目标检测—模型评估(mAP)
我们主要是对VOC数据集格式进行计算mAP,对官方的代码进行了一些改动
改动: 1 增加没有目标的样本的检测,意思是图像没有目标,但是如果模型给了检测结果那么就是误报,虚警
2 对于IOU的改动,我们的目标时小目标,但是预测框可能偏大但是还时包围了物体,所以我们认为时TP但是在计算时IOU<0.5的都是算作FP所以我们把遇到包裹情况时IOU大于0.3为TP

注:上图IOU只有0.3几 红色框时真实框 蓝色时预测的框
我们的检测结果保存为TXT格式 一共有六列 分别为 img_list score left_top_x left_top_y right_bottom_x right_bottom_y 图像文件名 置信得分 四个角点坐标
img_list score left_top_x left_top_y right_bottom_x right_bottom_y
00000 0.99920254945755 322.4844970703125 277.95279693603516 356.8623733520508 307.16697692871094
00001 0.998860239982605 94.22909259796143 139.43439292907715 124.51442527770996 166.12701988220215
00001 0.6958107948303223 100.86927795410156 149.79413604736328 136.12418365478516 181.03306198120117
00002 0.9993857145309448 139.87265396118164 323.6671943664551 170.93098831176758 353.4748191833496
00003 0.9993315935134888 278.95800018310547 92.51019477844238 309.6714401245117 122.34078407287598
00004 0.9993764758110046 92.15834426879883 277.3345718383789 125.65848350524902 306.1568603515625
00005 0.9993232488632202 322.2325019836426 139.55443572998047 356.92456436157227 167.01605224609375
00007 0.983239471912384 366.7515449523926 406.6075439453125 421.9596977233887 447.1839599609375
00007 0.9813326597213745 265.2548027038574 408.44032287597656 302.2177848815918 445.7370376586914
测试集,不包含没有目标的样本。但是我们检测的图像包含了没有目标的样本,所以存放图像的文件夹我们分成了两部分。
存放检测用的图像如下图:

VOC数据集里面的图像:

我们的数据,00000-00005是有目标的而且每张只有一个目标。00006-00007两张图像时没有目标的。我们的检测文件见上面,00007图像时没有目标但是检测出了目标。
下面说一下如何计算AP
第一步计算 累计的recall 和presicion 这里用R和P来表示
P= TP/(TP+FP) TP:预测为正例实际为正例 FP 预测为正实际为负
R = TP/(TP+FN ) FN:预测为负实际为正 我们没有框的都是负样本,但是漏检就是把正样本当成了负样本,所以把模型漏检的算作FN。
按置信得分排序,根据IOU IOU大于0.5为TP否则为FP,例外的时如果预测框完全框住真实框,且IOU大于0.3为TP反之FP,通过TP,FP计算累计TP,FP 及累计P,R
AccFP P R 00002 0.9993857145309448 1 0 1 0 1 0.1666 00004 0.9993764758110046 1 0 2 0 1 0.3333 00003 0.9993315935134888 1 0 3 0 1 0.5 00005 0.9993232488632202 1 0 4 0 1 0.6666 00000 0.99920254945755 0 1 4 1 0.8 0.6666 00001 0.998860239982605 1 0 5 1 0.8333 0.8333 00007 0.983239471912384 0 1 5 2 0.7142 0.8333 00007 0.9813326597213745 0 1 5 3 0.625 0.8333 00001 0.6958107948303223 0 1 5 4 0.5555 0.8333
第一行 P = AccTP/(AccTP+AccFP) = 1/1=1 R= AccTP/ groundTruth =1/6 = 0.1666 TP+FN 就是所有真实标签的数量那么就是6
第二行 P =2/(2+0) = 1 R=2/6= 0.3333
。。。
最后一行 P=5/(5+4)=0.5555 R=5/6=0.8333
最后一行就是我们总的精度和召回率
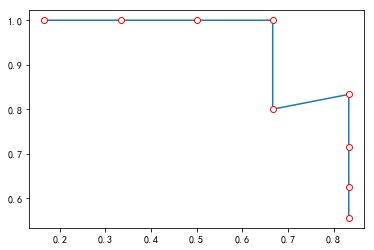
我们看一下PR曲线图横轴时召回率纵轴时精确率
接下来我们看代码怎么计算AP
rec = [0.16666667,0.33333333,0.5,0.66666667,0.66666667,0.83333333,0.83333333,0.83333333,0.83333333]
prec = [1.,1. ,1. ,1., 0.8 ,0.83333333,0.71428571, 0.625,0.55555556]
mrec = np.concatenate(([0.], rec, [1.])) #拼接数组 加上头部0 和尾部 1
mpre = np.concatenate(([0.], prec, [0.])) #拼接数组 加上头部0 和尾部 0
mrec =[0. ,0.16666667, 0.33333333 ,0.5 ,0.66666667, 0.66666667, 0.83333333 ,0.83333333, 0.83333333, 0.83333333, 1. ] #拼接数组 加上头部0 和尾部 1
mpre = [0. ,1., 1. ,1., 1. ,0.8, 0.83333333 ,0.71428571, 0.625, 0.55555556 ,0. ]
# compute precision integration ladder 曲线值(也用了插值)
for i in range(mpre.size - 1, 0, -1): # 倒序 10 9 8 7 .。。。1
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
上面两行代码是为了使得mpre单调递减,此时mpre=mpre: [1. 1. 1. 1. 1. 0.833333330.83333333 0.71428571 0.625 0.55555556 0. ]
i = np.where(mrec[1:] != mrec[:-1])[0]
上面这行代码就是求出recall突变索引 i [0 1 2 3 5 9] 是突变结束的位置 0 0.1666 0.3333 0.5 0.6666 0.8333
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
