一、prometheus基本架构
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。作为新一代的监控框架,Prometheus 具有以下特点:
- 多维数据模型(时序列数据由metric名和一组key/value组成)
- 在多维度上灵活的查询语言(PromQl)
- 不依赖分布式存储,单主节点工作.
- 通过基于HTTP的pull方式采集时序数据
- 可以通过push gateway进行时序列数据推送(pushing)
- 可以通过服务发现或者静态配置去获取要采集的目标服务器
- 多种可视化图表及仪表盘支持
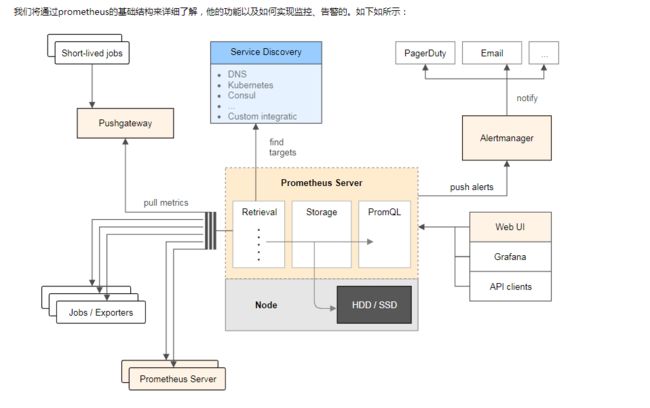
- Prometheus server 主要负责数据采集和存储,定期从静态配置的 targets 或者服务发现(主要是DNS、consul、k8s、mesos等)的 targets 拉取数据,提供PromQL查询语言的支持
- 客户端sdk 官方提供的客户端类库有go、java、scala、python、ruby,其他还有很多第三方开发的类库,支持nodejs、php、erlang等
- Push Gateway 支持临时性Job主动推送指标的中间网关
-
exporters 支持其他数据源的指标导入到Prometheus,支持数据库、硬件、消息中间件、存储系统、http服务器、jmx等
-
alertmanager 实验性组件、用来进行报警
- 主要通过grafana来实现webui展示
二、手动实验
环境准备:172.16.101.250、172.16.101.251 都已安装了docker和docker-compose服务,需要机器连网,要不然docker镜像不能自动下载。
部署规划:
| 机器 | 部署服务 |
| 172.16.101.250 | prometheus cAdvisor Node Exporter grafana |
| 172.16.101.251 | cAdvisor Node Exporter |
1、在2台机器上部署Node Exporter和cAdvisor
-
Node Exporter,负责收集 host 硬件和操作系统数据。它将以容器方式运行在所有 host 上。
-
cAdvisor,负责收集容器数据。它将以容器方式运行在所有 host 上。
1)新建 /opt/container-monitor/nodeexporter-cadvisor/docker-compose.yml
version: '2.1' services: node-exporter: image: prom/node-exporter container_name: prometheus_node-exporter restart: always logging: driver: "json-file" options: max-size: "10m" max-file: "5" ports: - 9100:9100 volumes: - /proc:/host/proc:ro - /sys:/host/sys:ro - /:/rootfs:ro command: - '--path.procfs=/host/proc' - '--path.sysfs=/host/sys' - '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/devicemapper|rootfs/var/lib/docker/aufs)($$|/)' cadvisor: image: google/cadvisor container_name: prometheus_cadvisor restart: always logging: driver: "json-file" options: max-size: "10m" max-file: "5" ports: - 9101:8080 volumes: - /:/rootfs:ro - /var/run:/var/run:rw - /sys:/sys:ro - /var/lib/docker/:/var/lib/docker:ro
