1. 进程的基本概念
从抽象的意义来说,进程是指一个正在运行的程序的实例,而线程是一个CPU指令执行流的最小单位。进程是操作系统资源分配的最小单位,线程是操作系统中调度的最小单位。从实现的角度上讲,XV6系统中只实现了进程, 并没有提供对线程的额外支持,一个用户进程永远只会有一个用户可见的执行流。
2. 进程管理的数据结构
根据[1],进程管理的数据结构被叫做进程控制块(Process Control Block, PCB)。一个进程的PCB必须存储以下两类信息:
- 操作系统管理运行的进程所需要信息,比如优先级、进程ID、进程上下文等
- 一个应用程序运行所需要的全部环境,比如虚拟内存的信息、打开的文件和IO设备的信息等。
XV6中进程相关的数据结构
在XV6中,与进程有关的数据结构如下
// Per-process state
struct proc {
uint sz; // Size of process memory (bytes)
pde_t* pgdir; // Page table
char *kstack; // Bottom of kernel stack for this process
enum procstate state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
struct trapframe *tf; // Trap frame for current syscall
struct context *context; // swtch() here to run process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};与前述的两类信息的对应关系如下
操作系统管理进程有关的信息:内核栈
kstack,进程的状态state,进程的pid,进程的父进程parent,进程的中断帧tf,进程的上下文context,与sleep和kill有关的chan和killed变量。进程本身运行所需要的全部环境:虚拟内存信息
sz和pgdir,打开的文件ofile和当前目录cwd。
额外地,proc中还有一条用于调试的进程名字name。
在操作系统中,所有的进程信息struct proc都存储在ptable中,ptable的定义如下
struct {
struct spinlock lock;
struct proc proc[NPROC];
} ptable;除了互斥锁lock之外,一个值得注意的一点是XV6系统中允许同时存在的进程数量是有上限的。在这里NPROC为64,所以XV6最多只允许同时存在64个进程。
在proc.c中,userinit()用于创建第一个用户进程,allocproc()则被用于在ptable中寻找空位并在空位上创建一个新的进程。当操作系统初始化时,通过userinit()调用allocproc创建第一个进程init。绝大多数进程相关信息都会在这里初始化。由于XV6系统只允许中断返回一种从内核态进入用户态的方式,因此allocproc()会创建中断调用的栈结构,而userinit会设置其中的值,仿佛是从一次真正的中断里返回进程一样。最后,在mpmain()中,系统调用schedule()函数,开始用户进程的调度。在init进程被调度启动后,会创建shell进程,用于和用户交互。
Linux中进程相关的数据结构
Linux系统的实现中并不刻意区分进程和线程,而是将其一概存储在被称作task_struct的数据结构中。当两个task_struct共享同一个虚拟地址空间时,它们就是同一个进程的两个线程。与Linux进程有关的数据结构定义大多数都在/include/linux/sched.h中。task_struct数据结构相当复杂,在32位机器上一条能占据1.7KiB的空间。task_struct中主要包含的数据结构有管理处理器底层信息的thread_struct、管理虚拟内存的mm_struct、管理文件描述符的file_struct、管理信号的signal_struct等等。Linux中的进程与XV6一样都有独立的内核栈,内核模式下的代码是在内核栈中运行的。
