python爬虫实战---今日头条的图片抓取
本文是主要在今日头条里面的以“街拍路人”为搜索条件去提取网页的图片和标题,并把标题当做文件夹的名称,创建该文件夹,把图片保存到相应的文件夹下。
导入库
from urllib.parse import urlencode---把字典里面的数据拼接成如下字符串格式:
urlencode()的方法接受参数形式为:[(key1,value),(key2,value2),.....]或者可以是字典的形式:{‘key’:‘value1’,‘key2’:‘value2’,....}返回格式为key1=value1&key2=value2的字符串。
from urllib.error import HTTPError---进行异常处理
from multiprocessing.pool import Pool---线程池
import requests---网页请求
import os---文件操作
import re---正则表达式的使用
爬取的数据(网页)

这是其中的一部分将要提取的内容,其中的图片和标题是我们提取的重点
网页分析
从分析来看,该数据是通过异步加载AJAX,打开浏览器饿netword点击XHR再刷新网页,就可以看到格式为json的数据,点击其中一个再点击preview就可以发现在data列表里面有我们想要的数据,里面的title就是我们要抓取的数据标题,image_list列表的数据就是可以找到我们想要的图片的链接。每次我们只要请求这个url就可以了,且这个url只有offset在变化,每次只需要传入offset的值即可。
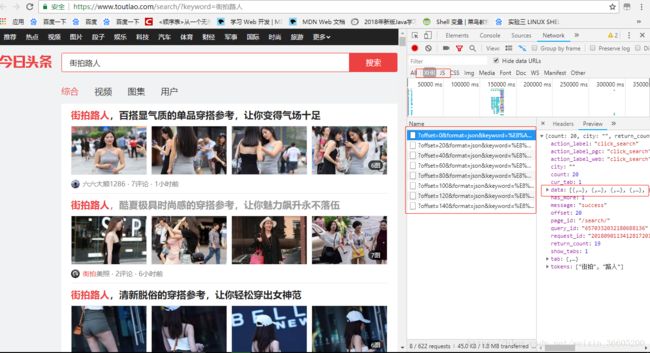
获取数据转换为json格式
def get_page(offset):
# 设置请求头
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
# 设置请求参数
data={
'offset':offset,
'format':'json',
'keyword':'街拍路人',
'autoload':'true',
'count':'20',
'cur_tab':'1',
'from':'search_tab'
}
# 把data字典里面的数据转换为字符串的格式,再去拼接字符串
url='https://www.toutiao.com/search_content/?'+urlencode(data)
try:
response=requests.get(url,headers=headers)
# 判断请求的状态(200表示请求成功)
if response.status_code == 200:
# 将结果转换成json格式再返回
return response.json()
except HTTPError:
return None数据解析
def get_images(offset):
json=get_page(offset)
if json !=None:
if json.get('data'):
for item in json.get('data'):
title=item.get('title')
images=item.get('image_list')
if images:
for img in images:
yield{
'image':img.get('url'),
'title':title
}保存图片
首先根据提取到的标题去创建该文件夹,在拼接请求的url,然后对url进行处理,把url如//p3.pstatp.com/list/pgc-image/15293938122252e5eb4198a中的15293938122252e5eb4198a作为图片的名称。
def save_images(item):
# 判断该文件夹是否存在,不存在则创建
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
# 获取图片链接,再去下载图片
try:
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
# 字符串拼接
reponse=requests.get('http:'+item.get('image'),headers=headers)
if reponse.status_code == 200:
# 正则表达式匹配url后面的数字如//p3.pstatp.com/list/pgc-image/15293938122252e5eb4198a中的15293938122252e5eb4198a
image_name=re.match('//p[0-9].*?(list/|list/pgc-image/)(.*)',item.get('image')).group(2)
if 'pgc-image/' in image_name:
# 字符串切片
image_name=image_name[10:]
elif re.search('[0-9]*/(.*)',image_name):
image_name=re.search('[0-9]*/(.*)',image_name).group(1)
# 图片的路径+名称
file_path='{0}/{1}.{2}'.format(item.get('title'),image_name,'jpg')
# 判断是否存在该图片了
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(reponse.content)
else:
print('该图片已经下载了!')
except HTTPError:
print('保存图片失败')
线程池
if __name__=='__main__':
# 创建线程池
pool=Pool()
offset=([x*20 for x in range(start,end)])
# 第一个参数是函数,第二个参数是一个迭代器,把迭代器的数字作为参数传进去
pool.map(main,offset)
# 关闭线程池
pool.close()
# 主线程阻塞等待子线程的退出
pool.join()实现结果

完整代码
链接:https://pan.baidu.com/s/1JrkGJHaJp1-apyhQNgl8_Q 密码:8mge