MXNet之Kaggle猫狗分类实战
dogs VS cats
- 1.数据准备
- 2.训练模型
- 2.1 基础训练
- 2.2 对比实验(无数据增强)
- 2.3 对比实验(不用预训练模型)
- 2.4 对比实验(改变学习率)
- 2.5 对比实验(固定部分参数训练)
- 3.测试模型
此项目是kaggle大赛的经典项目.
- 通过对比实验验证数据增强对降低模型过拟合风险的作用.
- 对预训练模型进行微调达到加快模型收敛的效果.
- 对比不同初始学习率,固定部分参数层对模型训练过程的影响
1.数据准备
- 下载cats vs dogs数据集.包含三部分.
- 解压后,通过下面指令将cat和dog图片分到相应的文件夹里.
cd data/train
mv dog.* dog/
mv cat.* cat/
-将训练集分成训练集+验证集(9:1)
# data/data表示生成的".lst"文件的保存路径和文件名前缀,比如data_train.lst和data_val.lst
#data/train表示要处理图像所在路径
#--list表示接下来的执行会生成.lst文件
#--recursive表示迭代搜索图像路径
#--train-ratio,表示数据化分比例,0.9表示将数据划分10份,训练集:验证集=9:1
python tools/im2rec.py data/data data/train --list --recursive --train-ratio 0.9
- 生成RecordIO文件
#--num-thread 8 代表采用8线程来生成RecordIO文件
#data/data_train.lst或data/data_val.lst表示要处理的.lst文件所在路径.
#data/train表示图像所在路径
python tools/im2rec.py --num-thread 32 data/data_train.lst data/train
python tools/im2rec.py --num-thread 32 data/data_val.lst data/train

2.训练模型

2.1 基础训练
- train.py
import argparse #导入命令行参数管理模块
import mxnet as mx
import os #导入路径管理模块
import logging #导入日志管理模块
def get_fine_tune_model(sym, num_classes, layer_name):
"""
替换原网络结构中全连接层的操作
"""
#(1) #得到所有层信息
all_layers = sym.get_internals()
#(2) 通过看.json文件,找到全连接层的前一层,此处为"faltten0"
net = all_layers[layer_name + '_output']
#(3)在后面添加新的全连接层和Softmax回归层
net = mx.symbol.FullyConnected(data=net, num_hidden=num_classes,
name='new_fc')
net = mx.symbol.SoftmaxOutput(data=net, name='softmax')
return net
def multi_factor_scheduler(args, epoch_size):
"""
(1)首先要根据设置的间隔(args.step),计算实际要修改学习率的epoch.
例如:args.step=5,args.num_epoch=10,则step=[5,10]
也就是当训练到第5个和第10个epoch时就要修改学习率.
(2)根据epoch_size(一个epoch里有多少batch_size)计算实际修改学习率的迭代批次是多少
得到的批次用"step_"表示.
"""
step = range(args.step, args.num_epoch, args.step)
step_bs = [epoch_size * (x - args.begin_epoch) for x in step
if x - args.begin_epoch > 0]
#返回学习率变化对象
if step_bs:
return mx.lr_scheduler.MultiFactorScheduler(step=step_bs,
factor=args.factor)
return None
def data_loader(args):
"""
数据读取
通过 mx.io.ImageRecordIter()函数
"""
data_shape_list = [int(item) for item in args.image_shape.split(",")]
data_shape = tuple(data_shape_list)
train = mx.io.ImageRecordIter(
path_imgrec=args.data_train_rec, #该参数表示RecordIO文件路径
path_imgidx=args.data_train_idx, #该参数表示index文件路径
label_width=1, #该参数表示每张图像的标签数量,默认是1,也就是单标签分类
mean_r=123.68, #rgb三通道的均值,模型在读取图像后,会减去这三通道的均值
mean_g=116.779,
mean_b=103.939,
data_name='data', #该参数与网络结构构建时,设置的输入变量名相同,默认是"data"
label_name='softmax_label', #该参数与网络结构构建时,设置的输入变量名相同,默认是"softmax_label"
data_shape=data_shape, #该参数可设置真正模型用于训练的数据尺寸,分类任务常用(3,224,224)
batch_size=args.batch_size, #但卡GPU常用的设置有32,64,128,一般网络结构越复杂(深宽),此参数应该设置越小
rand_mirror=args.random_mirror, #是否对输入图像做随机镜像操作,一般设置为True
max_random_contrast=args.max_random_contrast, #随机对比对调整,为了做数据增强,此处设置为0.3.
