- 简介
- Lock简单实用
- 主体框架
- 原理解析
- 独占锁
- AQS数据结构
- CLH数据结构
- acquire实现步骤
- addWaiter
- acquireQueued
- shouldParkAfterFailedAcquire
- parkAndCheckInterrupt
- cancelAcquire
- unparkSuccessor
- acquire
- release
- tryRelease
- 共享锁
- 获取共享锁
- doAcquireShared
- setHeadAndPropagate
- doReleaseShared
- 释放共享锁
- doReleaseShared
- tryAcquireShared
- tryReleaseShared
- 获取共享锁
- 总结
简介
AQS(AbstractQueuedSynchronizer)是并发开发中一个基础组件。主要实现了同步状态管理、线程队列管理、线程等待、线程唤醒等底层操作。JDK中许多的并发类都是依赖AQS的。 ReentrantLock(可重入锁)、Semaphore(信号量)、CountDownLatch(计数器)。
Lock简单实用
- 介绍原理前我们简单来看看Lock使用。
public static void main(String[] args) {
Integer index = 0;
ReentrantLock lock = new ReentrantLock();
List threadList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
int finalI = i;
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(new Random().nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.lock();
System.out.println(finalI);
lock.unlock();
}
});
threadList.add(thread);
}
for (Thread thread : threadList) {
thread.start();
}
}
- 就是lock 和unlock的使用。就能够保证中间的业务是有序执行的。上面不会保证输出数字有序,但是能保证输出的个数是100个,因为这里我们理解成他们会进入队列中。但是进入的顺序不确定。那么下面我们看看lock 、unlock 与我们今天的主角AQS有什么关系。
主体框架
AQS提供了一个依赖FIFO(先进先出)等待队列的阻塞锁和同步器的框架。该类是一个抽象类。其中暴露出来的方法主要用来操作状态和类别判断。这些方法我们不需要考虑阻塞问题,因为在AQS中调用这些方法的地方会处理阻塞问题
| 方法 | 描述 |
|---|---|
| boolean tryAcquire(int args) | 尝试获取独占锁 |
| boolean tryRelease(int args) | 尝试释放独占锁 |
| int tryAcquireShared(int args) | 尝试获取共享锁 |
| boolean tryReleaseShared(int args) | 尝试释放共享锁 |
| boolean isHeldExclusively() | 当前线程是否获得了独占锁 |
其他方法有AQS类实现。在AQS中实现的方法会调用到上面的抽象方法。正常子类是已内部类方式呈现的。这样的好处可以做到封闭式的同步属性。AQS内部实现的方法大概介绍
| 方法 | 描述 |
|---|---|
| void acquire(int args) | 获取独占锁,内部调用tryAcquire方法, |
| void acquireInterruptibly(int args) | 响应中断版本的acquire |
| boolean tryAcquireNanos(int args , long nanos) | 响应中断+超时版本的acquire |
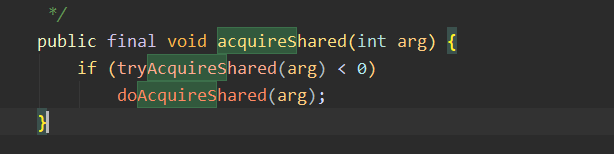
| void acquireShared(int args) | 获取共享锁,内部调用tryAcquireShared方法 |
| void acquireSharedInterruptibly(int args) | 响应中断版本的获取共享锁 |
| boolean tryAcquireSharedNonos(int args,long nanos) | 响应中断+超时获取共享锁 |
| boolean release(int args) | 释放独占锁 |
