ElasticSearch 学习笔记(四)-----ES在SpringBoot中的集成以及项目应用开发指南
概述
接上一篇ElasticSearch 学习笔记(三)-----ES的设计原理以及分词器说明。今天我们主要介绍ES 与SpringBoot 的集成以及项目应用开发指南。
ES与SpringBoot的集成
添加依赖
此处,添加的依赖一定要与你安装的ES的版本对应,因为我安装的ES版本是 6.4.3。查询
https://github.com/spring-projects/spring-data-elasticsearch 发现对应的spring-data-elasticsearch 为 3.1.x
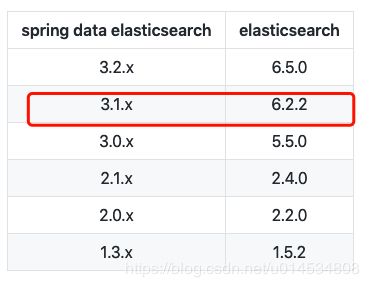
在SpringBoot 中对应依赖spring-boot-starter-data-elasticsearch 的版本为 2.1.1.RELEASE
org.springframework.boot
spring-boot-starter-data-elasticsearch
2.1.1.RELEASE
创建文档
@Data
@Document(indexName = "titleindex",type = "_doc")
public class TitleDocument implements Serializable {
/**
*
*/
@Id
private Long id;
/**
* 选中ik 分词器
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String titlename;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String description;
public TitleDTO() {
}
public TitleDTO(Long id, String titlename, String description) {
this.id = id;
this.titlename = titlename;
this.description = description;
}
}
其中 indexName 与type 分别对应 索引名称和索引类型,如果类比于关系型数据库的话就相当于 库和表。在Spring Data 中每个文档必须要有id,不然数据会插入失败。同时还需要有缺省构造器,不然分页查询会报错。
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
@Field 注解作用到属性之上,上面代码表示的意思是,索引时分词使用 ik_max_word, 搜索时分词使用ik_smart
PS :
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
Dao 层实现
@Component
public interface TitleRepository extends ElasticsearchRepository {
}
此处我们直接继承了ElasticsearchRepository接口,该接口实现了 save ,deleteById,search 等方法,其中save 表示新增或者更新索引,deleteById表示删除索引,search表示查询索引数据。
Service 调用实现
@Autowired
private TitleRepository titleRepository;
/**
* 创建索引
* @param titlename
* @param description
*/
public void save(Long id,String titlename,String description) throws NoSuchAlgorithmException {
TitleDocument titleDocument = new TitleDocument(id, titlename+id, description+id);
titleRepository.save(titleDocument);
}
/**
* 删除索引数据
* @param id
* @return
*/
public boolean delete(Long id) {
titleRepository.deleteById(id);
return true;
}
/**
* 查询所有的文章
* @param searchContent
* @return
*/
public List getTitle(String searchContent) {
QueryStringQueryBuilder builder = new QueryStringQueryBuilder(searchContent);
System.out.println("查询的语句:"+builder);
Iterable searchResult = titleRepository.search(builder);
Iterator iterator = searchResult.iterator();
List list=new ArrayList<>();
while (iterator.hasNext()) {
list.add(iterator.next());
}
return list;
}
/**
* 分页查询
* @param pageNumber
* @param pageSize
* @param searchContent
* @return
*/
public List pageTitle(Integer pageNumber, Integer pageSize, String searchContent) {
// 分页参数
PageRequest pageRequest = PageRequest.of(pageNumber, pageSize);
