nltk(3)——语料库
NLTK包含众多一系列的语料库,这些语料库可以通过nltk.package 导入使用。每一个语料库可以通过一个叫做“语料库读取器”的工具读取语料库,例如:nltk.corpus
每一个语料库都包含许多的文件或者是很多的文档。若要获取这些文件的列表,可以通过语料库的fileids()方法。
import nltk.corpus.brown #导入brown语料库
brown.fileids()
每一个语料库都提供了众多的多去数据的方法。例如:对于文档类型的语料库提供读取原始为加工过的文本信息,文本的单词列表,句子列表,段落列表
from nltk.corpus import brown
brown.raw(brown.fileids()[1]) #读取brown中第二个文本的信息
brown.words(brown.fileids()[1]) #读取brown中第二个文本的单词
brown.sents(brown.fileids()[1]) #读取brown中第二个文本的句子
brown.paras(brownfileids()[1]) #读取brown中第二个文本的段落
每一个方法的参数都可以提供多个文档名称或单个,当提供多个文档名称并用逗号隔开时,获取的文档将是单个文档的链接总和。
brown.words(["ca02",brown.fileids()[3]]) #获取文档ca02和文档四的单词,此处注意,当多个文档时,传入的参数是一个list
获取文本单词词频
from nltk.corpus import brown
news_text = brown.words(categories='nes')
fdist = FreqDist(news_text)
modals = ['can','must','could','willl,''might']
for m in modals:
print(m + ":", fdist[m])
FreqDist() 方法获取到每个单词的出现次数
FreqDist({'the': 5580, ',': 5188, '.': 4030, 'of': 2849, 'and': 2146, 'to': 2116, 'a': 1993, 'in': 1893, 'for': 943, 'The': 806, ...})
fdist.keys() #获取所有的键
fdist['the'] #获取对应的键的值
获取条件频率分布ConditionalFreqDist()
import matplotlib.pylab as plb
from nltk.corpus import brown
import nltk
cfd = nltk.ConditionalFreqDis()
genre = brown.categories()
modals = ['can','could','must','might','will']
for g in genre:
for m in brown.words(categories = g):
cfd[g][m] += 1
cfd.tabulate(conditions=genre, sample=modals)

绘制图像:
cfd.plot(conditions = genre, samples = modals, title='ConditionalFreqDist')
ps:tabulate()和plot()方法都有conditions和samples两个参数,第一个参数值指定在绘制时的条件参数,第二个参数是指定样本集,即原始条件集合和样本集的子集。

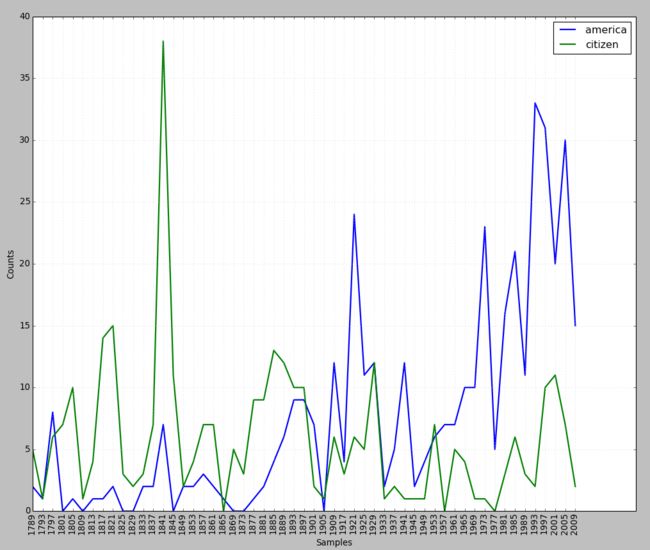
获取就职演讲语料库的文本,然后查看以america或citizen开头的文本在每年的就职演讲中出现的频率
from nltk.corpus import inaugural
cfd = nltk.ConditionalFreqDist()
modals = ['america','citizen']
for f in inaugural.fileids():
for w in inaugural.words(f):
for m in modals:
if w.lower().startswith(m):
cfd[m][f[:4]] += 1
cfd.plot()
特别注意:在ConditionalFreqDist的两个下标中,第一个是条件,第二个是X轴上的信息,即样本元素。
语料库常用方法简记:
fileids() #语料库中的文件
fileids([categories]) #这些分类对应的语料库中的文件
categories() #语料库中的分类
categories([fileids])#这些文件对应的语料库中的分类
raw() #语料库的原始内容
raw(fileids=[f1,f2,f3])#指定文件的原始内容