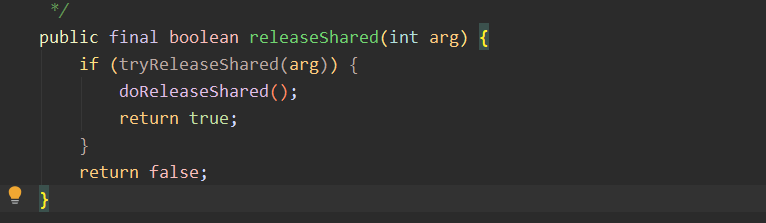
| boolean releaseShared(int args) | 释放共享锁 |
| Collection getQueuedThreads() | 获取同步队列上的线程集合 |
原理解析
AQS内部是通过一个双向链表来管理锁的(俗称CLH队列)。
当前程尝试获取锁失败时,会将当前线程包装成AQS内部类Node对象加入到CLH队列中,并将当前线程挂起。当有线程释放自己的锁时AQS会尝试唤醒CLH队列中head后的直接后继的线程。AQS的status我们可以根据他来做成不同的需求。这个后续再说。下面我们已ReentrantLock来说明下AQS原理。
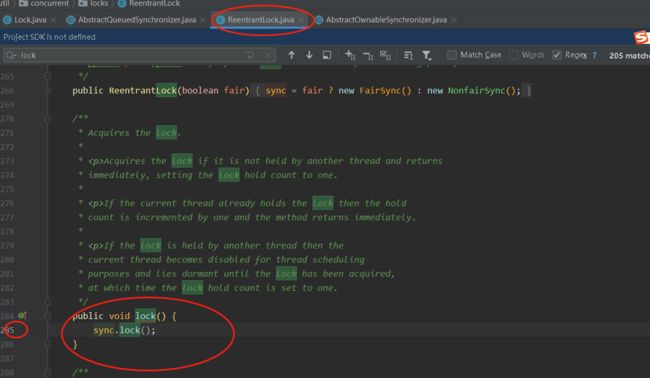
- 上面标注的是ReentrantLock中的lock方法。这个方法表示去上锁。了解Lock的都知道这个方法会一直阻塞住知道上锁成功才会执行完。而ReentrantLock.lock方法实际上的sync对象去上锁的。而sync在ReentrantLock中有公平锁和非公平锁两种。
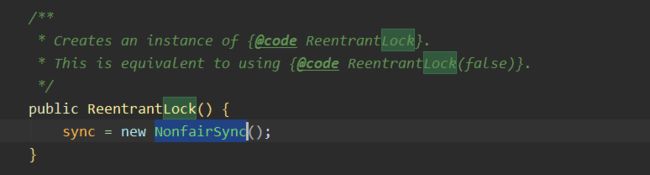
- 在AQS中默认的是非公平锁,即随机唤醒线程。

- 通过上面继承关系我们发现了我们今天的主角-AbstractQueueSynchronizer 。
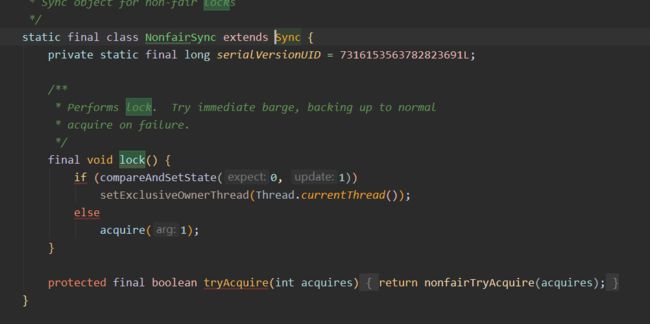
- NonfairSync实现了两个方法lock、tryAcquire方法。其中lock就是通过状态位实现锁机制的。0-未上锁;1-已上锁 。 lock的逻辑就是如果上锁成功会将状态置为1且设置独占模式的所属线程为当前线程。否则调用acquire尝试获取锁。
独占锁
AQS数据结构
- AQS里面主要是状态位的管理。下面我们看看包含的属性
Class AbstractQueuedSynchronizer{
/*队列中的头结点,无实际意义,head的后继节点才是队列中的第一个节点*/
private transient volatile Node head;
/*队列中的尾节点*/
private transient volatile Node tail;
/*队列中的状态,上锁解锁 可以扩展成不同的状态 。 AQS实际上也是对该字段的管理。子类中通过get set compare方法对state的管理*/
private volatile int state;
}
CLH数据结构
- 上面我们了解到会将线程包装成Node对象加入到双向链表(CLH)中。下面我们看看Node的结构吧
static final class Node {
/*共享模式的标记*/
static final Node SHARED = new Node();
/*独占模式的标记*/
static final Node EXCLUSIVE = null;
/*队列等待状态-取消*/
static final int CANCELLED = 1;
/*队列等待状态-唤醒*/
static final int SIGNAL = -1;
/*队列等待状态-条件等待*/
static final int CONDITION = -2;
/*队列等待状态-广播*/
static final int PROPAGATE = -3;
/*队列等待状态,取值范围就是上面的等待状态之一*/
volatile int waitStatus;
/*前驱节点*/
volatile Node prev;
/*后继节点*/
volatile Node next;
/*节点对应的线程:绑定关系*/
volatile Thread thread;
/*TODO*/
Node nextWaiter;
/*判定是否是共享模式*/
final boolean isShared() {
return nextWaiter == SHARED;
}
/*获取当前节点的前驱节点,如果没有前驱节点抛出NullPointerException*/
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
/*用于创建双向链表中的Head节点,其实Head节点就是一个标志并不会与线程挂钩。相当于一个队列的默认头节点。或者用来创建共享模式的节点。因为共享模式的节点就是无参构造*/
Node() {
}
/*将线程包装成Node对象加入队列中,源码中是用来添加Thread至队列*/
Node(Thread thread, Node mode) {
this.nextWaiter = mode;
this.thread = thread;
}