max_rotate_angle=args.max_rotate_angle, #随机旋转图像时的最大角度,默认是15,正负15度随机旋转图像.
shuffle=True, #对训练数据随机打乱顺序,验证数据不需要
resize=args.resize_train) #对输入图像短边缩放到指定尺寸.
val = mx.io.ImageRecordIter(
path_imgrec=args.data_val_rec,
path_imgidx=args.data_val_idx,
label_width=1,
mean_r=123.68,
mean_g=116.779,
mean_b=103.939,
data_name='data',
label_name='softmax_label',
data_shape=data_shape,
batch_size=args.batch_size,
rand_mirror=0,
shuffle=False,
resize=args.resize_val) #验证集缩放到224,训练集resize到256
return train,val
def train_model(args):
#(1)调用data_loader()函数读取并验证数据集.
train, val = data_loader(args)
#(2)导入预训练模型
sym, arg_params, aux_params = mx.model.load_checkpoint(prefix=args.model,
epoch=args.begin_epoch)
#并调用get_fine_tune_model()模型对导入的网络做修改,使其可以应用到猫狗分类中.
new_sym = get_fine_tune_model(sym, args.num_classes, args.layer_name)
#(3)设定计算学习变化策略:lr_scheduler,
#设置训练过程中每隔args.step个epoch次就执行一次当前学习率乘以args.factor做为新的学习率操作
epoch_size = max(int(args.num_examples / args.batch_size), 1) #计算1个epoch包含多少个batch数据
#(4)得到可用的学习率变化对象
lr_scheduler = multi_factor_scheduler(args, epoch_size)
#(5)构造优化相关的字典:学习率,动量参数,正则项参数,学习率变化策略
optimizer_params = {'learning_rate': args.lr,
'momentum': args.mom,
'wd': args.wd,
'lr_scheduler': lr_scheduler}
#(6)设定网络参数初始化方式
initializer = mx.init.Xavier(rnd_type='gaussian',
factor_type="in",
magnitude=2)
#(7)设置模型训练的环境
if args.gpus == '':
devs = mx.cpu()
else:
devs = [mx.gpu(int(i)) for i in args.gpus.split(',')]
#(8)设置是否在训练过程中固定部分网络层参数,设置为False,也就是不固定.
#如果固定模型预训练参数,则只是更新新增的全连接层参数.
if args.fix_pretrain_param:
fixed_param_names = [layer_name for layer_name in
new_sym.list_arguments() if layer_name not in
['new_fc_weight', 'new_fc_bias', 'data',
'softmax_label']]
else:
fixed_param_names = None
#(9)根据前面得道的新的网络结构和训练环境,初始化一个Module对象model,用于后续的模型训练.
model = mx.mod.Module(context=devs,
symbol=new_sym,
fixed_param_names=fixed_param_names)
#(10)设置日志的批次显式间隔batch_callback;设置训练得到的模型保存路经epoch_callback,保存的epoch间隔默认是1
batch_callback = mx.callback.Speedometer(args.batch_size, args.period)
epoch_callback = mx.callback.do_checkpoint(args.save_result + args.save_name)
#(11)判断是否使用预训练的模型参数初始化网络结构,如果args.from_scratch为True,
#则网络结构中的所有参数都使用指定的随机初始化方式.否则就使用预训练的模型参数.
