流式计算--实战(日志监控系统)
1.日志监控系统

数据的流向:flume+kafka+storm+mysql
数据流程如下:
-
应用程序使用log4j产生日志
- 部署flume客户端监控应用程序产生的日志信息,并发送到kafka集群中
- storm spout拉去kafka的数据进行消费,逐条过滤每条日志的进行规则判断,对符合规则的日志进行邮件告警。
- 最后将告警的信息保存到mysql数据库中,用来进行管理。
数据从flume到kafka到storm在这一篇博客中已经实现,所以这里放了方便测试在Spout里面模拟日志数据的产生
2.数据模型设计
1.用户表:用来保存用户的信息,包括账号、手机号码、邮箱、是否有效等信息


2.应用表:用来保存应用的信息,包括应用名称、应用描述、应用是否在线等信息
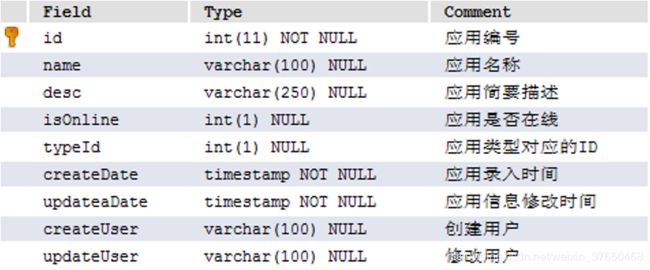

3.应用类型表: 用来保存应用的类型等信息


4.规则表:用来保存规则的信息,包括规则名称,规则描述,规则关键词等信息
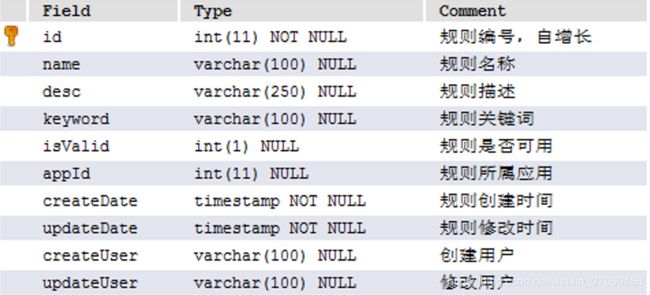

5.规则记录表:用来保存触发规则后的记录,包括告警编号、是否短信告知、是否邮件告知、告警明细等信息。

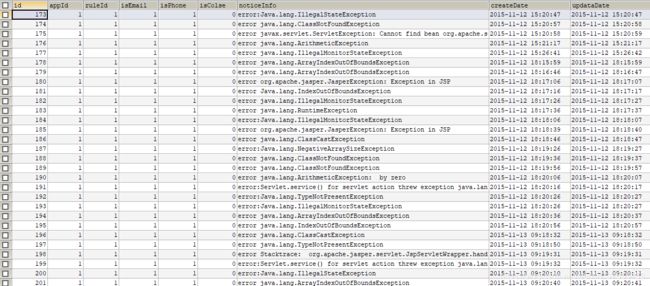
3.代码开发
新建一个maven工程,pom文件如下:
4.0.0
com.wx
logmonitoring
1.0-SNAPSHOT
org.apache.storm
storm-core
1.0.6
org.apache.storm
storm-kafka
1.0.6
org.clojure
clojure
1.7.0
org.apache.kafka
kafka_2.8.2
0.8.1
jmxtools
com.sun.jdmk
jmxri
com.sun.jmx
jms
javax.jms
org.apache.zookeeper
zookeeper
org.slf4j
slf4j-log4j12
org.slf4j
slf4j-api
com.google.code.gson
gson
2.4
redis.clients
jedis
2.7.3
javax.mail
mail
1.4.1
c3p0
c3p0
0.9.1.2
mysql
mysql-connector-java
5.1.27
commons-beanutils
commons-beanutils
1.8.2
org.springframework
spring-jdbc
4.2.0.RELEASE
org.springframework
spring-core
4.2.0.RELEASE
org.springframework
spring-context
4.2.0.RELEASE
com.aliyun
aliyun-java-sdk-core
4.0.6
com.aliyun
aliyun-java-sdk-dysmsapi
1.1.0
maven-assembly-plugin
jar-with-dependencies
com.wx.kafkaandstorm.KafkaAndStormTopologyMain
make-assembly
package
single
org.apache.maven.plugins
maven-compiler-plugin
1.7
1.7
编写一个topology:这是主线,根据这个来编写逻辑
package com.wx.logmonitor;
import com.wx.logmonitor.bolt.FilterBolt;
import com.wx.logmonitor.bolt.PrepareRecordBolt;
import com.wx.logmonitor.bolt.SaveMessage2MySql;
import com.wx.logmonitor.spout.RandomSpout;
import com.wx.logmonitor.spout.StringScheme;
import org.apache.log4j.Logger;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.apache.storm.utils.Utils;
/*
日志监控系统驱动类
*/
public class LogMonitorTopologyMain {
private static Logger logger = Logger.getLogger(LogMonitorTopologyMain.class);
public static void main(String[] args) throws Exception{
// 使用TopologyBuilder进行构建驱动类
TopologyBuilder builder = new TopologyBuilder();
// 设置kafka的zookeeper集群
// BrokerHosts hosts = new ZkHosts("zk01:2181,zk02:2181,zk03:2181");
//// // 初始化配置信息
// SpoutConfig spoutConfig = new SpoutConfig(hosts, "logmonitor", "/aaa", "log_monitor");
// 在topology中设置spout
// builder.setSpout("kafka-spout", new KafkaSpout(spoutConfig),3);
// builder.setSpout("kafka-spout",new RandomSpout(new StringScheme()),2);
builder.setSpout("kafka-spout",new RandomSpout(new StringScheme()),2);
builder.setBolt("filter-bolt",new FilterBolt(),3).shuffleGrouping("kafka-spout");
builder.setBolt("prepareRecord-bolt",new PrepareRecordBolt(),2).fieldsGrouping("filter-bolt", new Fields("appId"));