最终 mrec[i + 1] - mrec[i] = [0.16666667 0.16666667 0.16666667 0.16666667 0.16666667 0.16666667] 对应乘上 [1. 1. 1. 1. 0.83333333 0. ] 最后相加得0.80555
AP=0.80555
其实就是按照突变的位置分成六块 计算这六块的面积然后相加就得到了最后的AP (我们的目标有两个误报的,但是反映在AP上毫无变化,正好是因为计算时跳过了反应误报的那个精度,但是从精度上还是可以看出来的)
下面是具体代码:
Created on Thu Aug 30 10:43:27 2018
@author: lixiunan
“”"
from future import print_function
import numpy as np
import os
try:
import cPickle as pickle
except ImportError:
import pickle
def parse_voc_rec(filename):
“”"
parse pascal voc record into a dictionary
:param filename: xml file path
:return: list of dict
“”"
import xml.etree.ElementTree as ET
tree = ET.parse(filename)
objects = []
for obj in tree.findall(‘object’):
obj_dict = dict()
obj_dict[‘name’] = obj.find(‘name’).text
obj_dict[‘difficult’] = int(obj.find(‘difficult’).text)
bbox = obj.find(‘bndbox’)
obj_dict[‘bbox’] = [int(bbox.find(‘xmin’).text),
int(bbox.find(‘ymin’).text),
int(bbox.find(‘xmax’).text),
int(bbox.find(‘ymax’).text)]
objects.append(obj_dict)
return objects
def voc_ap(rec, prec, use_07_metric=False):
“”"
average precision calculations
[precision integrated to recall]
:param rec: recall
:param prec: precision
:param use_07_metric: 2007 metric is 11-recall-point based AP
:return: average precision
“”"
if use_07_metric:
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap += p / 11.
else:
# append sentinel values at both ends
mrec = np.concatenate(([0.], rec, [1.])) #拼接数组 加上头部0 和尾部 1
mpre = np.concatenate(([0.], prec, [0.])) #拼接数组 加上头部0 和尾部 0
# print(‘mpre:’,mpre)
# print(‘mrec’,mrec)
# compute precision integration ladder 曲线值(也用了插值)
for i in range(mpre.size - 1, 0, -1): # 倒序 10 9 8 7 .。。。1
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
#print('mpre:',mpre)
#print('mrec',mrec)
# look for recall value changes 找到变化的点或者说阶梯开始点索引
i = np.where(mrec[1:] != mrec[:-1])[0]
#print('i',i)
# sum (\delta recall) * prec
#
#print('tu',mpre[i+1])
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
def voc_eval(detpath, annopath, imageset_file, classname, cache_dir, ovthresh=0.5, use_07_metric=False):
“”"
pascal voc evaluation
:param detpath: detection results detpath.format(classname)
:param annopath: annotations annopath.format(classname)
:param imageset_file: text file containing list of images
:param classname: category name
:param cache_dir: caching annotations
:param ovthresh: overlap threshold
:param use_07_metric: whether to use voc07’s 11 point ap computation
:return: rec, prec, ap
“”"
if not os.path.isdir(cache_dir):
os.mkdir(cache_dir)
cache_file = os.path.join(cache_dir, 'annotations.pkl')
with open(imageset_file, 'r') as f:
lines = f.readlines()
image_filenames = [x.strip() for x in lines]
#print(image_filenames)
# load annotations from cache
if not os.path.isfile(cache_file):
recs = {}
for ind, image_filename in enumerate(image_filenames):
print('ind:',ind)
print('image_filename',image_filename)
recs[image_filename] = parse_voc_rec(annopath + '\\' + str(image_filename) +'.xml')
if ind % 100 == 0:
print('reading annotations for {:d}/{:d}'.format(ind + 1, len(image_filenames)))
print('saving annotations cache to {:s}'.format(cache_file))
with open(cache_file, 'wb') as f:
pickle.dump(recs, f)
else:
with open(cache_file, 'rb') as f:
recs = pickle.load(f)
# extract objects in :param classname:
class_recs = {}
npos = 0