QueryStringQueryBuilder queryBuilder = new QueryStringQueryBuilder(searchContent);
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withPageable(pageRequest).withQuery(queryBuilder).build();
System.out.println("查询的语句:" + searchQuery.getQuery().toString());
Page search = titleRepository.search(searchQuery);
return search.getContent();
}
controller 调用实现
@RestController
public class TitleController {
@Autowired
private TitleService titleService;
/**
* 给索引添加数据
* @return
*/
@PostMapping("save")
public String save(Long id,String titlename,String description) throws NoSuchAlgorithmException {
titleService.save(id,titlename,description);
return "success";
}
/**
* 删除
* @return
*/
@PostMapping("delete")
public String delete(Long id){
titleService.delete(id);
return "success" ;
}
@PostMapping("deleteDoc")
public String deleteDoc(){
titleService.deleteDoc();
return "success" ;
}
@GetMapping("get")
public List getTitle(String param) {
List titleDocumentList = titleService.getTitle(param);
return titleDocumentList;
}
@GetMapping("page")
public List pageTitle(Integer pageNumber, Integer pageSize, String searchContent) {
List documentList = titleService.pageTitle(pageNumber, pageSize, searchContent);
return documentList;
}
测试示例
@Test
public void save() throws Exception {
for (int i = 0; i < 20; i++) {
titleService.save(Long.parseLong(String.valueOf(i)),"测试名称", "测试内容");
System.out.println("插入第"+i+"条");
}
}

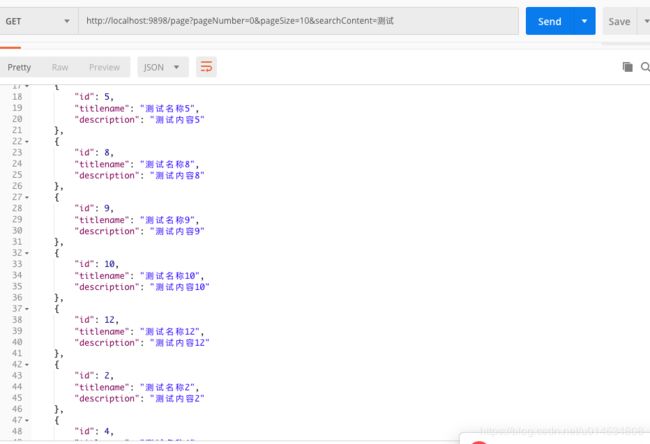
分页查询测试结果:
http://localhost:9898/page?pageNumber=0&pageSize=10&searchContent=测试
可能会遇到的几个问题
- 问题:安装好后Elasticsearch无法运行
解决:可能就是你版本安装错误了,注意版本一定要对应 - 问题:按照首页的方式调用Ik进行解析,但是无法设置mapping,出现如下错误
analyzer [ik_max_word] not found for field
解决:如果你的多个节点的集群,那么在集群的每个实例上都要安装Ik
项目应用开发指南
在项目的实际开发中我们一般遵循如下几个应用指南。
- 第一步,设计索引结构
首先我们需要考虑搜索的内容主体包含的信息,如ID,标题,描述,作者等,还需要考虑排序信息(如更新时间,创建时间) - 第二步,为索引建立对应的模板(DTO)
如同上述demo 中设计的TitleDTO,字段与索引的字段一一对应,另外,因为key的名字都是定死的,为了统一管理,可以给每个key定义成final,方便统一管理和getset等。 - 第三步, 创建SearchService
该SearchService 主要有两个方法,
1、构建索引(创建,更新);
2、 删除索引
首先要一个ID作为唯一要构建的索引,通过ID从数据库中查询信息出来,包括需要关联的表等信息,得到模板数据(DTO),然后去elasticsearch 查询有没有该索引,如果没有则创建,如果有一条则更新,如果有多条则全部删除后重新创建。 - 第四步,当业务数据发生变化时更新索引信息,
当业务数据发生变化时候更新对应索引信息,分为两种形式调用
- 同步调用:直接在业务方法定点调用searchService对应的方法,
- 异步调用:基于消息中间件,如kafka,rabbitmq等。
- 编写搜索业务
当用户没有输入关键字的时候,默认直接从数据库查询信息,当用户输入关键词的时候先从es条件查询出数据的IDs,然后拿ids去数据库中取。
总结
本篇博客,我们首先通过一个demo 来熟悉了ES如何与SpringBoot 进行整合,当然这只是一个小小的demo,具体在项目中还涉及到ES 数据更mysql 数据的同步问题,接着我们还简单介绍了下ES在项目应用开发中的实践指南。
源代码
https://github.com/XWxiaowei/90-Java-demo-2/tree/master/course-21-elasticsearch/elasticsearch-demo
参考文献
SpringBoot整合ElasticSearch实现多版本的兼容