if args.from_scratch:
arg_params = None
aux_params = None
#(12)开启训练,评价参数选择准确率"acc"和和交叉熵损失."ce"
model.fit(train_data=train,
eval_data=val,
begin_epoch=args.begin_epoch,
num_epoch=args.num_epoch,
eval_metric=['acc','ce'],
optimizer='sgd',
optimizer_params=optimizer_params,
arg_params=arg_params,
aux_params=aux_params,
initializer=initializer,
allow_missing=True,
batch_end_callback=batch_callback,
epoch_end_callback=epoch_callback)
def parse_arguments():
parser = argparse.ArgumentParser(description='score a model on a dataset')
parser.add_argument('--model', type=str, default='model/resnet-18')
parser.add_argument('--gpus', type=str, default='0')
parser.add_argument('--batch-size', type=int, default=64)
parser.add_argument('--begin-epoch', type=int, default=0)
parser.add_argument('--image-shape', type=str, default='3,224,224')
parser.add_argument('--resize-train', type=int, default=256)
parser.add_argument('--resize-val', type=int, default=224)
parser.add_argument('--data-train-rec', type=str, default='data/data_train.rec')
parser.add_argument('--data-train-idx', type=str, default='data/data_train.idx')
parser.add_argument('--data-val-rec', type=str, default='data/data_val.rec')
parser.add_argument('--data-val-idx', type=str, default='data/data_val.idx')
parser.add_argument('--num-classes', type=int, default=2)
parser.add_argument('--lr', type=float, default=0.005)
parser.add_argument('--num-epoch', type=int, default=10)
parser.add_argument('--period', type=int, default=100)
parser.add_argument('--save-result', type=str, default='output/resnet-18/')
parser.add_argument('--num-examples', type=int, default=22500)
parser.add_argument('--mom', type=float, default=0.9, help='momentum for sgd')
parser.add_argument('--wd', type=float, default=0.0001, help='weight decay for sgd')
parser.add_argument('--save-name', type=str, default='resnet-18')
parser.add_argument('--random-mirror', type=int, default=1,
help='if or not randomly flip horizontally')
parser.add_argument('--max-random-contrast', type=float, default=0.3,
help='Chanege the contrast with a value randomly chosen from [-max, max]')
parser.add_argument('--max-rotate-angle', type=int, default=15,
help='Rotate by a random degree in [-v,v]')
parser.add_argument('--layer-name', type=str, default='flatten0',
help='the layer name before fullyconnected layer')
parser.add_argument('--factor', type=float, default=0.2, help='factor for learning rate decay')
parser.add_argument('--step', type=int, default=5, help='step for learning rate decay')
parser.add_argument('--from-scratch', type=bool, default=False,
help='Whether train from scratch')
parser.add_argument('--fix-pretrain-param', type=bool, default=False,
help='Whether fix parameters of pretrain model')
args = parser.parse_args() #得到解析解析之后的结果
return args
def main():
args = parse_arguments() #得到配置参数信息
if not os.path.exists(args.save_result): #判断项目根目录下是否有args.save_result文件
os.makedirs(args.save_result) #没有的话创造一个output/resnet-18
logger = logging.getLogger() #用getLogger()方法得到一个日志记录器
logger.setLevel(logging.INFO) #用setLevel()方法设置日志级别,logging.INFO代表代码正常运行时的日志
stream_handler = logging.StreamHandler() #显示日志:用logging.StreamHandler()得到一个显示管理对象
logger.addHandler(stream_handler) #调用记录器的addHandler()方法添加显式管理对象
file_handler = logging.FileHandler(args.save_result + '/train.log') #在指定目录下保存train.log
logger.addHandler(file_handler) #添加文件管理对象
logger.info(args) #调用记录器的info()方法,将日志打印并保存
train_model(args=args)
if __name__ == '__main__':
main()
输出结果:
/home/yuyang/anaconda3/envs/mxnet/bin/python3.5 /home/yuyang/下载/MXNet-Deep-Learning-in-Action-master/demo8/train.py
Namespace(batch_size=64, begin_epoch=0, data_train_idx='data/data_train.idx', data_train_rec='data/data_train.rec', data_val_idx='data/data_val.idx', data_val_rec='data/data_val.rec', factor=0.2, fix_pretrain_param=False, from_scratch=False, gpus='0', image_shape='3,224,224', layer_name='flatten0', lr=0.005, max_random_contrast=0.3, max_rotate_angle=15, model='model/resnet-18', mom=0.9, num_classes=2, num_epoch=10, num_examples=22500, period=100, random_mirror=1, resize_train=256, resize_val=224, save_name='resnet-18', save_result='output/resnet-18/', step=5, wd=0.0001)
[16:19:30] src/io/iter_image_recordio_2.cc:172: ImageRecordIOParser2: data/data_train.rec, use 4 threads for decoding..
