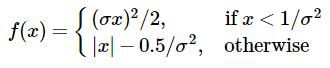Faster RCNN代码详解(二):网络结构构建
在上一篇博客中介绍了Faster RCNN算法的整体结构:Faster RCNN代码详解(一):算法整体结构,在该结构中最主要的两部分是网络结构的构建和数据的读取,因此这篇博客就来介绍下Faster RCNN算法的网络结构构建细节。因为其中特征提取网络选择多样,所以这里以常用的ResNet为例来介绍。
这部分内容非常重要,因为这里我将详细介绍RPN网络的结构、RPN网络的损失函数、proposal的生成、Roi Pooling层、检测网络的结构、检测网络的损失函数等细节,也就是论文中的Figure2。从最近两年follow的论文来看,大部分都是在网络结构上做改进,比如R-FCN是在Roi Pooling层做了调整,FPN是基于融合后的多层特征做检测等。因此了解清楚Faster RCNN算法的网络结构对后续理解基于Faster RCNN算法的改进非常有帮助,而了解网络结构的最好办法就是阅读代码。
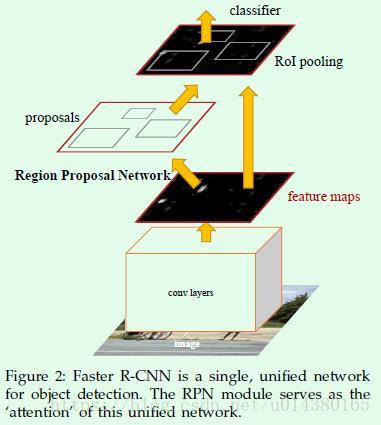
网络结构的构造通过get_resnet_train函数进行,该函数所在脚本:~mx-rcnn/rcnn/symbol/symbol_resnet.py。接下来就来看看该函数的代码细节:
def get_resnet_train(num_classes=config.NUM_CLASSES,num_anchors=config.NUM_ANCHORS):
# 这里设置了几个变量,其中参数name的命名和数据读取类AnchorLoader的provide_data和
# provide_label属性是对应相同的,如果两处命名冲突则会报错。
data = mx.symbol.Variable(name="data")
im_info = mx.symbol.Variable(name="im_info")
gt_boxes = mx.symbol.Variable(name="gt_boxes")
rpn_label = mx.symbol.Variable(name='label')
rpn_bbox_target = mx.symbol.Variable(name='bbox_target')
rpn_bbox_weight = mx.symbol.Variable(name='bbox_weight')
# shared convolutional layers
# get_resnet_conv方法返回的是ResNet网络从conv1到conv4_x的部分,该部分就是用来做特征提取的,
# 之所以这些层叫shared convolutional layers,是因为输出conv_feat不仅仅作为接下来RPN网络的输入,
# 还作为后续的ROI Pooling的输入。另外关于conv_feat的维度大小,假设输入图像大小为600*800,
# 则conv_feat的feature map大小是38*50。
# 接下来关于输出feature map的维度分析时都基于输入大小是600*800的假设,这样理解起来比较清晰。
conv_feat = get_resnet_conv(data)
# RPN layers
# 接下来这一部分是RPN网络的层,输入就是ResNet的conv4_x层的输出,也就是conv_feat。
# 首先说明一下anchor和region proposal(后面就用proposal代替)的区别:
# anchor是固定不变的(可以参考~/mx-rcnn/rcnn/io/rpn.py的assign_anchor函数,
# 系列四博客也会介绍),只是一个初始值或者参考值,其标签通过和ground truth计算
# IOU后就可以得到,也是固定的,而proposal是模型预测的框(RPN网络的目的
# 就是输出proposal,这个输出的proposal要尽可能和ground truth接近),
# 当然anchor和proposal并不是相互独立的,其实每个proposal都和一个anchor对应,
# 所以anchor和proposal的数量是一样的。RPN的网络结构非常简单,
# 先是一个3*3的卷积层,这个3*3的卷积层就对应论文中的sliding window操作。
# 然后基于该卷积层的输出引出两条支路(这两条支路都用1*1卷积层实现),
# 一条支路用来预测proposal的标签(卷积核数量是2*anchor数量,表示每个anchor属于背景类和目标类的概率);
# 另一条支路用来预测proposal的坐标偏置(卷积核数量是4*anchor数量,表示每个anchor的四个坐标信息的偏置)。
rpn_conv = mx.symbol.Convolution(
data=conv_feat, kernel=(3, 3), pad=(1, 1), num_filter=512, name="rpn_conv_3x3")
rpn_relu = mx.symbol.Activation(data=rpn_conv, act_type="relu", name="rpn_relu")
