MongoDB实战-MongoDB的查询优化器与hint()
查询优化器是MongoDB的一部分,如果存在可用的索引,它会为给定查询选择一个最高效的索引。在为查询选择理性的索引时,优化查询器使用了一套相对简单的规则:
(1) 避免scanAndOrder,如果查询中包含排序,尝试使用索引进行排序;
(2) 通过有效的索引约束来满足所有字段--尝试对查询选择器里的字段使用索引
(3) 如果查询包含范围查找或者排序,那么对于选择的索引,其中最后用到的键需能满足该范围查找或者排序。
如果某个索引能满足以上所有这些条件,那么它会被视为最佳索引并予以使用。要是有多个最佳索引,则任意选择一个。可以遵循这条经验:如果能为查询构建最优索引,查询优化器的工作能更轻松些。
下面有一个查询,它完全满足索引(和查询优化器)。回顾股票数据集,假设要执行如下查询,获取所有大于200的谷歌收盘价:
db.stock.find({stock_symbol:"GOOG",close:{$gt:200}})db.stock.ensureIndex({stock_symbol:1,close:1})
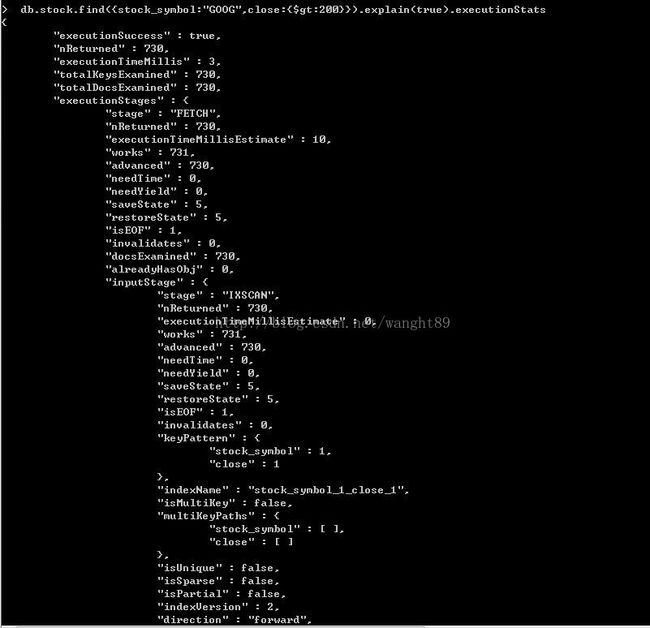
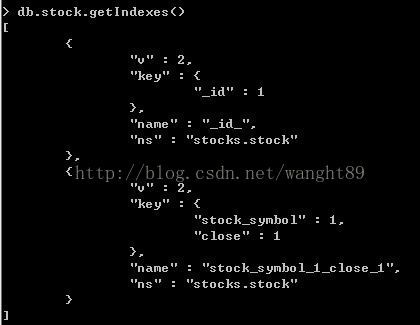
执行状态结果显示,totalDocsExamined:730,nReturned:730。两者值相同。现在来看下没有索引能完美应用于查询之上的情况。通过getIndexes列出索引,通过getIndexKeys()列出索引键。
![]()
如果查询中同时包含了这两个键,但是没有明显的索引可用,这时就该查询优化器出马了。它所使用的试探方式完全是基于totalDocsExamined。换句话说,查询优化器会选择扫描选项最少的索引。首次运行时,查询优化器会为每个可能有效适用于该查询的索引键创建计划,随后并行运行这些计划,totalDocsExamined值最低的计划胜出。优化器会停止那些长时间运行的计划,将胜出的计划保存下来,供后续使用。