2) 运行容器
cd /opt/container-monitor/nodeexporter-cadvisor
docker-compose up -d
![]()
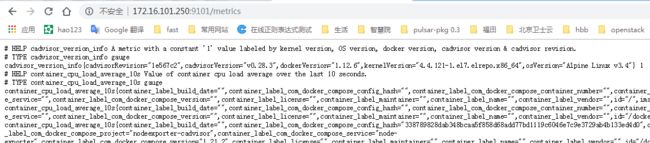
浏览器输入:http://172.16.101.250:9100/metrics 可以看到node exporter采集的host的数据

浏览器输入:http://172.16.101.250:9101/metrics 可以看到cAdvisor采集的container的数据
2、只在172.16.101.250机器上部署alertmanager
Alertmanager处理由类似Prometheus服务器等客户端发来的警报,之后需要删除重复、分组,并将它们通过路由发送到正确的接收器,比如电子邮件、Slack等。Alertmanager还支持沉默和警报抑制的机制。
1)新建 /opt/container-monitor/alertmanager/config.yml
# 全局配置项 global: resolve_timeout: 5m #处理超时时间,默认为5min smtp_smarthost: 'smtp.163.com:25' # 邮箱smtp服务器代理 smtp_from: 'xx[email protected]' # 发送邮箱名称 smtp_auth_username: 'xx[email protected]' # 邮箱名称 smtp_auth_password: 'xxx' #邮箱密码 # 定义模板信心 templates: - '/etc/alertmanager/templates/*.html' # 定义路由树信息 route: group_by: ['alertname'] # 报警分组依据 group_wait: 10s # 最初即第一次等待多久时间发送一组警报的通知 group_interval: 10s # 在发送新警报前的等待时间 repeat_interval: 1m # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝 receiver: 'email' # 发送警报的接收者的名称,以下receivers name的名称 # 定义警报接收者信息 receivers: - name: 'email' # 警报 email_configs: # 邮箱配置 - to: '[email protected]' # 接收警报的email配置 html: '{{ template "test.html" . }}' # 设定邮箱的内容模板 headers: { Subject: "[WARN] 报警邮件"} # 接收邮件的标题 webhook_configs: # webhook配置 - url: 'http://127.0.0.1:5001'
2)新建 /opt/container-monitor/alertmanager/docker-compose.yml
version: '2.1' services: alertmanager: image: prom/alertmanager container_name: alertmanager restart: always network_mode: "host" ports: - 9093:9093 logging: driver: "json-file" options: max-size: "10m" max-file: "5" volumes: - ./config.yml:/etc/alertmanager/config.yml - ./test.html:/etc/alertmanager/templates/test.html command: - '--config.file=/etc/alertmanager/config.yml' - '--storage.path=/alertmanager' - '--log.level=debug'
3)新建 /opt/container-monitor/alertmanager/test.html