# num_anchors默认是9,因此输出rpn_cls_score的维度就是1*18*38*50,
# 也就是说一共有17100(9*38*50)个anchor(proposal)。
rpn_cls_score = mx.symbol.Convolution(
data=rpn_relu, kernel=(1, 1), pad=(0, 0), num_filter=2 * num_anchors, name="rpn_cls_score")
# 输出rpn_bbox_pred的维度是1*36*38*50。
rpn_bbox_pred = mx.symbol.Convolution(
data=rpn_relu, kernel=(1, 1), pad=(0, 0), num_filter=4 * num_anchors, name="rpn_bbox_pred")
# prepare rpn data
# 输出rpn_cls_score_reshape的维度是1*2*342*50,可以看出这个reshape操作主要是将
# 前面得到的rpn_cls_score的第二个维度变成2,至于为什么要做这个reshape操作可以看下面的分类层。
rpn_cls_score_reshape = mx.symbol.Reshape(
data=rpn_cls_score, shape=(0, 2, -1, 0), name="rpn_cls_score_reshape")
# classification
# RPN网络关于proposal类别的预测采用cross entropy损失函数(SoftmaxOutput接口),
# 注意参数ignore_label=-1表示数据中标签等于-1的不进行损失回传,也就是不参与梯度更新。
# 因此只有标签是1或0的anchor才会参与分类的损失传递和梯度更新(在Faster RCNN算法中,
# anchor一共有3种标签:-1、0、1,分别表示无效、背景、目标,这部分会在数据读取中再详细讲解)。
# 从后续anchor的标签设置可以看出标签为0和1的anchor总数是256,
# 这个参数也是参与RPN网络分类损失回传和梯度更新的anchor数量,
# 可以看默认配置文件config.py中的TRAIN.RPN_BATCH_SIZE=256,所以虽然有9*38*50个anchor,
# 但是真正有用的只有256个。multi_output=True这个参数会使计算softmax值时是沿着axis为1的维度进行的,
# 这个主要用在输入中data(这里是4维)和label(这里是2维)的维度不一样的情况下。
# 既然是沿着axis为1的维度,那么该维度的大小就是类别数,也就是2,
# 对应前面reshape时shape=(0,2,-1,0)中的第二个值2。其实在分类网络中multi_output参数都是采用默认值,
# 因为data和label都是二维的,但是在计算softmax过程中也是按行来计算的。
rpn_cls_prob = mx.symbol.SoftmaxOutput(data=rpn_cls_score_reshape, label=rpn_label, multi_output=True, normalization='valid', use_ignore=True, ignore_label=-1, name="rpn_cls_prob")
# bounding box regression
# RPN网络关于proposal坐标的预测采用smoothl1损失函数,rpn_bbox_weight是anchor的mask,
# 换句话说,如果某个anchor的标签是1,则mask对应值为1,anchor的标签是0或-1,则mask对应值为0。
# 因此只有标签是1的anchor才会参与坐标回归的损失传递和梯度更新。可以看到smooth_l1接口传入
# 的data数据是(rpn_bbox_pred - rpn_bbox_target),其实rpn_bbox_target是根据
# 初始anchor和ground truth计算出来的offset(可以参考论文中公式2的后面两行);
# 而RPN网络预测的值是rpn_bbox_pred,这个值并不是预测框的坐标,而是预测框的坐标和
# 初始anchor之间的offset(可以参考论文中公式2的前面两行),只要这两个offset足够接近,
# 则预测框就和ground truth足够接近。另外scalar参数是smoothl1公式中的参数,可看最
# 后附录公式中的σ。参数grad_scale=1.0 / config.TRAIN.RPN_BATCH_SIZE表示回归损失占RPN网络
# 总损失的比例,这个参数相差几个量级对最后的结果影响也不会太大,这里默认是256。至此,RPN网络就结束了。
rpn_bbox_loss_ = rpn_bbox_weight * mx.symbol.smooth_l1(name='rpn_bbox_loss_', scalar=3.0, data=(rpn_bbox_pred - rpn_bbox_target))