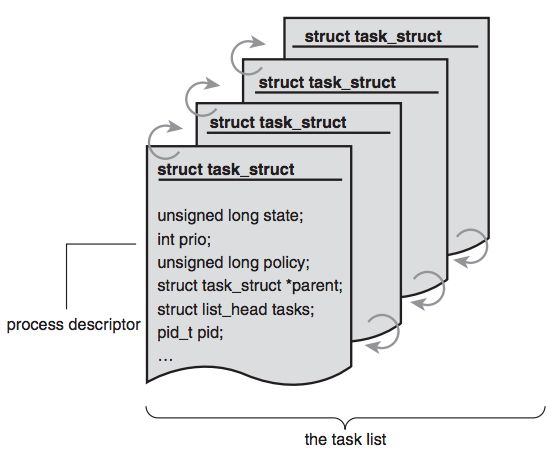
操作系统维护多个task_struct队列来实现不同的功能。所有的队列都是用双向链表实现的。有一个队列存放了所有的进程;另一个队列存放了所有正在运行的进程(kernel/sched.c中的struct runqueue );此外,对于每一个会导致进程挂起的等待事件,都有一个队列存放因为等待此事件而挂起的进程(include/linux/wait.h中的wait_queue_t)。
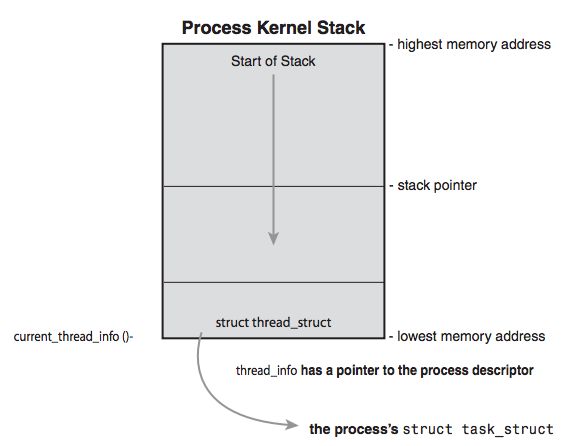
Linux会将task_struct数据结构分配到这个进程的内核栈的顶部,将thread_info数据结构分配到这个进程的内核栈的底部。thread_info的名称有些误导,它存储的其实是一个task中更加底层和更加体系结构相关的属性。进程数据结构的分配方法被称为Slab Allocator,通过精心优化的虚拟内存机制来提升进程管理的效率、实现对象重用。
struct thread_info {
struct task_struct *task;
struct exec_domain *exec_domain;
__u32 flags;
__u32 status;
__u32 cpu;
int preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
void *sysenter_return;
int uaccess_err;
};Windows中进程相关的数据结构
在Windows NT以后的Windows系统中,进程用EPROCESS对象表示,线程用ETHREAD对象表示。在一个EPROCESS对象中,包含了进程的资源相关信息,比如句柄表、虚拟内存、安全、调试、异常、创建信息、I/O转移统计以及进程计时等。每个EPROCESS对象都包含一个指向ETHREAD结构体的链表。值得一提的是Windows系统中EPROCESS和ETHREAD的设计都是分层的,KPROCESS和KTHREAD成员对象专门用来处理体系结构有关的细节,而Process Environment Block和Thead Environment Block对象则暴露给应用程序来访问。
3. 进程的状态
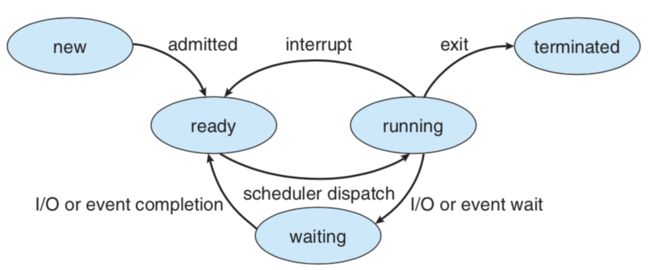
在大多数教科书使用的标准五状态进程模型中,进程分为New、Ready、Running、Waiting和Terminated五个状态,状态转换图如图所示(图出自Operating System Concepts, 7th Edition)
除去标记进程块未被使用的UNUSED状态,XV6操作系统中的状态与上述的五状态模型完全对应。在XV6中这五个状态的定义为
enum procstate { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };XV6实现中源代码中具体的转换关系如下
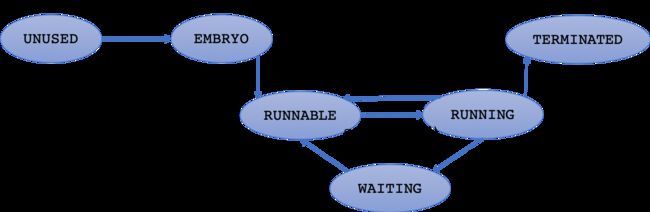
这个转换关系图中,标识出了在XV6系统中发生状态转换所需要的函数或者事件。
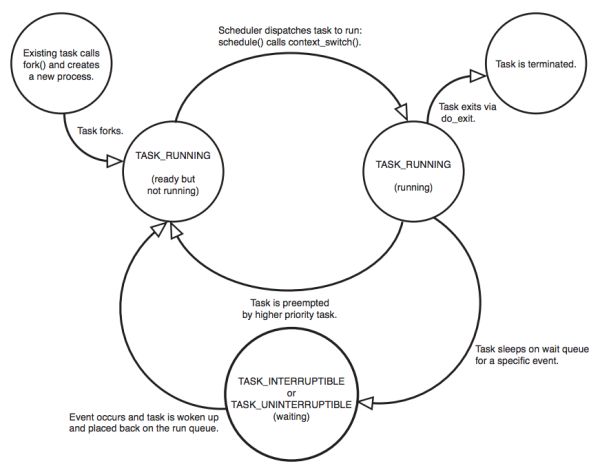
Linux中的进程转换图与Xv6大致相同,但是有如下区别:
- Linux中的Waiting有两个状态,分别是Interruptible Waiting和Uninterruptible Waiting。
- Linux中额外有两个调试用状态
TASK_TRACED和TASK_STOPPED。
关于Windows的进程状态,网上并没有关于实现细节的特别详细的解释。一份关于Windows进程的文档[6]使用了如下的进程转换图,但并没有显式地说明其与Windows进程实现之间的关系。
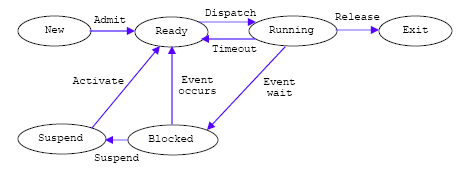
从中可以看出,Windows进程可能额外多出了Suspend状态,用于以下情况的一种:
- 当内存不足使得此进程被移入硬盘时
- 当操作系统决定挂起某个后台进程时
- 当用户出于调试或者其他原因手动挂起了某个进程,或者一个进程的父进程使用系统调用挂起一个进程时