/*常用语加入条件状态队列中TODO*/
Node(Thread thread, int waitStatus) {
this.waitStatus = waitStatus;
this.thread = thread;
}
}
acquire实现步骤
-
上面我们了解到Lock中实现lock的底层是AQS的acquire实现的。
-
通过查看源码我们大概能了解到其上锁的流程,
- 首先尝试获取锁
- 获取锁失败后,将当前线程包装成Node对象添加到CLH队列中
- 自行阻塞当前线程,等待队列唤醒自己
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
addWaiter
/**
* 通过Node对象的构造函数构造Node对象添加到CLH队列中
* 这个方法主要是双向链表的操作。C++的同学应该会很容易理解
*/
private Node addWaiter(Node mode) {
/*当前线程加入队列后此时是没有后继节点的,且已独占模式访问的
*所以这里加入的Node在上一不传入的是Node.EXCLUSIVE,这里就表示
*是已独占模式进行上锁从而进行加入队列的
*/
Node node = new Node(Thread.currentThread(), mode);
/*获取队列中的最后一个Node节点;这里是进行快速插入测试。
*默认队列已经在堆积Node节点了这个时候直接将节点追加到tail里。
*其实这里和enq()方法是一样的逻辑。只不过enq里面会进行等待队列
*正常才会加入
*/
Node pred = tail;
if (pred != null) {
/*队列已经产生线程等待就会将当前node节点的前驱节点只为tail
*的复制节点
*/
node.prev = pred;
/*基于CAS(内部UnSafe实现)设置尾部为node节点*/
if (compareAndSetTail(pred, node)) {
/*原本的tail节点的后继节点自然就是node节点*/
pred.next = node;
/*到这里node节点就已经加入了CLH队列中*/
return node;
}
}
/*逻辑同上,不在赘述*/
enq(node);
return node;
}
acquireQueued
- 这里传的Node是我们上一步刚刚添加到队尾的节点。为什么不直接用tail节点呢?我们仔细观察发现tail的修饰
private transient volatile Node tail;
- 我们知道
volatile是内存可见的。什么叫内存可见。我们的属性变量是存储在内存中的。每次有线程启动访问这个类的时候都会复制内存中属性值到自己线程中。所以在多线程情况下修改了这个属性就会出现问题因为A线程修改了值但是B线程并无法感知还是以原先的值进行交互。这就是典型的多线程带来的问题。而volatile做到了的线程感知。当A线程修改了tail后立马B线程就感知到了。但是这并不能彻底的解决多并发的问题。这里我们简单介绍下这个关键字 - 经过上面简单阐述高并发场景,所以这里不能直接用tail。因为这个时候tail很有可能已经不是我们的tail的。这里直接传递Node节点是非常明智的选择。而且是final修饰的。更加保证了使我们上一步骤添加到队尾的那个节点
/**
* 再次尝试获取锁,对中断不敏感。
*/
final boolean acquireQueued(final Node node, int arg) {
/*失败标志位*/
boolean failed = true;
try {
/*线程是否被打断标志位*/
boolean interrupted = false;
/**/
for (;;) {
/*获取当前想成包装的Node节点的前驱节点*/
final Node p = node.predecessor();
/*如果前驱节点是head节点表示当前节点在队首可以尝试
*获取下锁,这里为什么是尝试获取呢因为这个时候可能锁
*还被其他线程占着。这里尝试获取纯粹就是试试机会
*/
if (p == head && tryAcquire(arg)) {
/*成功获取到锁,说明我们试一试的心态成功了。
*人生也一样,总得试一试万一成功了呢。看源码还
*能学到人生道理呢。划重点
*/
/*这个时候在tryAcquire中已经被当前线程占用了锁了。
*我们这里不需要担心其他线程会抢占,这个时候我们
*需要将当前线程从队列中踢出,直接将当前线程置为
*head节点。setHead方法也很简单,将node的前驱节
*点置为null,因为head是首位,首位之前不应该在
*有节点了,然后线程也被销毁了
*/
setHead(node);
/*p节点是老的head节点这个时候已经不需要了。