你可以查询并运行explain来查看实际的运行过程。首先,删除复合索引{stock_symbol:1,close:1},并在这些键上构建单独的索引;
db.stock.dropIndex("stock_symbol_1_close_1")
db.stock.ensureIndex({stock_symbol:1})
db.stock.ensureIndex({close:1})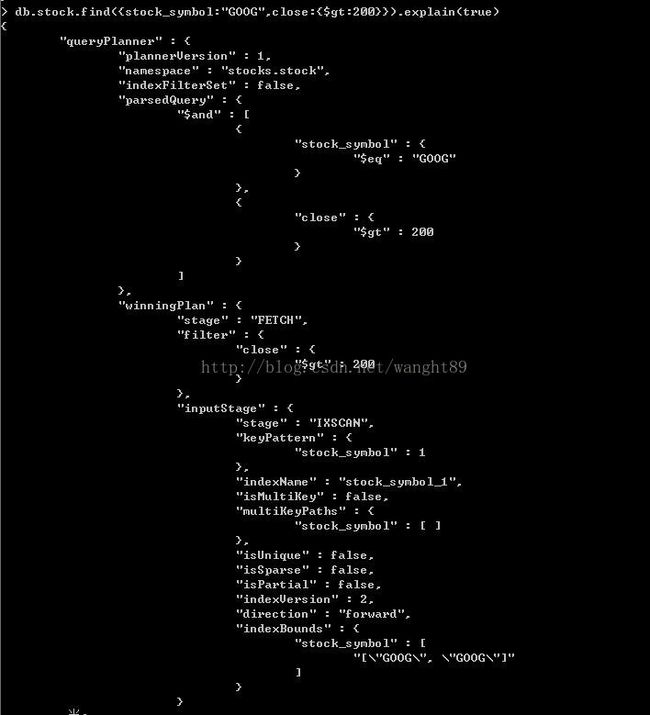

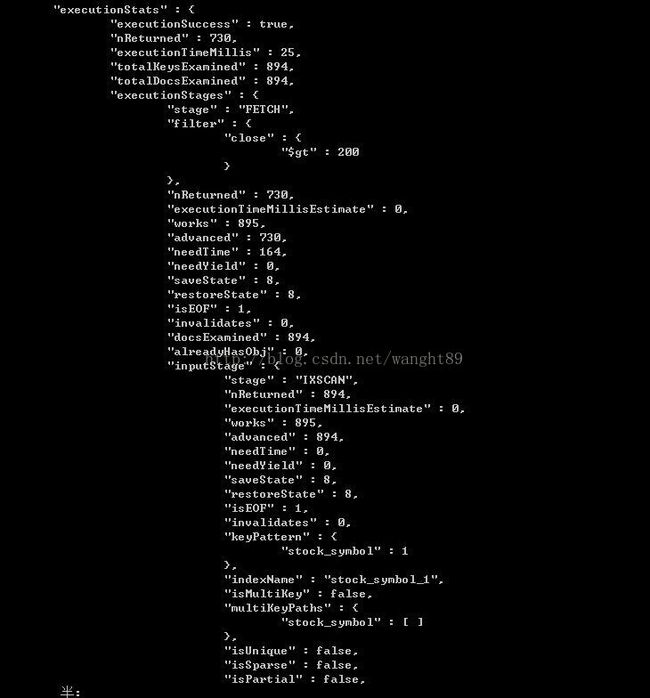
可以看出胜出的执行计划是基于stock_symbol_1的索引。扫描了894个文档。若要查看为什么不选用close_1索引的原因,可以通过hint操作强制查询优化器选择某个特殊的索引。比如强制查询选择器使用close:1的索引,并查看执行结果:
query={stock_symbol:"GOOG",close:{$gt:100}}
db.stock.find(query).hint({close:1}).explain(true).executionStats
发现,若指定使用close作为查询优化器的使用索引,则需扫描28345个文档,与894相差太多。且查询完成时间前者为25ms,后者为192ms,也证实了查询优化器的试探方式,越少的文档扫描的执行计划胜出。
剩下的就是要理解查询优化器是如何缓存它所选择的查询计划。并让其过期的。毕竟,你不希望优化器都并行运行所有计划。在发现一个成功的计划之后,会记录下查询模式(query pattern),totalDocsExamined的值及索引说明。针对刚才的查询,记录的结构如下:
{pattern:{stock_symbol:'equality',close:'bound',index:{stock_symbol:1},totalDocsExamined:894}}对集合执行了100次写操作
在集合上增加或删除索引
虽然使用了缓存的查询计划,但工作量大于预期。此处,“工作量大”的标准是totalDocsExamined超过缓存totalDocsExamined的值的10倍。