for image_filename in image_filenames:
objects = [obj for obj in recs[image_filename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in objects])
difficult = np.array([x['difficult'] for x in objects]).astype(np.bool)
det = [False] * len(objects) # stand for detected
npos = npos + sum(~difficult)
class_recs[image_filename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read detections
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines[1:]] # 跳过第一行 表头
image_ids = [x[0] for x in splitlines]
confidence = np.array([float(x[1]) for x in splitlines])
bbox = np.array([[float(z) for z in x[2:]] for x in splitlines])
# sort by confidence
sorted_inds = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
bbox = bbox[sorted_inds, :]
image_ids = [image_ids[x] for x in sorted_inds]
#print('image_ids',image_ids)
# go down detections and mark true positives and false positives
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
fix_iou = False
#FP 计数 如果有图像本身没目标但是预测有目标
count_FP = 0
#==============
for d in range(nd):
# 如果检测文件里面的图像未出现在 VOC检测文件里那么这个就是 误报,虚景
if not image_ids[d] in class_recs.keys() :
fp[d] = 1
print('没有目标,但预测有目标',image_ids[d])
continue
r = class_recs[image_ids[d]]
bb = bbox[d, :].astype(float)
ovmax = -np.inf
bbgt = r['bbox'].astype(float)
if bbgt.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(bbgt[:, 0], bb[0])
iymin = np.maximum(bbgt[:, 1], bb[1])
ixmax = np.minimum(bbgt[:, 2], bb[2])
iymax = np.minimum(bbgt[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
#print('inter:',inters)
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(bbgt[:, 2] - bbgt[:, 0] + 1.) *
(bbgt[:, 3] - bbgt[:, 1] + 1.) - inters)
#
#对于IOU一些修正,如果出现一个框完全包裹另一个框 这里仅设置了预测框大于真实框
#
#fix_iou = (bb[0] > bbgt[0] and bb[1] >bbgt[1] and bb[2] > bbgt[2] and bb[3] > bbgt[3]) or (bb[0] < bbgt[0] and bb[1] <bbgt[1] and bb[2] < bbgt[2] and bb[3]<bbgt[3])
# print('bbgt',bbgt[:,2])
fix_iou = bb[0]-bbgt[:,0] <0 and bb[1]-bbgt[:,1] < 0 and bb[2]-bbgt[:,2] > 0 and bb[3]-bbgt[:,3] >0
# fix_iou = False
if np.min(coord_sub ) > 0 or np.max(coord_sub) < 0 :
fix_iou = True
else:
fix_iou = False
#
#对于IOU一些修正,如果出现一个框完全包裹另一个框
#
overlaps = inters / uni
#print('IOU',overlaps)
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if (ovmax > ovthresh) or (fix_iou and ovmax > 0.3) :
if not r['difficult'][jmax]:
if not r['det'][jmax]:
tp[d] = 1.
r['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
#print('tp:',tp)
# compute precision recall
fp = np.cumsum(fp) #计算累计fp
# 如果测试样本没有目标却标注成了目标,那么这些都会算成 误报,也就是FP
print(‘FP:’,fp)
tp = np.cumsum(tp)
#print('TP:',tp)
rec = tp / float(npos)
#print('rec:',rec)
print('GT数量',npos)
# avoid division by zero in case first detection matches a difficult ground ruth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
detpath= r’F:\function_test\评估没有目标的样本\ship_det_val.txt’
annopath=r’F:\function_test\评估没有目标的样本\VOCdevkit\VOC2007\Annotations’
imageset_file=r’F:\function_test\评估没有目标的样本\VOCdevkit\VOC2007\ImageSets\Main\ship_val.txt’
classname=‘ship’
cache_dir = r’F:\function_test\评估没有目标的样本\temp’ # 每次修改数据集都要清空这个文件夹
rec, prec, ap = voc_eval(detpath, annopath, imageset_file, classname,cache_dir,ovthresh=0.5, use_07_metric=False)
print(‘AP’,ap)
print(’\n’)
print(‘recall’,rec[-1],‘prec’,prec[-1])
标签: 目标检测, mAP, python, 小目标
好文要顶 关注我 收藏该文



初冬的骄阳
关注 - 0
粉丝 - 0
+加关注
