Recaption on CNN Architecture
Although Serena is very beautiful, Justin is a better lecturer. Love him.
Recurrent Neural Network
Meant to process sequencial data, reuse hidden state to retain the knowledge of previous fed inputs. Can be use in "one to many", "many to one" and "many to many" scenarios by using different input and output stradegies. Formally, we maintain an $h_t$ for tth iteration, and generate next hidden state by applying $h_{t+1}=f_{W}(h_t, x_{t+1})$ where we reuse the parameters $W$ and get updated through flowing gradients, and get our output from hidden state. A vanilla RNN looks like this: $h_t=\tanh(W_{hh}h_{t-1} + W_{xh}x_t), y_t = W_{hy}h_t$. During training, we backprop the loss through $y_{t}$ and update $W$, for long sequence, this will lead to heavy memory usage (for maintaining the hidden state, as I have experienced), so we chunk the input and update after each chunk.
A very insightful and concrete discussion comes from Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks And he provided a sheet of practical RNN code on gist (a non-exsitent site in China :-( ), it consists only 112 lines of Python.
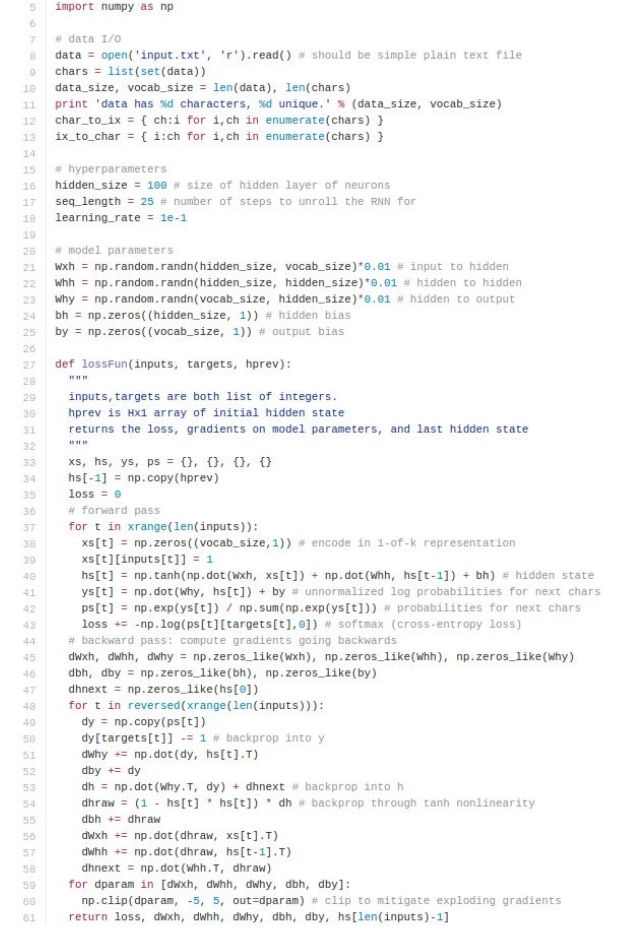

Optimization: allows for multiple layers, uses an LSTM instead of a vanilla RNN, has more supporting code for model checkpointing, and is of course much more efficient since it uses mini-batches and can run on a GPU.
Image Captioning
Andrej's dissertation paper covers the interesting part of combining image and language, check it out!