{{ define "test.html" }}
| 报警项 | 实例 | 报警内容 | 开始时间 |
| {{ index $alert.Labels "alertname" }} | {{ index $alert.Labels "instance" }} | {{ index $alert.Annotations "description" }} | {{ $alert.StartsAt }} |
test.html是用来展示,告警消息的界面,展示在接收的邮箱上。
4)运行alertmanager容器
cd /opt/container-monitor/alertmanager
docker-compose up -d
![]()
3、只在172.16.101.250机器上部署prometheus
1)新建 /opt/container-monitor/prometheus/running-rule.yml ,该配置文件是prometheus中触发告警的配置文件
groups: - name: test-rule rules: - alert: "服务运行" expr: container_tasks_state{name="mysql",state="running"} == 0 for: 1m labels: severity: warning annotations: summary: "服务名:{{$labels.alertname}}" description: "容器: {{ $labels.name }} 处于运行中"
2)新建 /opt/container-monitor/prometheus/prometheus.yml,prometheus的主配置文件
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. external_labels: monitor: 'codelab-monitor' # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - 172.16.101.250:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - running-rule.yml # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['172.16.101.250:9090','172.16.101.250:9100','172.16.101.250:9101','172.16.101.251:9100','172.16.101.251:9101']
上面红色的部分:指定从哪些 exporter 抓取数据。这里指定了两台 host 上的 Node Exporter 和 cAdvisor。开头的 172.16.101.251:9090 表示会收集自己的监控数据
更多的配置可以看: https://prometheus.io/docs/prometheus/latest/configuration/configuration/
3)新建 /opt/container-monitor/prometheus/docker-compose.yml
version: '2.1' services: prometheus: image: prom/prometheus container_name: prometheus restart: always network_mode: "host" logging: driver: "json-file" options: max-size: "10m" max-file: "5" volumes: - ./running-rule.yml:/etc/prometheus/running-rule.yml:z - ./prometheus.yml:/etc/prometheus/prometheus.yml:z
4)运行prometheus容器
cd /opt/container-monitor/prometheus
docker-compose up -d
