public RecurrentLayer {
public:
explicit RNNLayer(const LayerParameter& param)
: RecurrentLayer(param) {}
virtual inline const char* type() const { return "RNN"; }
protected:
virtual void FillUnrolledNet(NetParameter* net_param) const;
virtual void RecurrentInputBlobNames(vector* names) const;
virtual void RecurrentOutputBlobNames(vector* names) const;
virtual void OutputBlobNames(vector* names) const;
};
} // namespace caffe
#endif // CAFFE_SEQUENCE_LAYERS_HPP_ 代码就不注释了,有问题可以留言。代码主要是在LSTM Unit前进行一些数据预处理,计算出Mask(即Attention),这里给出attention的计算方式,方便大家理解代码。
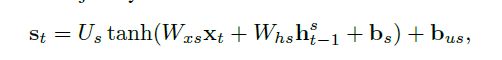
然后把S接入softmax进行[0,1]压缩。关于tanh这个函数可以更换成其他方式。

补充:博主推了半天的维度,参考LSTM layer,测试成功。但是博主参考一篇AAAI论文对一些joint坐标进行attention,改动代码测试失败,发邮件给作者无人回复,严重怀疑造假。为什么坐标就不行呢?因为上述代码是写图片的区域的,而坐标就3个点,维度太低。