*这里jdk的操作是将next至为null, 这样p节点
*就成为不可达状态,接下来的命运就是等待被GC。
*这里我们不是将p置为null的原因是我们p=null ,
*只是将p指向null, 但是原先的head的那个Node的
*地址任然通过Node进行指向,GC是无法回收的。好好理解下*/
p.next = null; // help GC
/*这里我们已经获取了。而且成功上了锁。所以这里就
* 无法取消获取了,而且我们已经将Node剔除了,也
* 没有必要再进行取消获取操作了。所以在finnally中
* 就没必要执行了*/
failed = false;
/*返回线程是否被中断状态*/
return interrupted;
}
/*如果当前线程对应的Node节点不是head的后继节点或者
* 没有获取到锁,这个时候我们开始阻塞线程*/
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
/*取消当前线程对应的Node节点在队列中排队。这里可以
*理解成弃权操作。这里取消会顺便遍历之前的节点如果
* 有弃权的这里会一并操作掉
*/
cancelAcquire(node);
}
}
shouldParkAfterFailedAcquire
/**
* 在失败获取锁的情况下判断是否需要对线程进行阻塞并同意修改线程
* 在队列中状态。如果前驱节点是SIGNAL状态那么node节点就进入
* 准备状态。前驱节点CANEL状态需要剔除。如果是CONDITION或者
* PROGAGATE状态,在ReentrantLock中我们暂时不考虑这两者情况,
* 所以这里就强制转换为SIGNAL状态
*/
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
/*获取前驱节点的状态*/
int ws = pred.waitStatus;
/*如果前驱节点是等待通知状态,那么当前节点需要等待前驱
* 结点被唤醒,所以这里需要被阻塞
*/
if (ws == Node.SIGNAL)
return true;
/*如果前驱节点>0,即为canclled状态*/
if (ws > 0) {
//这里其实和cancelAcquire逻辑差不多,需要将取消的节点从队列中剔除
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*剩下的情况,统一将节点状态更正为等待通知状态*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
parkAndCheckInterrupt
/**
* 阻塞当前线程,等待被唤醒
*/
private final boolean parkAndCheckInterrupt() {
/*这里就是阻塞线程,并等待LockSupport.unpark唤醒*/
LockSupport.park(this);
/*在park之后我们需要Thread.interrupted恢复下线程的中断状态,
* 这样下一次park才会生效。否则下一次的park不会生效的
*/
return Thread.interrupted();
}
cancelAcquire
/**
* 将node节点之前(包括当前node)取消状态的全部剔除
*/
private void cancelAcquire(Node node) {
if (node == null)
return;
/*剔除操作需要解绑node和thread关系*/
node.thread = null;
/*获取node的前驱节点*/
Node pred = node.prev;
/*大于0就是取消状态*/
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
Node predNext = pred.next;
/*这里直接置为取消状态,是为了方便其他线程进行取消是的操作,
* 也是为了方便跳跃该节点
*/
node.waitStatus = Node.CANCELLED;
/*如果node是队尾的haul,那么将队尾设置成node的前驱结点*/
if (node == tail && compareAndSetTail(node, pred)) {
/*将队尾的pred节点的后继节点置空,这是一个队列的标准要求*/
compareAndSetNext(pred, predNext, null);
} else {
//如果是非队尾节点
int ws;
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
/*pred节点状态如果是有效节点且不是head,将pred的后继