[16:19:31] src/io/iter_image_recordio_2.cc:172: ImageRecordIOParser2: data/data_val.rec, use 4 threads for decoding..
[16:19:31] src/nnvm/legacy_json_util.cc:209: Loading symbol saved by previous version v0.8.0. Attempting to upgrade...
[16:19:31] src/nnvm/legacy_json_util.cc:217: Symbol successfully upgraded!
[16:19:32] src/operator/nn/./cudnn/./cudnn_algoreg-inl.h:97: Running performance tests to find the best convolution algorithm, this can take a while... (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
Epoch[0] Batch [0-100] Speed: 598.06 samples/sec accuracy=0.942605 cross-entropy=0.141113
Epoch[0] Batch [100-200] Speed: 601.85 samples/sec accuracy=0.970938 cross-entropy=0.075483
Epoch[0] Batch [200-300] Speed: 595.75 samples/sec accuracy=0.975000 cross-entropy=0.062475
Epoch[0] Train-accuracy=0.965110
Epoch[0] Train-cross-entropy=0.088422
Epoch[0] Time cost=38.478
Saved checkpoint to "output/resnet-18/resnet-18-0001.params"
Epoch[0] Validation-accuracy=0.984766
Epoch[0] Validation-cross-entropy=0.037735
Epoch[1] Batch [0-100] Speed: 597.06 samples/sec accuracy=0.987469 cross-entropy=0.035933
Epoch[1] Batch [100-200] Speed: 591.36 samples/sec accuracy=0.979531 cross-entropy=0.052544
Epoch[1] Batch [200-300] Speed: 594.66 samples/sec accuracy=0.985156 cross-entropy=0.041689
Epoch[1] Train-accuracy=0.983975
Epoch[1] Train-cross-entropy=0.042967
Epoch[1] Time cost=37.872
Saved checkpoint to "output/resnet-18/resnet-18-0002.params"
Epoch[1] Validation-accuracy=0.984375
Epoch[1] Validation-cross-entropy=0.042658
...
Epoch[4] Batch [0-100] Speed: 581.36 samples/sec accuracy=0.993502 cross-entropy=0.018758
Epoch[4] Batch [100-200] Speed: 574.00 samples/sec accuracy=0.994219 cross-entropy=0.015950
Epoch[4] Batch [200-300] Speed: 576.01 samples/sec accuracy=0.994062 cross-entropy=0.016261
Update[1756]: Change learning rate to 1.00000e-03
Epoch[4] Train-accuracy=0.993901
Epoch[4] Train-cross-entropy=0.017082
Epoch[4] Time cost=38.880
Saved checkpoint to "output/resnet-18/resnet-18-0005.params"
Epoch[4] Validation-accuracy=0.988782
Epoch[4] Validation-cross-entropy=0.033209
....
Epoch[9] Batch [0-100] Speed: 562.11 samples/sec accuracy=0.998762 cross-entropy=0.004998
Epoch[9] Batch [100-200] Speed: 563.92 samples/sec accuracy=0.997812 cross-entropy=0.006729
Epoch[9] Batch [200-300] Speed: 559.84 samples/sec accuracy=0.997969 cross-entropy=0.006392
Epoch[9] Train-accuracy=0.998219
Epoch[9] Train-cross-entropy=0.005792
Epoch[9] Time cost=39.935
Saved checkpoint to "output/resnet-18/resnet-18-0010.params"
Epoch[9] Validation-accuracy=0.991186
Epoch[9] Validation-cross-entropy=0.029301
Process finished with exit code 0
- train.log
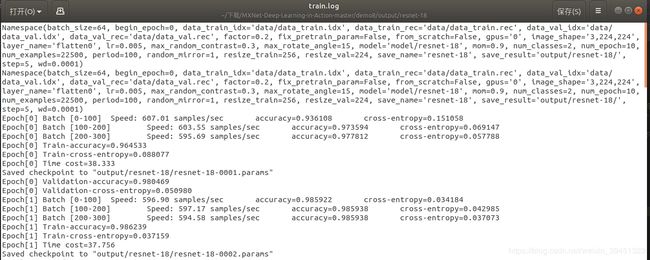
我们可以看到准确率指标稳定上升,损失值指标稳定下降,说明模型正常收敛.