浏览输入: http://172.16.101.250:9090,可以看到promethues的数据
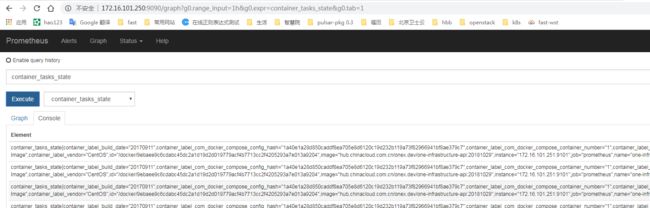
打开"Alerts",告警触发前:
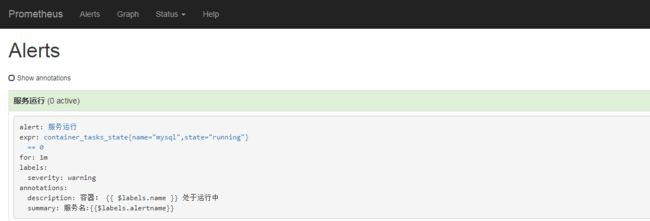
打开"Alerts",告警触发后:
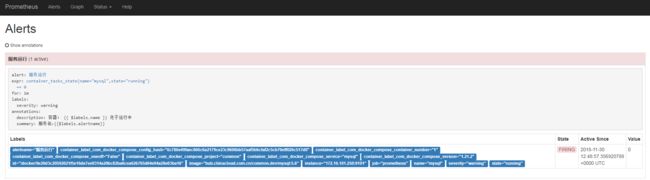
查看接收告警消息的qq邮箱:
4、只在172.16.101.250机器上部署grafana
Grafana是一个开源的度量分析与可视化套件。经常被用作基础设施的时间序列数据和应用程序分析的可视化,它在其他领域也被广泛的使用包括工业传感器、家庭自动化、天气和过程控制等。
Grafana支持许多不同的数据源。每个数据源都有一个特定的查询编辑器,该编辑器定制的特性和功能是公开的特定数据来源。
官方支持以下数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB。
每个数据源的查询语言和能力都是不同的。你可以把来自多个数据源的数据组合到一个仪表板,但每一个面板被绑定到一个特定的数据源,它就属于一个特定的组织。
1)新建 /opt/container-monitor/grafana/docker-compose.yml
version: '2.1' services: grafana: image: grafana/grafana container_name: grafana restart: always logging: driver: "json-file" options: max-size: "10m" max-file: "5" ports: - 3000:3000 environment: - GF_SERVER_ROOT_URL=http://grafana.server.name - GF_SECURITY_ADMIN_PASSWORD=123456
其中:GF_SECURITY_ADMIN_PASSWORD=secret 指定了admin用户的密码为123456
2)运行grafana容器
cd /opt/container-monitor/grafana
docker-compose up -d
浏览输入: http://172.16.101.250:3000,可以看到grafana登录界面,输入admin/123456
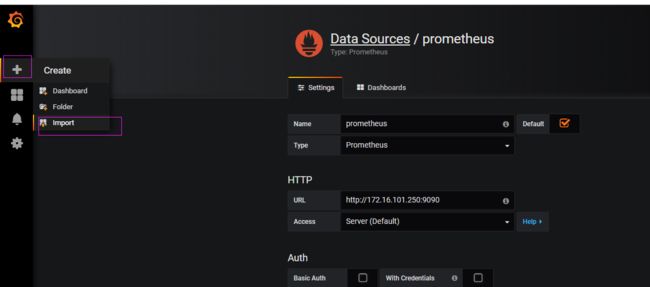
3) 在grafana中添加prometheus数据源
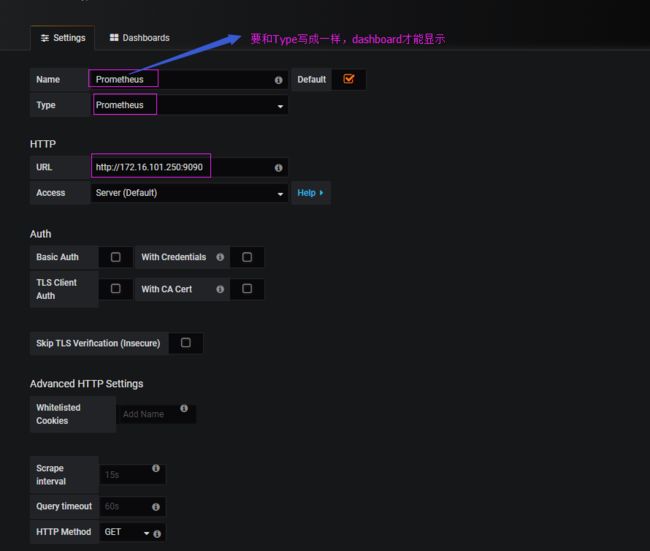
( 注意:经过多次测试发现,name如果写成其他的好像不行,必须写Prometheus才能显示,不知道是不是一个BUG)
4) 定制用于显示prometheus监控数据的dashboard,Grafana 是通过 Dashboard 展示数据的,在 Dashboard 中需要定义:
-
展示 Prometheus 的哪些多维数据?需要给出具体的查询语言表达式。
-
用什么形式展示,比如二维线性图,仪表图,各种坐标的含义等。
可以从:https://grafana.com/dashboards?dataSource=prometheus&search=docker 下载官网定制好的一些dashboard
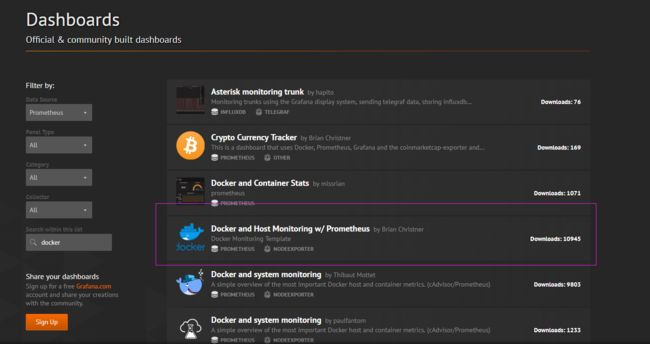
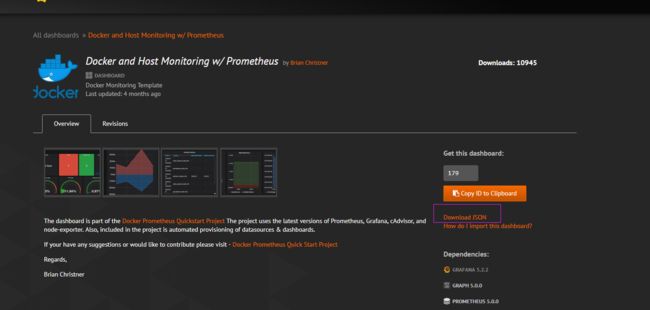
点击:Download JSON 可以下载到一个 docker-prometheus-monitoring_rev7.json 文件。下面将该json导入dashboard
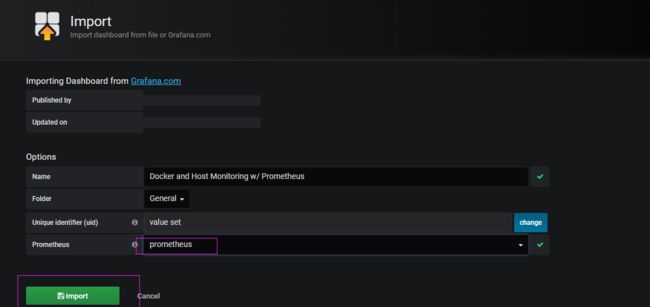
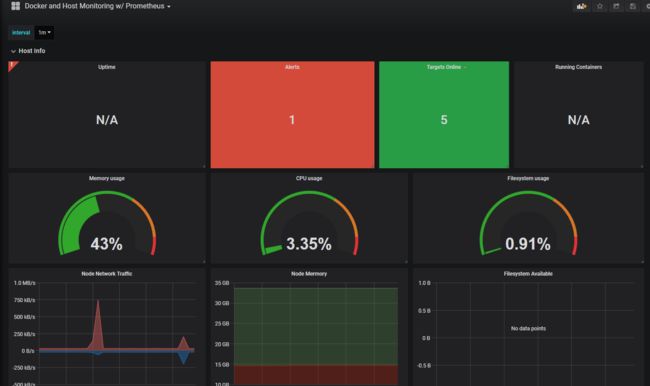
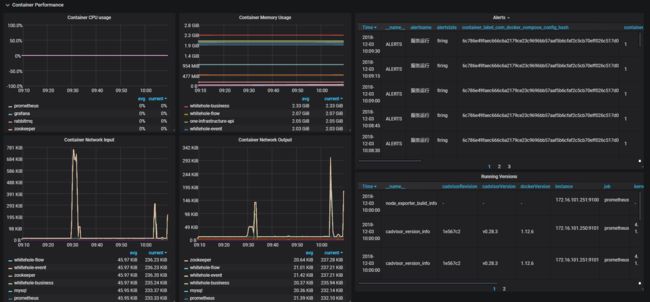
最终效果如下图所示,分为Host Info 和Container Performance