* 节点指向node的后继节点。这里和C++指针指向是一个道理*/
Node next = node.next;
if (next != null && next.waitStatus <= 0)
/*node的后继节点是有效节点且不是取消状态,进行替换*/
compareAndSetNext(pred, predNext, next);
} else {
/*
* 这里就是对上面提到的阻塞进行放行。里面
* 实际上是LockSupport.unpark进行放行的。
* 这个时候我们通过上面的if知道,这个时候在以下几种场景出现
* 1、pred==head
* 2、pred是取消状态
* 3、pred.thread==null 即不是有效节点
* 以上这些情况都表示pred不是能进行唤醒的节点,我们
* 这里理解为不是标准节点。这个时候为了保证队列的活跃性,
* 我们需要唤醒后继节点,实际上就是node的后继节点。
*/
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
- 在上面代码中当代码执行到
unparkSuccessor(node)这一块时就会去唤醒node节点。但是我们的canelAcquire方法是为了取消node节点之前取消状态的节点的。这样就会与我们功能违背。命名方法是为了剔除canel节点。现在确实去唤醒node节点。这里我们上面shouldParkAfterFailedAcquire方法中在状态>0时回去自动剔除这些节点的。这样就实现了canelAcquire方法的功能了。所以我们不需要纠结。
ps: 源码终究是源码,考虑的是非常全面的。
if (ws > 0) {
//这里其实和cancelAcquire逻辑差不多,需要将取消的节点从队列中剔除
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
}
unparkSuccessor
/**
* 唤醒node节点
*/
private void unparkSuccessor(Node node) {
/*获取当前节点的状态*/
int ws = node.waitStatus;
/*对状态进行判断*/
if (ws < 0)
/*若果小于0,则进行强制纠偏为0*/
compareAndSetWaitStatus(node, ws, 0);
/*获取当前节点的后继节点*/
Node s = node.next;
/*判断*/
if (s == null || s.waitStatus > 0) {
/*后继节点为有效节点且状态>0 , 这里即为CANCELLED状态,
* 则将该节点在CLH中剔除,并进行断层连接*/
s = null;
/*这里和向前去除取消状态的前驱节点一样,只不过这里是向后
*至于为什么是从后向前呢,是为了避免高并发带来的节点不一
* 致性。因为从node开始往后的话,很有可能后面会被其他
* 线程修改了。因为添加节点的往后添加的。所以从后往前的话这样能保证数据一致。但是这样就会导致其他线程添加的节点是无法访问到的。这一点和数据一致性比较还是前者比较重要。此次获取不到没关系,在获取锁的时候jdk使用的是for循环。会不停的检查队列中节点是否可以被唤醒的。这里我们理解是一个定时器。所以一次获取不到节点没关系。总有一次会被唤醒。
*/
for (Node t = tail; t != null && t != node; t = t.prev)
/*head节点状态应该是0,所以这里最后s就是head.所以后面释放* 的就是head的后继节点。*/
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
/*这里对应的是parkAndCheckInterrupt中的
* LockSupport.lock(this)方法。unpark
* 之后parkAndCheckInterrupt方法就会执行到Thread.interrupted
* 并进行返回,这个时候回返回true*/
LockSupport.unpark(s.thread);
}
acquire
- 到这里acquire执行步骤我们按照方法维度一一进行阅读了。我们大概梳理下就是第一步获取锁,获取失败就会加入队列,这个时候该线程会被阻塞,在加入队列的过程中会进行针对队列进行无效节点去除(取消状态或者参数null等情况)。保证队列里的node都是有效且活跃的节点。这个过程会保证队列是运转的。如果加入队列顺利的话下一步就是自行的中断线程进行挂起
Thread.currentThread().interrupt();,其实执行到这一步就表示这个线程已经不需要了。被取消了。后续会将这个线程作废。