builder.setBolt("saveMessage-bolt",new SaveMessage2MySql(),2).shuffleGrouping("prepareRecord-bolt");
//启动topology的配置信息
Config topologConf = new Config();
//TOPOLOGY_DEBUG(setDebug), 当它被设置成true的话, storm会记录下每个组件所发射的每条消息。
//这在本地环境调试topology很有用, 但是在线上这么做的话会影响性能的。
topologConf.setDebug(true);
//storm的运行有两种模式: 本地模式和分布式模式.
if (args != null && args.length > 0) {
//定义你希望集群分配多少个工作进程给你来执行这个topology
topologConf.setNumWorkers(2);
//向集群提交topology
StormSubmitter.submitTopologyWithProgressBar(args[0], topologConf, builder.createTopology());
} else {
topologConf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", topologConf, builder.createTopology());
Utils.sleep(10000000);
cluster.shutdown();
}
}
}
其中RandomSpout模拟接受kafka的数据,接受的为一条一条的日志数据,因为在网络端进行nio传输,所以把他包裹成ByteBuffer对象再序列化进行传输,指定一个line域,传到下游bolt进行处理。spout主要代码:
package com.wx.logmonitor.spout;
import org.apache.storm.spout.Scheme;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import java.io.UnsupportedEncodingException;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Random;
/**
*随机产生消息发送出去
*/
public class RandomSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private TopologyContext context;
private List list ;
private final StringScheme scheme;
public RandomSpout(final StringScheme scheme) {
super();
this.scheme = scheme;
}
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
list = new ArrayList();
list.add("1$$$$$error: Caused by: java.lang.NoClassDefFoundError: com/starit/gejie/dao/SysNameDao");
list.add("2$$$$$java.sql.SQLException: You have an error in your SQL syntax;");
list.add("1$$$$$error Unable to connect to any of the specified MySQL hosts.");
list.add("1$$$$$error:Servlet.service() for servlet action threw exception java.lang.NullPointerException");
}
/**
* 发送消息 storm 框架在 while(true) 调用nextTuple方法
*/
public void nextTuple() {
final Random rand = new Random();
String msg = list.get(rand.nextInt(4)).toString();
//序列化的时候在网络上nio传输,所以需要ByteBuffer类型的数据
ByteBuffer buffer = RandomSpout.getByteBuffer(msg);
this.collector.emit(this.scheme.deserialize(buffer));
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/*
将String转化为Buffer
*/
public static ByteBuffer getByteBuffer(String str) {
return ByteBuffer.wrap(str.getBytes());
}
//消息源可以发送多条消息流stream,多条消息流可以理解为多种类型的数据
public void declareOutputFields(final OutputFieldsDeclarer declarer) {
// line
declarer.declare(this.scheme.getOutputFields());
}
}
下游的bolt接到数据后进行解析过滤处理,过滤的规则主要有看看日志信息是否来源于日志监控系统监控的应用(判断是否是isonline的应用),其次日志信息需要对照规则表,看看是否触发了警告的规则。如果这两点满足则指定应用id域和消息域传到下一个bolt处理。FilterBolt的主要代码:
package com.wx.logmonitor.bolt;
import com.wx.logmonitor.domain.Message;
import com.wx.logmonitor.utils.MonitorHandler;
import org.apache.log4j.Logger;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
/**
* Describe: 过滤规则信息
*/
//BaseRichBolt 需要手动调ack方法,BaseBasicBolt由storm框架自动调ack方法
public class FilterBolt extends BaseBasicBolt {
