大规模深度强化学习技术概览「AI工程论」
关注:决策智能与机器学习,深耕AI脱水干货

作者 | Flood Sung
来源 | 知乎专栏(https://zhuanlan.zhihu.com/p/145983063)
1 前言
深度学习的发展史就是一部算力的爆炸史,就如下图所示,最新的GPT-3更是达到了好几千Petaflop/s-days,Petaflop/s-days是什么概念呢?1个Petaflop/s-days 代表用每秒计算 次神经网络操作的速度算一天。老实说我也不清楚具体到底有多变态,大概是成千上万台cpu-gpu跑几个月吧。
 https://openai.com/blog/ai-and-compute/
https://openai.com/blog/ai-and-compute/
对于深度强化学习,算力的需求更是强烈,看上图,排在前面的AlphaGoZero,AlphaZero都是深度强化学习的代表,这还是18年的图,还没加上Alphastar和OpenAI Five。想想OpenAI和微软打造的世界排名第五的超算最主要就是用在深度强化学习上,所以这个时代没有大规模的算力基本上不用搞深度强化学习了。
为什么?
因为本来深度学习就需要大量的训练,而深度强化学习仅依靠reward采集样本进行更新,更是非常的低效(sample inefficient),所以就需要不断的训练训练训练。。。
也由此,大规模深度强化学习(Large Scale Deep Reinforcement Learning)成为刚需。
在今天这篇Blog中,我们主要来梳理一下近几年大规模深度强化学习框架的发展情况。
2 大规模深度强化学习要解决什么问题?
大规模深度强化学习要充分的利用大规模的cpu-gpu 计算资源来实现神经网络模型的高效训练。在思考大规模深度强化学习之前,我们先看一下大规模的监督学习要怎么做?
对于一般的监督学习问题,大规模的监督学习需要考虑的问题也就是数据并行(data parallelism)和模型并行(model parallelism)。
 https://course.ie.cuhk.edu.hk/~ierg6130/2019/slide/lecture17_systemdesign.pdf
https://course.ie.cuhk.edu.hk/~ierg6130/2019/slide/lecture17_systemdesign.pdf
大部分情况下我们就考虑数据并行的问题,因为一般模型Model都是串行的,不太需要用多个GPU来做forward。对于数据并行,核心就是使用多台机器分布式的处理不同的数据,然后实现超大batch的数据更新。对于深度学习的训练,一般batch越大,学习效果越快越好。因为我们一直用的是stochastic gradient descent 而不是完全的gradient descent,batch越大,越趋近于完全的gradient descent。看GPT-3 1750亿版本的模型,batch size达到了惊人的320万,想想我们一般训练设置的batch size有1024就不错了,320万真的可以惊到下巴。大规模监督学习不太需要考虑复杂的框架,因为每台机器都可以直接喂数据,只需要把每台机器反向传播得到的梯度gradient取平均更新模型就可以了。
那么大规模深度强化学习有什么不一样呢?最大的不一样就是深度强化学习需要和环境env交互来获取训练数据,才能进行训练。所以,如何采集样本,如何更新网络就成为一个问题,怎么才能最优化的处理实现最高效的训练?特别对于没有那么多机器的团队,如何充分榨干机器的性能是极其重要的问题。
下面我们来看一下近几年来大规模深度强化学习的一些进展。
3 A3C

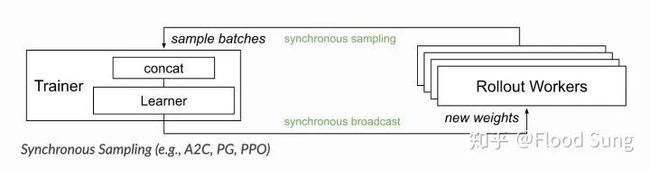
A3C,2016年的paper,现在感觉真的好早。A3C的思想是让每一个worker(CPU)都进行 采样训练的过程,然后把梯度统一传回来取平均更新Global Network,然后Global Network再把参数回传给每一个worker,这里每一个worker更新得到梯度就可以回传,所以是异步的,也使得每一个worker的参数是不一样的,但是这样也导致只能用CPU进行训练。后来OpenAI就提出了A2C,同步版本的,每一个worker仅采集数据,然后集中起来通过GPU进行更新,这样会快很多。也基本上,接下来的架构都不传梯度了,只传数据。
4 Ape-X