下面贴出一个来自于博客园大神的原理图

release
- 获取独占锁的逻辑还是很复杂的,里面涉及到操作双向链表的操作,如果没有接触过C++应该还是很吃力的。其实在获取的逻辑中已经牵涉了释放的逻辑。在我们唤醒node的后继节点其实也是释放逻辑中的重头戏。

public final boolean release(int arg) {
/*会调用tryRelease,这个方法是有子类实现的。我们在ReentrantLock
* 中应该是非公平锁实现的tryRelease。这个方法后面会说。
* 这里我们需要提一点的:当一个线程获取到锁时,它对应的Node是
* 不会再队列中的。所以这里释放我们可以理解成唤醒Head的后继节点。
* 这里就和上面唤醒node的后继节点一样了。所以你会看到同样的
* 方法*unparkSuccessor(h)
*/
if (tryRelease(arg)) {
/*获取CLH队列中的队首节点*/
Node h = head;
if (h != null && h.waitStatus != 0)
/*唤醒head节点的后继节点*/
unparkSuccessor(h);
return true;
}
return false;
}
- 这里需要解释下为什么会对head节点进行判断。因为AQS中head默认的null。那么head是什么创建的呢。是在我们上面加锁的时候加入,在加入队列后需要进行前驱结点判断的时候创建head的。这个时候的head没有设置状态。那么这个状态是默认0的。所以上面判断只需要判空就行了。但是为了严谨JDK进行双重判断了。
private transient volatile Node head;
- 所以这里需要对head进行判空。
tryRelease
- 其实在上面acquire步骤讲解中,我们漏掉了
tryAcquire方法的阅读。目的是为了和tryRelease方法进行合并讲解。因为这两个方法都是交由子类实现的。放在一起讲我们更加能理解设计 。 在ReentrantLock中tryAcquire是有非公平锁的nonfairTryAcquire实现的
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
/*首先获取独占锁的state*/
int c = getState();
if (c == 0) {
/*c==0表示当前独占锁没有被任何线程占用。这个时候是可以加锁的*/
if (compareAndSetState(0, acquires)) {
/*设置当前拥有次所的线程为当前线程*/
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
/*因为这个判断,实现了可重入式的锁,这样一个线程可以重复上锁操作。*/
/*c!=0表示已有线程占用。如果是当前线程的表示被重入了。那么这个独占锁state就会继续累加。这里的state是AQS的state和Node里面waitStaus是两回事。在这里累加在释放方法里就是递减。这样对比我们就容易理解了。这里的status不同的实现有着不同的定位功能*/
int nextc = c + acquires;
if (nextc < 0) // overflow
/*这里的判断着实没有看懂。希望大神指点。*/
throw new Error("Maximum lock count exceeded");
/*CAS设置state*/
setState(nextc);
return true;
}
return false;
}
protected final boolean tryRelease(int releases) {
/*看完tryAcquire中递增的操作,我们就能理解这里递减的逻辑了*/
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
/*c==0表示这个线程因为可重入的上锁方式,完全的释放的独占锁。这个时候才可以被别的线程占用*/
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
共享锁
-
共享锁的实现主要应用场景就是在读场景。独占锁应用场景就是写场景。这个在
ReentrantReadWriteLock类中使用了这两种场景。上面独占锁我们通过ReentrantLock阅读了一遍。下面我们通过ReentrantReadWriteLock来体验下共享锁的逻辑吧。 -
共享锁逻辑有所变动。但是里面涉及到的方法在独占锁中都提到了。下面我们会提及下未提到的方法。公用的方法聪明的你应该是阅读明白了。
- 同样
tryAcquireShared方法这里暂时不看。到后面和释放方法一起阅读。我们先来通过doAcquireShared方法为入口进行阅读