2.2 对比实验(无数据增强)
去掉数据增强操作,观察损失值有什么变化.
python train.py -- random-mirror 0 --max-random-contrast 0 --max-rotate-angle 0
结果分析:
在不采用数据增强时,训练损失值下降的很快,epoch4的训练损失值=0.006(数据增强时0.02),但不一定是好事,可能出现了过拟合,其验证损失值=0.04.(数据增强是时0.03)
Epoch[0] Batch [0-100] Speed: 591.66 samples/sec accuracy=0.945080 cross-entropy=0.134108
Epoch[0] Batch [100-200] Speed: 594.87 samples/sec accuracy=0.977500 cross-entropy=0.057181
Epoch[0] Batch [200-300] Speed: 595.09 samples/sec accuracy=0.977187 cross-entropy=0.057500
Epoch[0] Train-accuracy=0.968350
Epoch[0] Train-cross-entropy=0.078805
Epoch[0] Time cost=38.720
Saved checkpoint to "output/resnet-18/resnet-18-0001.params"
Epoch[0] Validation-accuracy=0.985547
Epoch[0] Validation-cross-entropy=0.033728
....
Epoch[4] Batch [0-100] Speed: 557.46 samples/sec accuracy=0.998453 cross-entropy=0.004323
Epoch[4] Batch [100-200] Speed: 558.68 samples/sec accuracy=0.998125 cross-entropy=0.005861
Epoch[4] Batch [200-300] Speed: 561.00 samples/sec accuracy=0.997969 cross-entropy=0.006845
Update[1756]: Change learning rate to 1.00000e-03
Epoch[4] Train-accuracy=0.998264
Epoch[4] Train-cross-entropy=0.005579
Epoch[4] Time cost=40.096
Saved checkpoint to "output/resnet-18/resnet-18-0005.params"
Epoch[4] Validation-accuracy=0.985176
Epoch[4] Validation-cross-entropy=0.044792
数据增强时的epoch4参数.

2.3 对比实验(不用预训练模型)
python train.py --from-scratch True
结果:
Epoch[4] Batch [0-100] Speed: 557.28 samples/sec accuracy=0.838181 cross-entropy=0.363909
Epoch[4] Batch [100-200] Speed: 559.41 samples/sec accuracy=0.841875 cross-entropy=0.355515
Epoch[4] Batch [200-300] Speed: 553.89 samples/sec accuracy=0.852969 cross-entropy=0.341681
Update[1756]: Change learning rate to 1.00000e-03
Epoch[4] Train-accuracy=0.845486
Epoch[4] Train-cross-entropy=0.351955
Epoch[4] Time cost=40.303
Saved checkpoint to "output/resnet-18/resnet-18-0005.params"
Epoch[4] Validation-accuracy=0.830128
Epoch[4] Validation-cross-entropy=0.423667
...
Epoch[9] Batch [0-100] Speed: 548.28 samples/sec accuracy=0.905631 cross-entropy=0.232318
Epoch[9] Batch [100-200] Speed: 547.21 samples/sec accuracy=0.899531 cross-entropy=0.236987
Epoch[9] Batch [200-300] Speed: 550.73 samples/sec accuracy=0.899687 cross-entropy=0.243477
Epoch[9] Train-accuracy=0.902021
Epoch[9] Train-cross-entropy=0.235464
Epoch[9] Time cost=40.895
Saved checkpoint to "output/resnet-18/resnet-18-0010.params"
Epoch[9] Validation-accuracy=0.876603
Epoch[9] Validation-cross-entropy=0.276692
结果分析:
模型收敛速度慢,epoch4的训练损失值是0.35,而采用预训练模型时,epoch4的训练损失值是0.017.