Ape-X 看起来思想很简单,面向Off-Policy的算法如DQN,DDPG,有很多个Actor包含Network和Env进行采样,然后把采集的数据统一放到一个Replay Buffer当中,接下来Learner从Replay中取数据训练。这个做法看起来很自然,效果也非常好。
5 IMPALA
IMPALA可以看做是A2C的进阶版,A2C的问题是每一个Actor(worker)都需要采样完毕了才能输送给Learner进行训练,那么IMPALA通过importance sampling的做法来使得Actor和Learner可以相对独立,两者的网络不用完全一样也可以更新(本质上和PPO的做法一样)。


只要数据采集够了,就可以送到learner进行训练,这样速度会快很多。
这里和Ape-X对比不需要replay buffer(放一个来做临时存储也可以),面对的还是偏向于on-policy的DRL算法。对于大规模深度强化学习,有时候因为采样数据够多,反而不需要考虑sample inefficiency的问题了。
6 OpenAI Dota 2
 https://arxiv.org/pdf/1912.06680.pdf
https://arxiv.org/pdf/1912.06680.pdf
对于OpenAI Dota 2 整体架构上和IMPALA并没有本质区别,只不过OpenAI使用PPO而不是V-trace。当然,这里也要注意的是OpenAI把forward也放在GPU上处理的,而不是纯放在CPU上。对于网络巨大的model,放在GPU上forward会更快。
7 Seed RL
前段时间,Google 推出了Seed RL,说是来解决IMPALA存在的问题:

对于上面的问题,其实OpenAI的做法采用GPU进行forward就部分解决了,SEED RL没有太大区别:
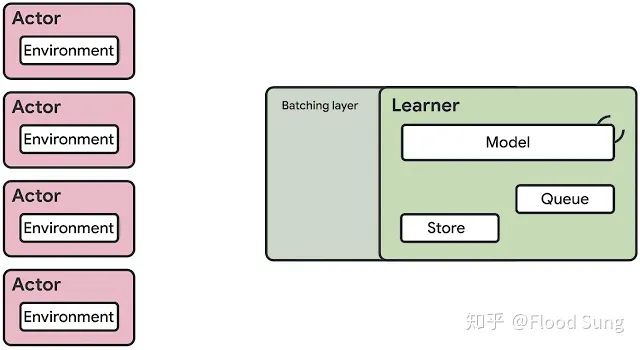
Actor只有Env了,forward直接给model进行处理。只是SEED RL的forward和backward用的是同一个GPU,这样也不涉及数据的传输问题了。OpenAI则是用不同的GPU。
看起来SEED RL相比IMPALA快了很多。
8 ACME
 https://github.com/deepmind/acme/blob/master/paper.pdf
https://github.com/deepmind/acme/blob/master/paper.pdf
ACME前两天才推出,看起来是一个类似RLLib的framework,从设计上并不像SEED RL和OpenAI Dota 2这样优化,而是Actor里面进行直接采样。
 https://docs.ray.io/en/master/rllib.html
https://docs.ray.io/en/master/rllib.html
有ACME和RLLib这样的framework,大家搞大规模深度强化学习确实会方便很多,但是要做的更强,还是需要进一步优化。
9 一点小结
从上面的发展来看,大规模深度强化学习的框架基本上是固定了,基于OpenAI Dota 2或SEED RL可以取得目前最佳的CPU-GPU使用效率。当然了,只有框架大规模训练起来也不代表就一定能得到好的效果,毕竟效果好不好还要看采样的数据样本好不好,有没有足够的diverse,所以这就必然引入了self-play,population-based learnin,AI-generating Environments。
提出AI-GAs的Jeff Clune大神加入OpenAI看起来搞的就是AI-generating Environments,再加上大规模深度强化学习,目测很快会给我们展示前所未有的Agent。
当数据足够多足够diverse,AI必将无所不能!
交流合作
请加微信号:yan_kylin_phenix,注明姓名+单位+从业方向+地点,非诚勿扰。