- 对于定时启动的系统,在指定的运行时间以外会被挂起
我认为操作系统设计这些状态,是出于在有限的计算机系统资源上,对管理和调度多个进程的需求。如果一个CPU核同一时间只会有一个进程运行,那就完全不需要设置进程的状态。但是一个实用的现代操作系统必须支持大量进程共享一个CPU,也必须支持进程的不断创建与终止,从而实现资源利用效率的最大化和系统功能的多样化。因此,操作系统选取了现在的五状态进程设计,并且出于不同系统的需求不同,也会有更加细化的设计。
4. 进程的调度算法
Xv6系统中的进程可以使用fork()系统调用创建新进程。为了创建一个进程,操作系统必须为这个进程分配相应的资源,包括内存、CPU时间、文件等,与此同时,操作系统必须对此进程做出相应的管理,包括设置它的进程ID、调度优先级、虚拟内存结构、运行资源限制等等。为了能够维持多个进程在一个CPU上运行,必须对此做出相应的调度。调度算法有很多种,由简到难如下
- First Come, First Served. 这个调度算法的思想是让操作系统维护一个可以运行的进程的等待队列,让先进入等待队列的进程先运行。这个调度算法的优势在于实现简单,只要是能实现链表的系统就能实现这个调度算法。但是这个算法的问题在于,算法在很多量度下都是次优的,其优劣的程度完全取决于进程进入队列的先后顺序。
- Shortest Task First. 这个调度算法的思想是让期望运行时间最短的进程先执行。可以从理论上证明,给定一组执行时间已知的进程,这个调度算法能让所有进程的等待时间之和最小。但是,预估一个进程的执行时间是极为困难的,妨碍了这个算法的实践有效性。此外,这个算法还存在饥饿(Starvation)的问题,也就是大量短时进程的不断进入会使得一个长时进程无法执行。
- Round-Robin. 这个算法的思想在于对所有运行的进程分配一个时间片,让所有进程轮流执行。这个调度算法虽然效率低下,但是公平性是最好的,并且不会存在饥饿的问题。
- Priority Based Multilevel Queue. 这个算法的思想是对不同进程分配不同的优先级,每个优先级会有一个进程队列,优先级高的先执行,同一优先级内使用某种前述调度算法分配。为了解决低优先级进程饥饿的问题,常常会采用某种动态优先级调整机制。
一个现代操作系统所使用的调度算法通常是Priority Based Multilevel Queue的一种变体。具体地说,根据操作系统的具体需求,将不同类别的进程赋予不同的优先级。比如,Windows系统中,用户当前使用的窗体进程具有非常高的优先级。对于每一个优先级内的进程都会维护一个独自的队列,每个优先级可以使用不同的调度算法。高优先级的前台进程可以使用Round-Robin,后台进程可以使用First Come First Served。如果一个进程很久没有得到执行,那么可以提升它的优先级,从低优先级队列进入高优先级队列,从而避免饥饿的问题。
一般而言,出于CPU资源的限制和操作系统内核空间的内存限制,操作系统会指定允许同时存在的最大进程数。在Xv6系统中,最多同时存在64个进程。操作系统会维护一个大小为64的struct proc数组,并在其中分配新的进程。
进程的上下文包含了这个进程执行时所需要的全部信息,主要是寄存器的值和运行时栈。在Xv6系统中,执行进程的上下文切换就意味着要保存原进程的调用保存寄存器 %ebp %ebx %esi %ebp,栈指针%esp和程序指针eip,并载入新的进程的上述寄存器。特别地,Xv6中的进程切换只会切换到内核调度器进程,并通过内核调度器切换到新的进程。
关于进程调度的具体细节,官方文档具有精彩的描述,在此不再赘述。
多进程和多CPU之间的关系在于,在操作系统面前,每个进程都好似占用了一个独立的虚拟CPU,但事实上操作系统会将多个进程分配在一个或多个CPU上运行,进程的数量与CPU的数量之间并没有直接的关系。
5. 内核态进程与用户态进程
内核态进程,顾名思义,是在操作系统内核态下执行的进程。在内核态下运行的进程一般用于完成操作系统最底层,最为核心,无法在用户态下完成的功能。比如,调度器进程是Xv6中的一个内核态进程,因为在用户态下是无法进行进程调度的。相比较而言,用户态进程用于完成的功能可以多种多样,并且其功能只依赖于操作系统提供的系统调用,不需要深入操作内核的数据结构。比如init进程和shell进程就是xv6中的用户态进程。