获取共享锁
doAcquireShared
/**
* 这个方法仔细看其实和独占锁acquire是一样的逻辑。只不过方法全都提到方* 法内部了。
* addWaiter和独占锁中是一个方法
* 后面的for循环也是一样的,如果是head的后继节点则会执尝试获取锁,并替* 换head。并且如果线程阻塞过就会自行中断线程等操作。所以看完独占锁在* 学习共享锁就很容易了。两者虽有不同但是还是及其相似的
*/
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
/*如果前驱节点是head节点就会去尝试获取锁,有可能会成功*/
int r = tryAcquireShared(arg);
if (r >= 0) {
/*获取成功就会将节点剔除,从而head节点指向最新节点*/
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}

setHeadAndPropagate
/**
* progagate表示当前共享锁的容量
* node 表示当前线程对应的Node
*/
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
/*
* 在方法外部已经确保了Progagate>=0
* progagate=0表示当前共享锁已经无法被获取了。所以这里条件
* 之一 progagte>0
* 1、progagate>0 那么就会查看队列中后继节点是否符合条件,如果符* 合的 则通过doReleaseShared方法进行唤醒队列中head的后继节点
* 2、head==null 表示AQS还没有创建head这个时候出发释放的方法是为* 了让释放这个过程启动。内部实现因为是for循环。相当于监听head节点
* 3、head.waitStatus<0 表示在doReleaseShared被设置成
* Node.PROGAGATE属性了。释放锁的时候会设置head的状态从
* SIGNAL置为0,也会从0置为PROGAGATE。head节点默认的状态也是0,
* 所以这里的head状态小于0只可能是被另外一个线程释放资源是
* 执行了置为PROGAGATE的代码了。虽然progagate==0但是只是
* 获取那会是0在高并发场景下会被改变的。既然另外一个线程释放
* 资源那么这里自然就可以去唤醒队列线程去尝试获取。这里条件判断
* 我们后面整个逻辑讲完会重新梳理下这个地方
*/
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
doReleaseShared
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
/*获取head*/
int ws = h.waitStatus;
/*
*head节点状态默认是0,所以在队列中第一次应该是进入
*下面的if中并且设置head节点为传播状态;设置成传播状
*态的目的是为了方便对应上面我们方法中的
*判断h.waitStatus < 0 。这样就会去唤醒head节点
*的后继节点了。这个时候可能会失败但是共享就是让他
*们尽可能的获取。所以这里设置传播状态。也有可能
*会经过shouldParkAfterFailedAcquire方法将传播
*状态纠偏为SIGNAL状态,也就是后面会被纠正过来。这个
*时候需要和shouldParkAfterFailedAcquire对比,
*shouldParkAfterFailedAcquire是遇到SIGNAL状态对
*后继节点进行阻塞,而在这里是遇到SIGNAL状态就进行释放
*/
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
/*与独占锁一样*/
unparkSuccessor(h);
}
/*这里就是设置传播状态,与setHeadAndPropagate方法对应*/
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
释放共享锁
- tryReleaseShared同理是交由子类实现的。后面我们通过ReentrantReadWriteLock类来看这两个方法实现逻辑。最终AQS的释放逻辑还是放在的doReleaseShared方法上。
doReleaseShared
- 在上面阅读获取共享锁时,设置head节点后会检查后继节点,判断是否需要唤醒的时候就是doReleaseShared 。 所以这个方法这里也不需要说了。
tryAcquireShared
/**
* 与读锁不冲突的前提下获取写锁,有剩余的前提下会一直获取直至获取成功,