2.4 对比实验(改变学习率)
python train.py --from-scratch True --lr 0.05
Epoch[4] Batch [0-100] Speed: 547.06 samples/sec accuracy=0.879950 cross-entropy=0.278402
Epoch[4] Batch [100-200] Speed: 537.53 samples/sec accuracy=0.878906 cross-entropy=0.281853
Epoch[4] Batch [200-300] Speed: 551.04 samples/sec accuracy=0.895938 cross-entropy=0.246313
Update[1756]: Change learning rate to 1.00000e-02
Epoch[4] Train-accuracy=0.887687
Epoch[4] Train-cross-entropy=0.263102
Epoch[4] Time cost=41.163
Saved checkpoint to "output/resnet-18/resnet-18-0005.params"
Epoch[4] Validation-accuracy=0.902244
Epoch[4] Validation-cross-entropy=0.240522
...
Epoch[9] Batch [0-100] Speed: 544.82 samples/sec accuracy=0.944616 cross-entropy=0.133948
Epoch[9] Batch [100-200] Speed: 545.64 samples/sec accuracy=0.945000 cross-entropy=0.135435
Epoch[9] Batch [200-300] Speed: 532.97 samples/sec accuracy=0.938750 cross-entropy=0.142885
Epoch[9] Train-accuracy=0.944266
Epoch[9] Train-cross-entropy=0.135271
Epoch[9] Time cost=41.598
Saved checkpoint to "output/resnet-18/resnet-18-0010.params"
Epoch[9] Validation-accuracy=0.927083
Epoch[9] Validation-cross-entropy=0.181487
结果分析:
对于随机初始化的网络结构,训练的模型来说,学习率大一些网络收敛的更快.
本例中lr=0.05.epoch4 的train_loss=0.263,
对比2.3节,随机初始化整个网络lr=0005时,train_loss=0.35
证明了对于随机初始化的网络结构,训练的模型来说,学习率大一些网络收敛的更快.
2.5 对比实验(固定部分参数训练)
不固定参数:不管是采用预训练模型还是随机初始化模型,网络结构所有参数都是一起训练的.
固定参数:保持部分层参数不变,只训练更新指定层的参数.比如保持预训练模型的参数不变,只训练更新新增的全连接层参数.
python train.py --fix-pretrain-param True
输出结果:
Epoch[4] Batch [0-100] Speed: 1754.36 samples/sec accuracy=0.971225 cross-entropy=0.076322
Epoch[4] Batch [100-200] Speed: 1759.87 samples/sec accuracy=0.967969 cross-entropy=0.078722
Epoch[4] Batch [200-300] Speed: 1735.87 samples/sec accuracy=0.971094 cross-entropy=0.075975
Update[1756]: Change learning rate to 1.00000e-03
Epoch[4] Train-accuracy=0.969017
Epoch[4] Train-cross-entropy=0.079722
Epoch[4] Time cost=13.039
Saved checkpoint to "output/resnet-18/resnet-18-0005.params"
Epoch[4] Validation-accuracy=0.973958
Epoch[4] Validation-cross-entropy=0.067827
...
Epoch[9] Batch [0-100] Speed: 1725.35 samples/sec accuracy=0.974474 cross-entropy=0.067883
Epoch[9] Batch [100-200] Speed: 1718.98 samples/sec accuracy=0.967812 cross-entropy=0.076035
Epoch[9] Batch [200-300] Speed: 1730.80 samples/sec accuracy=0.972031 cross-entropy=0.069142
Epoch[9] Train-accuracy=0.971644
Epoch[9] Train-cross-entropy=0.070536
Epoch[9] Time cost=13.026
Saved checkpoint to "output/resnet-18/resnet-18-0010.params"
Epoch[9] Validation-accuracy=0.973157
Epoch[9] Validation-cross-entropy=0.064164
epoch4的损失值对比,相比不固定预训练模型层参数时,效果要差得多.原因主要是可训练的参数较少.很难完美的完成从imagenet到猫狗数据集的迁移.可以尝试累加几个全连接层,增加训练参数.观察模型结果是否发生了变化.
