我们可以通过事物的响应时间作为基础来分析:
响应时间=网络的延迟时间+应用的延迟时间+数据库的延迟时间
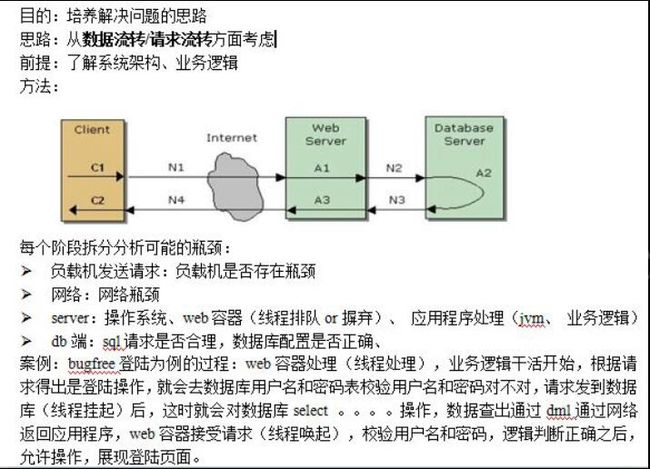
数据流转详细过程:
1、从客户端(负载机)发起请求,通过网络传输到Web应用服务器。
2、Web应用服务器收到请求后,不会马上处理,要找到空闲的进程/线程,再进行应用程序的处理(比如说一些数据库的DML操作)
3、DML操作请求通过网络传输到数据库,数据库拿到SQL语句后进行语法解析、域解析,生成SQL的执行计划,根据SQL的执行计划去数据库执行这条SQL语句。如果数据在内存里面,直接从内存里面把结果集通过网络返回给应用服务器,如果这条数据不在内存里面,需要到硬盘/磁盘去找到这条数据,然后放到内存中再返回给应用服务器。
4、应用服务器拿到返回结果后,不会马上处理,需要唤起空闲进程/线程后,再进行下一步的业务逻辑处理。
5、如此循环反复,执行完成之后,再把返回结果集通过网络返回给客户端(负载机)。
整个过程包括7个阶段:
客户端→网络→中间件→应用程序→数据库→应用程序→客户端
分析步骤:
1、客户端(负载机)
压力的发起点
如果压测过程中发现应用程序的TPS、压力、并发上不去,第一个应该检查负载机,因为它是压力的发起点。
负载机的性能瓶颈:网卡(上传下载)、CPU高、内存高
2、网络
网络错误率/丢包率
在Linux下用sar命令查看
更换网卡、增加带宽
3、Web服务器
硬件:CPU、内存、磁盘
什么造成了CPU使用高
什么造成了内存使用高
什么造成了磁盘使用繁忙
4、数据库服务器
硬件:CPU、内存、磁盘
什么造成了CPU使用高
什么造成了内存使用高
什么造成了磁盘使用繁忙
5、中间件
线程池/进程池排队,线程池配置不合理会占用过多的内存资源
是否需要配置长链接keepalive,长连接的大小配置是否合适,长连接的超时时间配置是否合理
gzip压缩是否开启(文件、图片)
6、数据库
SQL使用是否合理
SQL执行效率
数据库连接池是否繁忙
7、应用程序
JVM内存使用情况
GC使用是否合理,是否停顿时间过长
业务逻辑
算法
分析思路总结:
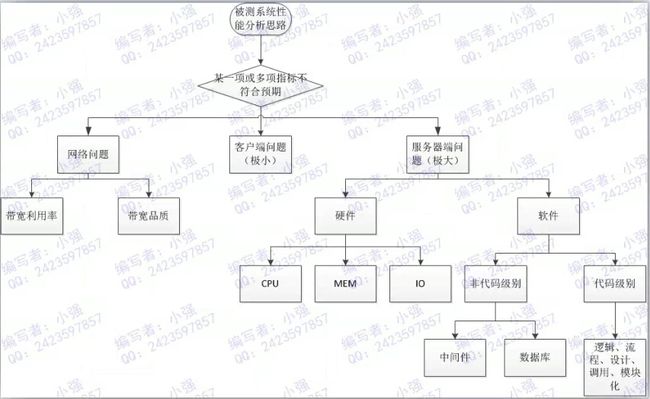
CPU、内存、硬盘之间的关系
1、CPU
就像人的大脑,主要负责相关事情的逻辑判断、运算以及实际处理机制
查询指令:cat /proc/cpuinfo
2、内存
大脑中的记忆区块,将眼睛、皮肤等收集到的信息纪录起来的地方,以供CPU进行判断
CPU进行逻辑判断、运算的数据来源于内存
查询指令:cat /proc/meminfo
3、硬盘
大脑中的记忆区块,将重要的数据记录起来,以便未来再次使用这些数据
数据的最终的存储区域
查询指令:fdisk -l
总结:
CPU先从内存中拿数据进行处理、校验、判断,处理完之后把数据返回给内存,需要存储的东西由内存放到硬盘里面去进行处理。CPU不会直接操作硬盘里面的数据,它操作的是内存。内存是中间介质,内存足够大,内存中存放的数据就多,CPU能够直接处理的数据就更多,这样处理速度就快。
我们用工人、车间、仓库来类比CPU、内存、磁盘。工人相当于CPU,在车间进行材料加工,车间相当于内存,车间的材料不够就要去仓库里面去取,仓库就相当于磁盘。只有车间足够大,工人才可以一直在车间进行加工,不需要取仓库取源材料,这样效率更高,速度更快。

内存与硬盘以及虚拟内存的关系
虚拟内存
从磁盘上虚拟出来的一段地址空间当内存用,它的速度比物理内存要慢。
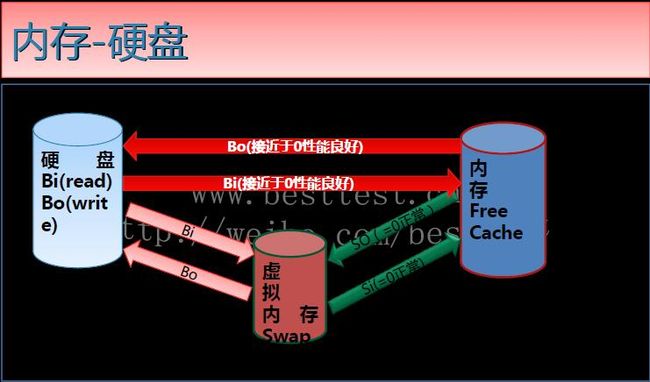
操作系统分析方向
CPU→内存→磁盘