* 获取失败返回 -1
* 获取成功返回 1
*/
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState();
/*exclusiveCount就是c与独占锁容量的一个与运算。共享容量2^16-1
*所以只要c!=0 exclusiveCount(c)就!=0,另一个条件时判断是否
*是当前线程。这个也是可重入式锁的凭证
*/
/*
* 读锁和写锁是互斥的,所以这里如果其他线程已经获取了写锁,那么
* 读锁就没法获取了。
*/
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
/*sharedCount就是获取共享锁的容量*/
int r = sharedCount(c);
/*readerShouldBlock就是判断是否需要对该节点进行阻塞,只要是有
*效节点且是共享节点就不阻塞;读锁写锁是一个32位表示的,高位写
*锁低位读锁,SHARED_UNIT是低16位,所以这里就是增加读锁次数*/
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
/*表示第一次读*/
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
/*第一次读的线程重复读,累计线程读取次数*/
firstReaderHoldCount++;
} else {
/*实际上就是一个ThreadLocal管理读的次数。和上面firstReader作用一样。*/
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
/*高并发场景下CAS叠加次数不一定会成功,这个时候需要*fullTryAcquireShared再次获取读锁,这个方法逻辑和上面可以说是
*一样的。那么为什么他叫full ,因为里面用了循环确保在有剩余的条件
*下一只获取读锁。不会因为CAS的问题获取不到*/
return fullTryAcquireShared(current);
}
tryReleaseShared
/**
* 这里只要有读锁存在就会返回false ,这里有个疑问,
* 如果返回false那么AQS的release就无法去释放队列。这种情况
* 是因为队列本身是活跃的。会按顺序释放锁的。而读锁的释放
* 其实在tryReleseShared里就释放了。读锁其实就是计数。
* 这里会在ReentrantReadWriteLock章节详细解说
*/
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
if (firstReader == current) {
// 当前线程是第一个获取读锁的。这里会加读的次数一直递减。
//当前线程全部释放完了,就接触当前线程的占位
if (firstReaderHoldCount == 1)
firstReader = null;
else
firstReaderHoldCount--;
} else {
//这里针对非第一个获取读锁的线程进行释放。显示次数的释放
//完全释放后就丢弃线程
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
int count = rh.count;
if (count <= 1) {
readHolds.remove();
if (count <= 0)
throw unmatchedUnlockException();
}
--rh.count;
}
//这里和上面的fullTryAcquireShared对应。循环释放一直到释放成功为止
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc))
// Releasing the read lock has no effect on readers,
// but it may allow waiting writers to proceed if
// both read and write locks are now free.
return nextc == 0;
}
}
总结
AQS是jdk中并发类的一个底层原理。好多jdk的并发类都是基于此实现的。AQS其实就是一个框架。简单总结几句话
- AQS是并发的一个基类
- 内部维护了FIFO队列
- 拥有两种模式: 独占模式(写锁)、共享模式(读锁)
内部state就是表示锁的状态。不同的实现可以有不同的定义。
ReentrantLock : 纯粹锁的状态 +1、-1
Semaphore : 锁的个数
CountDownLatch: 计数器,一个标志位