固定参数的做法可处理大约1700张图片/s,但是不固定参数时,只能处理大约550/s.
因此,速度提升非常明显.
3.测试模型
import mxnet as mx
import numpy as np
def load_model(model_prefix, index, context, data_shapes, label_shapes):
"""
模型导入函数
"""
#(1)导入模型
sym, arg_params, aux_params = mx.model.load_checkpoint(model_prefix, index)
#(2)基于网络结构和环境初始化一个Module对象model
model = mx.mod.Module(symbol=sym, context=context)
#(3)将数据信息和网络结构绑定在一起构成执行器
model.bind(for_training=False,
data_shapes=data_shapes,
label_shapes=label_shapes)
#(4)完成一个网络结构的参数赋值
model.set_params(arg_params=arg_params,
aux_params=aux_params,
allow_missing=True)
return model
def load_data(data_path):
"""
读取数据
"""
#(1)通过mx.image.imread()接口读取图像数据
data = mx.image.imread(data_path)
#(2)将读取进来的数据的数值类型转成float32
cast_aug = mx.image.CastAug()
#(3)将图像resize到指定尺寸
resize_aug = mx.image.ForceResizeAug(size=[224, 224])
#(4)对输入图像的像素值做归一化处理
norm_aug = mx.image.ColorNormalizeAug(mx.nd.array([123, 117, 104]),
mx.nd.array([1, 1, 1]))
cla_augmenters = [cast_aug, resize_aug, norm_aug]
for aug in cla_augmenters:
data = aug(data)
#(5)做通道变换[H, W, C]---->[C, H, W]
data = mx.nd.transpose(data, axes=(2, 0, 1))
#(6)通过mx.nd.expand_dims()接口增加第0维度,使输出数据变成4维
data = mx.nd.expand_dims(data, axis=0)
#(7)封装到可用于模型前向计算的输入数据
data = mx.io.DataBatch([data])
return data
def get_output(model, data):
"""
获取预测结果
"""
#(1)执行前向操作
model.forward(data)
#(2)得到模型输出,取第0个任务的第0张图像的NDArray向量,大小为1*N本例中为1*2,
#该向量的每个值代表图像属于每个类别的概率
#再调用NDArray的asnumpy()方法,得到Numpy array结构的结果
cla_prob = model.get_outputs()[0][0].asnumpy()
#(3)调用 np.argmax()接口,得到概率最大值所对应的下标.
cla_label = np.argmax(cla_prob)
return cla_label
def main():
label_map = {0: "cat", 1: "dog"}
model_prefix = "output/resnet-18/resnet-18"
index = 10
context = mx.gpu(0)
data_shapes = [('data', (1, 3, 224, 224))]
label_shapes = [('softmax_label', (1,))] #1是batch_size=1的含义
#(1)模型导入
model = load_model(model_prefix, index, context, data_shapes, label_shapes)
#(2)数据读取及预处理
data_path = "data/demo_img1.jpg"
data = load_data(data_path)
#(3)预测结果0/1
cla_label = get_output(model, data)
print("Predict result: {}".format(label_map.get(cla_label)))
if __name__ == '__main__':
main()
待预测图片:
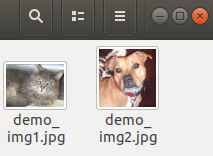
结果(预测正确):
/home/yuyang/anaconda3/envs/mxnet/bin/python3.5 /home/yuyang/下载/MXNet-Deep-Learning-in-Action-master/demo8/demo.py
[21:13:44] src/operator/nn/./cudnn/./cudnn_algoreg-inl.h:97: Running performance tests to find the best convolution algorithm, this can take a while... (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
Predict result: cat
Process finished with exit code 0