private static Logger logger = Logger.getLogger(FilterBolt.class);
@Override
public void prepare(Map stormConf, TopologyContext context) {
super.prepare(stormConf, context);
}
public void execute(Tuple input, BasicOutputCollector collector) {
//获取KafkaSpout发送出来的数据
String line = input.getString(0);
//获取kafka发送的数据,是一个byte数组
// byte[] value = (byte[]) input.getValue(0);
//将数组转化成字符串
// String line = new String(value);
//对数据进行解析
// appid content
//1 error: Caused by: java.lang.NoClassDefFoundError: com/starit/gejie/dao/SysNameDao
//把读到的数据转化为一个自定义消息对象,暂时只赋值了消息的内容和应用的名称两个字段
Message message = MonitorHandler.parser(line);
if (message == null) {
return;
}
//对日志进行规制判定,看看是否触发规则,如果满足条件,message的对应规则id和关键字属性会被赋值
if (MonitorHandler.trigger(message)) {
//定义两个域,输出到下游进行处理。
collector.emit(new Values(message.getAppId(), message));
}
//定时更新规则信息
MonitorHandler.scheduleLoad();
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//定义这两个域,然后输出交给下游Bolt处理。
declarer.declare(new Fields("appId", "message"));
}
}
下游接受到过滤后的消息后 就发邮件通知运维人员,并且将本次操作作为一条记录发送到下一个bolt,PrepareRecordBolt的主要代码:
package com.wx.logmonitor.bolt;
import com.wx.logmonitor.domain.Message;
import com.wx.logmonitor.domain.Record;
import com.wx.logmonitor.utils.MonitorHandler;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.log4j.Logger;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* Describe: 将触发信息保存到mysql数据库中
*/
//BaseRichBolt 需要手动调ack方法,BaseBasicBolt由storm框架自动调ack方法
public class PrepareRecordBolt extends BaseBasicBolt {
private static Logger logger = Logger.getLogger(PrepareRecordBolt.class);
public void execute(Tuple input, BasicOutputCollector collector) {
Message message = (Message) input.getValueByField("message");
String appId = input.getStringByField("appId");
//将触发规则的信息进行通知,
MonitorHandler.notifly(appId, message);
Record record = new Record();
try {
BeanUtils.copyProperties(record, message);
//定义记录域,输出这个记录交给下游处理
collector.emit(new Values(record));
} catch (Exception e) {
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("record"));
}
}
下一个Bolt接收到操作记录以后就执行插入mysql数据库的操作,保存此纪录,SaveMessage2MySql的主要代码:
package com.wx.logmonitor.bolt;
import com.wx.logmonitor.domain.Record;
import com.wx.logmonitor.utils.MonitorHandler;
import org.apache.log4j.Logger;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
/**
* Describe: 请补充类描述
*/
public class SaveMessage2MySql extends BaseBasicBolt {
private static Logger logger = Logger.getLogger(SaveMessage2MySql.class);
public void execute(Tuple input, BasicOutputCollector collector) {
Record record = (Record) input.getValueByField("record");
MonitorHandler.save(record);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
好了流程走完了,看看运行的结果:
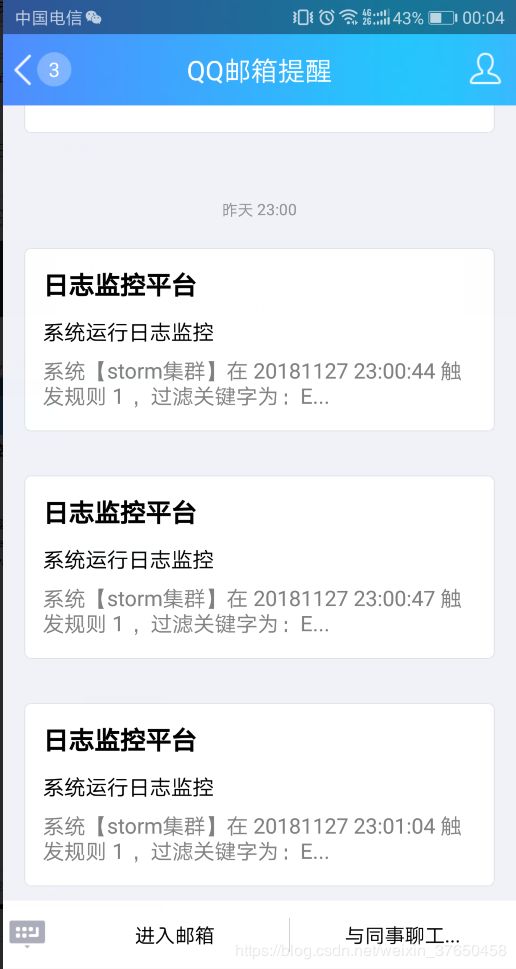

成功收到邮件,本来还想弄个短信通知,结果阿里云短信签名没有申请过,算了

最后项目的所有代码:https://github.com/WangAlainDelon/logmonitoring