The structure here is to remove the last output layers of a convnet (say, the FC-1000 and softmax of a VGG16), and use the result as the hidden state of a RNN by a $W_{ih}$, start with
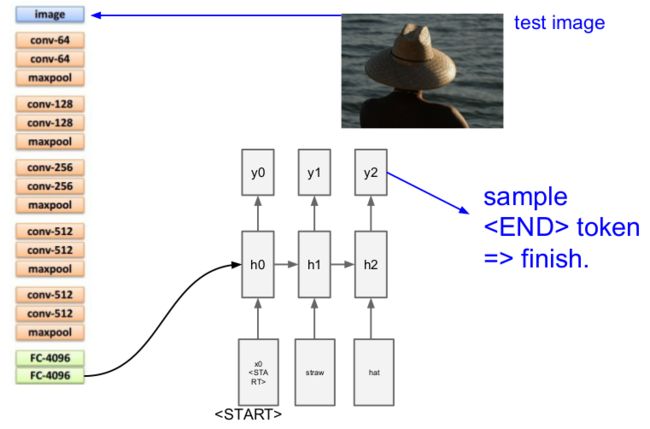
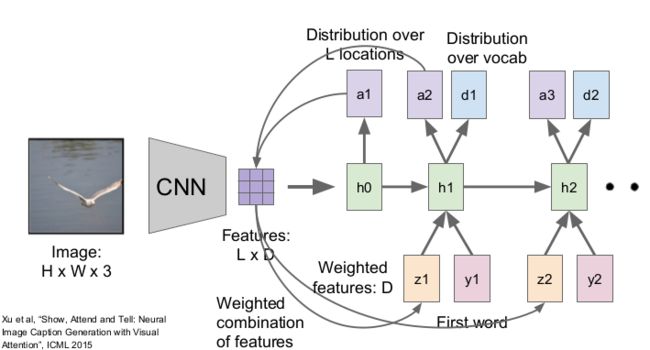
Image Captioning with Attention
This is a slightly advanced model. First, the CNN produces features instead of sumarization vector (as previously do), and the RNN are allowed to steer its attention on the features (makes them as weighted input), Second, the RNN produces 2 output at each time step, one for attention and one for words.
Visual Question Answering
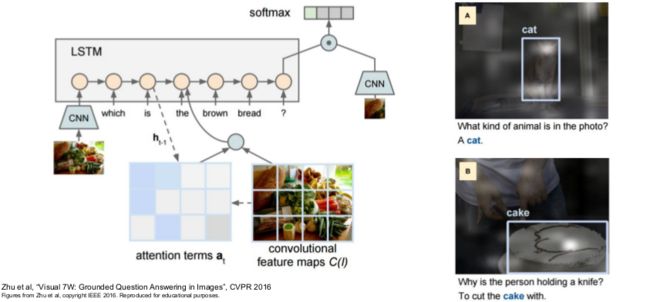
RNN allows you to solve some very fancy problems, it is cool!
Multilayer RNN, LSTM and GRU
Deeper models are better, so, stacking layers spacially to get multilayer RNN.
Vanilla RNN Gradient Flow. Leads to Exploding gradients (Solved by Gradient clipping, if L2 norm of gradient to large, .e.g bigger than some threshold, then clip it to that threshold) or Vanishing gradients (Solved by fancier architecture).
LSTM [Hochreiter and Schmidhuber, 1997]
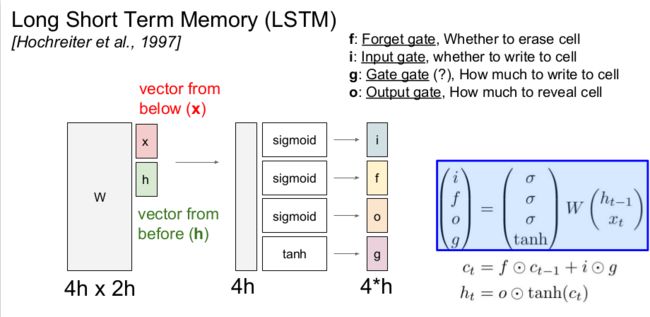
op in the lecture means element wise multiplication. Note the different non-linearity used and the size of matrix above.
Gradient flow. Uninterrupted, because of c.
玄学结构。。
GRU [Learning phrase representations using rnn encoder-decoder for statistical machine translation, Cho et al. 2014]
[LSTM: A Search Space Odyssey, Greff et al., 2015]
[An Empirical Exploration of Recurrent Network Architectures, Jozefowicz et al., 2015]
Key Idea: Manage gradient flow.