6. 进程的内存布局
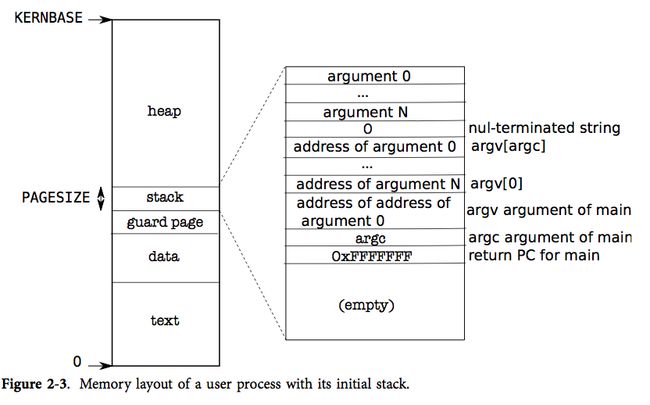
Xv6进程在虚拟内存中的布局如上图。当然,其中的每一页在物理内存中大概率并不是这样排列的,但是虚拟内存系统为每个进程提供了统一的内存抽象。进程的栈用于存放运行时数据和运行时轨迹,包含了函数调用的嵌套,函数调用的参数和临时变量的存储等。栈通常较小,不会在运行时增长,不适合存储大量数据。相比较而言,堆提供了一个存放全局变量和动态增长的数据的机制。堆的大小通常可以动态增长,并且一般用于存储较大的数据和程序执行过程中始终会被访问的全局变量。
7. fork、wait、exit系统调用的实现。
fork()函数
// Create a new process copying p as the parent.
// Sets up stack to return as if from system call.
// Caller must set state of returned proc to RUNNABLE.
int
fork(void)
{
int i, pid;
struct proc *np;
struct proc *curproc = myproc();
// Allocate process.
if((np = allocproc()) == 0){
return -1;
}
// Copy process state from proc.
if((np->pgdir = copyuvm(curproc->pgdir, curproc->sz)) == 0){
kfree(np->kstack);
np->kstack = 0;
np->state = UNUSED;
return -1;
}
np->sz = curproc->sz;
np->parent = curproc;
*np->tf = *curproc->tf;
// Clear %eax so that fork returns 0 in the child.
np->tf->eax = 0;
for(i = 0; i < NOFILE; i++)
if(curproc->ofile[i])
np->ofile[i] = filedup(curproc->ofile[i]);
np->cwd = idup(curproc->cwd);
safestrcpy(np->name, curproc->name, sizeof(curproc->name));
pid = np->pid;
acquire(&ptable.lock);
np->state = RUNNABLE;
release(&ptable.lock);
return pid;
}fork()函数的代码如上。fork()函数首先调用allocproc()函数获得并初始化一个进程控制块struct proc(12-14行)。此外,在allocproc()函数中还会对进程的内核栈进行初始化,在内核栈里设置一个Trap Frame,把Trap Frame的上下文部分都置为0。然后,fork()函数使用copyuvm()函数复制原进程的虚拟内存结构(17-24行)。为了能让子进程返回时处在和父进程一模一样的状态,Trap Frame也会被拷贝(25行,需要注意这里的运算符优先级)。为了让子进程系统调用的返回值为0,子进程的eax寄存器会被置为0(28行)。然后,父进程打开的文件描述符会被全部拷贝给子进程(30-32行),还有父进程所处于的目录(33行)。这些操作都会增加文件描述符和目录的被引用数。最后,fork()函数拷贝了父进程的名字,设置了子进程的状态为RUNNABLE,然后返回子进程pid给父进程。子进程被创建后,在某个时刻调度子进程运行时,fork()函数会第二次返回给子进程,此时返回值为0。
wait()函数
// Wait for a child process to exit and return its pid.