rpn_bbox_loss = mx.sym.MakeLoss(name='rpn_bbox_loss', data=rpn_bbox_loss_, grad_scale=1.0 / config.TRAIN.RPN_BATCH_SIZE)
# ROI proposal
# ROI proposal这一部分的最终目的是对前面RPN网络生成的proposal做过滤,因为proposal总数较多,
# 而且多数proposal之间都是相互重叠的,因此考虑到效率,需要对proposal做过滤。
# 过滤采用的是NMS算法,但是NMS算法需要基于某一个值来做过滤,
# 这里采用的是proposal的预测概率值,因此接下来这一部分就是用来得到proposal的预测概率的。
# rpn_cls_act就是用softmax层得到类别概率(SoftmaxActivation和SoftmaxOutput的共同点是都执行了softmax计算,
# 不同点在于前者没有计算和回传损失,后者有计算cross entropy),
# 因此这里用SoftmaxActivation只是为了计算概率,
# 不涉及损失回传,所以输入中也没有label这个参数。
# mode设置为“channel”是因为输入维度超过二维(这里是4维)。
# 需要注意的是在MXNet框架中已经不再使用SoftmaxActivation接口,改用softmax接口。
# 最后rpn_cls_act_reshape的维度是1*18*38*50。
rpn_cls_act = mx.symbol.SoftmaxActivation(
data=rpn_cls_score_reshape, mode="channel", name="rpn_cls_act")
rpn_cls_act_reshape = mx.symbol.Reshape(
data=rpn_cls_act, shape=(0, 2 * num_anchors, -1, 0), name='rpn_cls_act_reshape')
# 得到proposal的预测概率后,接下来就用mx.contrib.symbol.Proposal接口对RPN网络生成
# 的proposal通过NMS算法过滤掉那些重合度很高的proposal,也就是对应条件语句
# if config.TRAIN.CXX_PROPOSAL。参数rpn_cls_act_reshape是预测的proposal类别概率,
# 维度是1*18*38*50。参数rpn_bbox_pred是预测的proposal坐标偏置,维度是1*36*38*50。
# 参数im_info维度是1*3,表示图像的宽高和scale信息。
# 参数config.TRAIN.RPN_PRE_NMS_TOP_N默认是12000,表示在对RPN网络输出的anchor
# 进行NMS操作之前的proposal最大数量。我们知道输入proposal的数量是17100,根据这17100个proposal的
# 预测为foreground的概率(也叫score,换句话说就是预测标签为1的概率)从高到低排序,
# 然后选择前面12000个即可。TRAIN.RPN_POST_NMS_TOP_N默认是2000,表示经
# 过NMS过滤之后得到的proposal数量。config.TRAIN.RPN_NMS_THRESH默认是0.7,是NMS算法的阈值。
# config.TRAIN.RPN_MIN_SIZE默认是16。最后该层输出的roi的维度是2000*5,第一列都是0,
# 并不表示roi的标签,而是表示batch的index,剩下四列是roi的坐标(左上角和右下角,与输入图像尺寸对应)。
# 作者通过实验证明这种NMS操作并不会对最终结果有太大影响,需要注意的是测试模型的时候不会进行这样的NMS操作。
if config.TRAIN.CXX_PROPOSAL:
rois = mx.contrib.symbol.Proposal(
cls_prob=rpn_cls_act_reshape, bbox_pred=rpn_bbox_pred, im_info=im_info, name='rois',
feature_stride=config.RPN_FEAT_STRIDE, scales=tuple(config.ANCHOR_SCALES), ratios=tuple(config.ANCHOR_RATIOS),
rpn_pre_nms_top_n=config.TRAIN.RPN_PRE_NMS_TOP_N, rpn_post_nms_top_n=config.TRAIN.RPN_POST_NMS_TOP_N,
threshold=config.TRAIN.RPN_NMS_THRESH, rpn_min_size=config.TRAIN.RPN_MIN_SIZE)
else:
rois = mx.symbol.Custom(
cls_prob=rpn_cls_act_reshape, bbox_pred=rpn_bbox_pred, im_info=im_info, name='rois',
