Groovy入门-字符串处理与正则表达式
字符串处理-1
println ‘lxt008 said "Groovy"'
println "lxt008 said 'Grails'"
def str1 = 'Groovy&Grails&lxt008'
println str1[4] //v,同getAt(4)
println str1[-1] //8
println str1[1..2] //ro
println str1[1..<3] //ro
println str1[4..2] //voo
println str1[4,1,6] //vr&
println str1 == 'Groovy&Grails&lxt008' //true字符串处理2
println 'lxt008' <=> 'lxt008' //0
println 'lxt' <=> 'lxt008' //-1
println 'lxt008' <=> 'Lxt008' //1
println 'lxt008'.compareTo('Lxt008') //32
println 'Groovy' + '&Grails' + '&lxt008' //Groovy&Grails&lxt008
println 'Groovy' * 3 //GroovyGroovyGroovy
println str1.length() //20
println str1 - 'lxt008' //Groovy&Grails字符串处理3
println "Groovy".compareToIgnoreCase("groocy") //0
println "Groovy".concat("&Grails") //Groovy&Grails
println "Groovy".endsWith("ovy") //true
println "Groovy".equalsIgnoreCase("groovy") //true
println "Groovy".indexOf("oo") //2
println "Groovy&Grails".indexOf("G",6) //7
println "Groovy".substring(2) //oovy
println "Groovy".substring(2,4) //oo字符串处理4
def str2 = 'Groovy'
println "[${str2.center(11)}]" //[ Groovy ]
println "[${str2.center(3)}]" //[Groovy]
println "[${str.center(11,'=')}]" //[==Groovy===]
println "${str2.contain('Gr')}" //true
println "${str2.count('o')}" //2
println "${str2.count('oo')}" //1
println str2.leftShift('world') //Groovy world
println str2 << 'world' //Groovy world字符串处理5
println str2.minus('vy') //Groo
println str2 - 'vy' //Groo
println str2.next() //Groovz ++ 运算符
println str2.previous() //Groovx -- 运算符
def str3 = "lxt008"
println "[${str3.padLeft(4)}]" //lxt008
println "[${str3.padLeft(11)}]" //[ lxt008]
println "[${str3.padLeft(11,'#')}]" //[#####lxt008]
//padRight类似字符串处理6
def str4 = "Groovy&Grails&lxt008"
println str4.replaceAll('[a-z]'){ ch ->
ch.toUpperCase()
}//GROOVY&GRAILS&LXT008
println str4.reverse() //800txl&sliarG&yvoorG
println str4.size() //20
println str4.toCharacter() //G
println '123'.toDouble() //123.0 toFloat()/toInteger()/toLong()类似
println str4.toList() //["G","r","o","o","v","y","&","G","r","a","i","l","s","&","l","x","t","t","0","0","8"]字符串处理7
println str4.tokenize() //["Groovy&Grails&lxt008"],无空格
println str4.tokenize('&') //["Groovy","Grails","lxt008"]
def str5 = 'Groovy Grails lxt008'
println str5.tokenize() //["Groovy","Grails","lxt008"]
println str5.tokenize().getClass().getName() //java.util.ArrayList正则表达式
正则表达式在Groovy中是本地语言级别的支持。
def aRegex = ~’lxt’
println aRegex.class //输出:class java.util.regex.Pattern
def mat = ‘lxt’ = ~’lxt’
println mat.class //class java.util.regex.Matcher
结论:~开头的字符串是模式Pattern对象
//部分匹配
assert ‘lxt008’ = ~’lxt’
assert !(‘lxt008’ = ~’lxt’)
assert ‘lxt008’ = ~regex
assert !(‘lxt008’ == ~’lxt’) //精确匹配
正则表达式的元字符

正则表达式的辅助符号
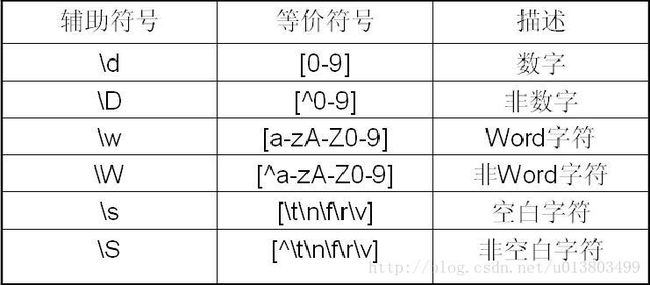
正则表达式补充
在Java 与 Groovy 中把’\’作为转义符会有冲突,所以一般使用’\’表示转义符
assert ‘1.2’ == ~’\d.\d’ //\d表示一个数字
assert ‘1 a’ == ~’\d\s\w’ //\s为空格 \w为字符
def datePattern = ‘([A-Z]{3})\s([0-9]{1,2}),\s([0-9]{4})’
def date = ‘NOV 28, 2008’
def matcher = date = ~datePattern
matcher.matches()
assert date = ~datePattern //无断言错误
println matcher[0] //[“NOV 28, 2008”,”Nov”,”28”,”2008”]
println matcher[0][0] //NOV 28,2008
println matcher[0][1] //NOV
println matcher[0][2] //28
println matcher[0][3] //2008