raw(categories=[c1,c2])#指定分类的原始内容
words() #整个语料库中的词汇
words(fileids=[f1,f2])#指定文件中的词汇
words(categories=[c1,c2]) #指定分类中的词汇
sents() #整个语料库中的句子
sents(fileids=[f1,f2])#指定文件中的句子
sents(categories=[c1,c2])#指定分类中的句子
abspath(fileid) #指定文件在磁盘上的位置
encoding(fileid) #文件的编码(如果知道的话)
open(fileid) #打开指定语料库文件的文件流
root() #到本地安装的语料库根目录的路径
nltk与bigram模型
所谓bigram模型就是假设后一个出现的词或字至于其前面一个词或字有关,与其他间接相关的因素无关。
nltk提供了bigram()方法,可以方便的将一段话,产生两个词相关联的词组。
sent = ["In","the","beginning","God","created","the","heaven","and"]
bgsent = nltk.bigrams(sent)
生成的bgsent为一个generaor,使用next(bgsent)可以循环获得数据
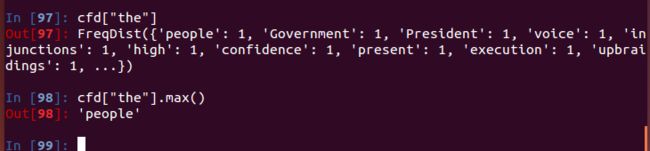
查看inaugural中一篇文章中the后面紧跟的单词最多的是哪个词
from nltk.corpus import inaugural
import nltk
bgrams = nltk.bigrams(inaugural.words(inaugural.fileids()[1]))#获取文章的bigrams值对
cfdist = nltk.ConditionalFreqDist(bgrams) #获取词对的条件频率,条件是前一个词
cfdist["the"].max()#获取条件“the”的频率分布,得到其中出现最多的词
ConditionalFreqDist()常用方法简介
ConditionalFreqDist()方法获取的对象本质上是一个二维数组
cfdist = ConditionalFreqDist(pairs)#从配对链表中创建条件频率分布
cfdist.conditions()#将条件按字母排序
cfdist[condition] #此条件下的频率分布
cfdist[condition][sample]#此条件下给定样本的频率
cfdist.tabulate() #为条件频率分布制表
cfdist.tabulate(conditions='c1',samples='s1')#指定样本和条件限制下制表
cfdist.plot() #为条件频率分布绘图
cfdist.plot(conditions='c1',samples='s1')#指定样本和条件限制下绘图
需要注意的是:FreqDist和ConditionalFreqDist的参数的不同的,前者参数是一个序列Sequence,即无论是list或者是tuple都可以,但是后者必须是一个(condition,sample)类型的元组
例如:fdist = nltk.FreqDist([w.lower() for w in text1 if w.isalpha()])
或 fdist = nltk.FreqDist(w.lower() for w in text1 if w.isalpha())
拼写检查语料库
过滤文本,检查文章中拼写错误的单词
def unusual_words(text):
text_vocab = set(w.lower() for w in text if w.isalpha())
english_vocab = set(w.lower() for w in nltk.corpus.words.words())
unusual = text_vocab.difference(english_vocab)
rentun sorted(unusual)
unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt'))
停用词语料库,就是一些介词如the, to ,of等
从文章中过滤掉这些词
from nltk.corpus import stopwords
len([w for w in text1 if w not in stopwords.words('english')])
名字——性别语料库
查找既存在与男性也存在与女性的名字
from nltk.corpus import names
male = names.words(''male.txt')
female = names.words('female.txt')
[w for w in male if w in female]