op_type='proposal', feat_stride=config.RPN_FEAT_STRIDE,
scales=tuple(config.ANCHOR_SCALES), ratios=tuple(config.ANCHOR_RATIOS),
rpn_pre_nms_top_n=config.TRAIN.RPN_PRE_NMS_TOP_N, rpn_post_nms_top_n=config.TRAIN.RPN_POST_NMS_TOP_N,
threshold=config.TRAIN.RPN_NMS_THRESH, rpn_min_size=config.TRAIN.RPN_MIN_SIZE)
# 综上就得到了论文中所说的RPN网络输出一系列的object proposal(对应这里的rois变量),
# 每个都带有一个objectness score的过程(对应这里的rpn_cls_act_reshape 变量)。
# ROI proposal target
# 首先reshape操作是因为输入gt_boxes是3维的,这里需要的是2维的输入。
# 自定义层主要就是根据前面过滤得到的roi对gt_boxes_reshappe也进行过滤,
# 具体实现在~/mx-rcnn/rcnn/symbol/proposal_target.py脚本。
# 输入rois就是前面得到的2000*5的roi信息;gt_boxes_reshape是x*5的ground truth信息,
# x表示object数量;num_classes是实际要分类的类别数加上背景类,
# 比如对于VOC数据集而已这里num_classes就是21;config.TRAIN.BATCH_IMAGES默认是1;
# config.TRAIN.BATCH_ROIS默认是128;config.TRAIN.FG_FRACTION是正样本所占的比例,
# 默认是0.25,也就是正负样本的比例是1:3。最后得到的goup变量就是过滤后的结果集合,group[0]是rois,
# 维度是128*5,这个128是默认的roi的batch size,要注意5列中除了4个坐标列外,另一列是index,而不是标签。
# group[1]是label,也就是roi对应的标签。group[2]是bbox_target,是坐标回归的目标,维度是(128,84),
# 84来自VOC的20类:(20+1)*4。group[3]是bbox_weight,是坐标回归时候的权重,维度是(128,84),
# 这个权重对于foreground都是1,对于backgroud都是0。
gt_boxes_reshape = mx.symbol.Reshape(data=gt_boxes, shape=(-1, 5), name='gt_boxes_reshape')
group = mx.symbol.Custom(rois=rois, gt_boxes=gt_boxes_reshape, op_type='proposal_target',
num_classes=num_classes, batch_images=config.TRAIN.BATCH_IMAGES,
batch_rois=config.TRAIN.BATCH_ROIS, fg_fraction=config.TRAIN.FG_FRACTION)
rois = group[0]
label = group[1]
bbox_target = group[2]
bbox_weight = group[3]
# Fast R-CNN
# 这一步是执行ROI Pooling操作。ROI Pooling是Faster RCNN对Fast RCNN较大的改进,
# 旨在将大小不一的ROI处理成统一的大小。该接口的一个输入是conv_feat,该symbol在最开始的时候已经介绍过了,
# 是特征提取网络的输出,feature map的维度是1*1024*38*50;另一个输入是rois,维度是128*5,
# 数值的大小空间是和输入图像一致的。另外pooled_sized参数就是处理后得到的统一的roi大小,
# 因为该操作是对conv_feat进行的(size是38*50),所以这里的参数设置为14*14是比较合理的。
# 最后输出的roi_pool的维度是(128,1024,14,14)。
roi_pool = mx.symbol.ROIPooling(
name='roi_pool5', data=conv_feat, rois=rois, pooled_size=(14, 14), spatial_scale=1.0 / config.RCNN_FEAT_STRIDE)
# res5
# 接下来是ResNet网络的conv5_x部分,输入中roi_pool就是前面ROIPooling层的输出。
# filter_list[3]等于2048。最后一个Pooling层的输出pool1的维度是(128,2048,1,1)。
unit = residual_unit(data=roi_pool, num_filter=filter_list[3], stride=(2, 2), dim_match=False, name='stage4_unit1')