// Return -1 if this process has no children.
int
wait(void)
{
struct proc *p;
int havekids, pid;
struct proc *curproc = myproc();
acquire(&ptable.lock);
for(;;){
// Scan through table looking for exited children.
havekids = 0;
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->parent != curproc)
continue;
havekids = 1;
if(p->state == ZOMBIE){
// Found one.
pid = p->pid;
kfree(p->kstack);
p->kstack = 0;
freevm(p->pgdir);
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->killed = 0;
p->state = UNUSED;
release(&ptable.lock);
return pid;
}
}
// No point waiting if we don't have any children.
if(!havekids || curproc->killed){
release(&ptable.lock);
return -1;
}
// Wait for children to exit. (See wakeup1 call in proc_exit.)
sleep(curproc, &ptable.lock); //DOC: wait-sleep
}
}wait()函数的代码如上。wait()函数首先必须要获得ptable的锁(10行),因为它有可能会对ptable做出修改。然后它会遍历ptable,从中寻找自己的子进程(14-32行)。如果发现僵尸子进程,就把僵尸子进程回收,具体地说要回收它的虚拟内存,内核栈,并设置状态为UNUSED(18-30行),有趣的是,在这里wait()函数根本没有回收这个子进程打开的文件描述符,因为在exit()函数内这个进程打开的文件描述符已经全部被关闭了,而且只有exit()之后的进程才可能是ZOMBIE状态。对于没有子进程的情况,wait()会直接返回,否则他会调用sleep(),并传入ptable的锁作为参数。之所以要在sleep函数中传入ptable锁,是为了避免在wait()把进程设置为SLEEP状态之前,子进程就已经成为僵死进程并在exit()函数中调用了wakeup(),这会使得父进程接收不到wakeup从而进入死锁状态。
exit()函数
// Exit the current process. Does not return.
// An exited process remains in the zombie state
// until its parent calls wait() to find out it exited.
void
exit(void)
{
struct proc *curproc = myproc();
struct proc *p;
int fd;
if(curproc == initproc)
panic("init exiting");
// Close all open files.
for(fd = 0; fd < NOFILE; fd++){
if(curproc->ofile[fd]){
fileclose(curproc->ofile[fd]);
curproc->ofile[fd] = 0;
}
}
begin_op();
iput(curproc->cwd);
end_op();
curproc->cwd = 0;
acquire(&ptable.lock);
// Parent might be sleeping in wait().
wakeup1(curproc->parent);
// Pass abandoned children to init.
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->parent == curproc){
p->parent = initproc;
if(p->state == ZOMBIE)
wakeup1(initproc);
}
}
// Jump into the scheduler, never to return.
curproc->state = ZOMBIE;
sched();
panic("zombie exit");
}exit()函数首先关闭这个进程打开的所有文件描述符(15-20行),然后除去自己对所处的文件目录的引用(22-25行),对文件管理相关数据结构的访问必须要获得和释放相关的锁(begin_op()和end_op())。清除这些引用可以允许文件系统管理当前的缓存。如果这个进程的父进程正在等待子进程结束,那么这个进程必须唤醒父进程(30行),只有这样父进程才能够在某个时刻回收僵尸子进程。如果这个进程有子进程的话,就把这个进程的子进程都传给init进程,并由init进程来负责回收僵尸子进程(33-39行)。最后,这个进程的状态会被设置为ZOMBIE,调度器调度其他进程运行(42-44行)。
参考资料
Operating System Concepts, 7th Edition
Computer Systems: a Programmer's Perspective, 3rd Edition
Process in Linux, https://www.cs.columbia.edu/~junfeng/10sp-w4118/lectures/l07-proc-linux.pdf
10 Things Every Linux Programmer Should Know, http://www.mulix.org/lectures/kernel_workshop_mar_2004/things.pdf
Introduction to Linux Kernel, Chapter 3 Process Management, https://notes.shichao.io/lkd/ch3/#chapter-3-process-management
A Complete Introduction to Windows Processes, Threads and Related Resources, https://www.tenouk.com/ModuleT.html
Windows进程数据结构及创建流程,https://blog.csdn.net/cuit/article/details/9200097