for i in range(2, units[3] + 1):
unit = residual_unit(data=unit, num_filter=filter_list[3], stride=(1, 1), dim_match=True, name='stage4_unit%s' % i)
bn1 = mx.sym.BatchNorm(data=unit, fix_gamma=False, eps=eps, use_global_stats=use_global_stats, name='bn1')
relu1 = mx.sym.Activation(data=bn1, act_type='relu', name='relu1')
pool1 = mx.symbol.Pooling(data=relu1, global_pool=True, kernel=(7, 7), pool_type='avg', name='pool1')
# classification
# 接下来就是整个Faster RCNN网络的分类和回归层的定义了(或者叫Faster RCNN网络中检测部分的分类和回归层的定义)。
# 首先分类层采用的是全连接层,num_classes是分类的类别数,这里是object类别数+背景,
# 比如对于VOC数据集,num_hidden就是21,因此输出得到的cls_score的维度为(128,21)。
# 分类的损失采用的也是和RPN网络一样的SoftmaxOutput层。
cls_score = mx.symbol.FullyConnected(name='cls_score', data=pool1, num_hidden=num_classes)
cls_prob = mx.symbol.SoftmaxOutput(name='cls_prob', data=cls_score, label=label, normalization='batch')
# bounding box regression
# 坐标回归也是采用全连接层,num_classes是4*(object类别数+背景),比如对于VOC数据集,
# num_hidden就是84,因此输出得到的bbox_pred的维度为(128,84)。
# 回归的损失采用的也是和RPN网络一样的smoothl1损失函数,
# 损失函数和bbox_weight相乘表示只有正样本才参与坐标回归的损失回传和梯度更新。
bbox_pred = mx.symbol.FullyConnected(name='bbox_pred', data=pool1, num_hidden=num_classes * 4)
bbox_loss_ = bbox_weight * mx.symbol.smooth_l1(name='bbox_loss_', scalar=1.0, data=(bbox_pred - bbox_target))
bbox_loss = mx.sym.MakeLoss(name='bbox_loss', data=bbox_loss_, grad_scale=1.0 / config.TRAIN.BATCH_ROIS)
# reshape output
# 最后将维度为(128,21)的cls_prob reshape成(config.TRAIN.BATCH_IMAGES,-1,21),
# 默认config.TRAIN.BATCH_IMAGES是1。bbox_loss同理。
label = mx.symbol.Reshape(data=label, shape=(config.TRAIN.BATCH_IMAGES, -1), name='label_reshape')
cls_prob = mx.symbol.Reshape(data=cls_prob, shape=(config.TRAIN.BATCH_IMAGES, -1, num_classes), name='cls_prob_reshape')
bbox_loss = mx.symbol.Reshape(data=bbox_loss, shape=(config.TRAIN.BATCH_IMAGES, -1, 4 * num_classes), name='bbox_loss_reshape')
# mx.symbol.Group接口是将多个损失函数相加进行回传。
group = mx.symbol.Group([rpn_cls_prob, rpn_bbox_loss, cls_prob, bbox_loss, mx.symbol.BlockGrad(label)])
return group这篇博客介绍了Faster RCNN网络结构的构建,当你理解了这部分内容,那么基本上Faster RCNN算法就了解一半了。下一篇博客,我将介绍另一部分重要内容:数据处理:Faster RCNN代码详解(三):数据处理的整体结构。下一篇博客也是先从宏观上对数据读取有个了解,另外要说明的是数据读取和网络结构的输入定义是紧密结合的,继续看下去你就明白我说的话了。
附:
smoothl1公式: