Sqoop使用总结——导入数据到大数据集群import
目录
RDBMS到HDFS
RDBMS到Hive
RDBMS到Hbase
RDBMS到HDFS
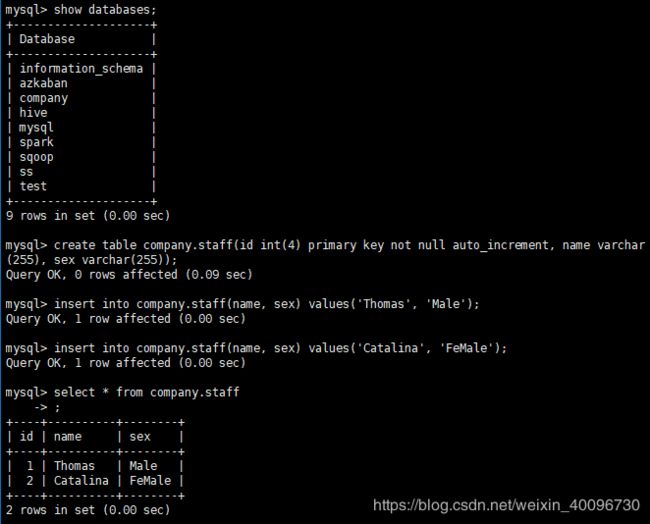
1) 确定Mysql服务开启正常
2) 在Mysql中新建一张表并插入一些数据
$ mysql -uroot -proot
mysql> create database company;
mysql> create table company.staff(id int(4) primary key not null auto_increment, name varchar(255), sex varchar(255));
mysql> insert into company.staff(name, sex) values('Thomas', 'Male');
mysql> insert into company.staff(name, sex) values('Catalina', 'FeMale');
3) 导入数据
其中有报错信息与解决,在报错import报错中有例子
(1)全部导入
$ bin/sqoop import \
--connect jdbc:mysql://hadoop000:3306/company \
--username root \
--password root \
--table staff \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"

delete-target-dir:该文件如果有的话就删除
导入成功图:


(2)查询导入
$ bin/sqoop import \
--connect jdbc:mysql://hadoop000:3306/company \
--username root \
--password root \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select name,sex from staff where id <=1 and $CONDITIONS;'
提示:must contain '$CONDITIONS' in WHERE clause. 所以后面必须加 $CONDITIONS
如果query后使用的是双引号,则$CONDITIONS前必须加转义符,防止shell识别为自己的变量。
如:
--query "select name,sex from staff where id <=1 and \$CONDITIONS;"

(3)导入指定列
$ bin/sqoop import \
--connect jdbc:mysql://hadoop000:3306/company \
--username root \
--password root \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns id,sex \
--table staff
提示:columns中如果涉及到多列,用逗号分隔,分隔时不要添加空格
(4)使用sqoop关键字筛选查询导入数据
$ bin/sqoop import \
--connect jdbc:mysql://hadoop000:3306/company \
--username root \
--password root \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--table staff \
--where "id=1"
注意:跟query跟table一起使用会有问题

RDBMS到Hive
$ bin/sqoop import \
--connect jdbc:mysql://hadoop000:3306/company \
--username root \
--password root \
--table staff \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table staff_hive
提示:该过程分为两步,第一步将数据导入到HDFS,第二步将导入到HDFS的数据迁移到Hive仓库,第一步默认的临时目录是/user/用户/表名,我的是/user/hadoop/staff
注意:导入hive成功后,会将该表名的整个临时目录删除掉。
其中出现过一些报错有记录->在笔记的"报错解决"下->import到hive过程中报错,但是中间结果已经写入到了hdfs,再次执行报文件已存在

import到hive过程中报错,但是中间结果已经写入到了hdfs,再次执行报文件已存在
在项目生产上,用sqoop导入时候一般先判断文件是否存在,存在的话先删除旧文件再执行导入脚本。
添加这个参数
--delete-target-dir \

20/04/01 22:34:15 WARN security.UserGroupInformation: PriviledgedActionException as:hadoop (auth:SIMPLE) cause:org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://hadoop000:8020/user/hadoop/staff already exists
20/04/01 22:34:15 ERROR tool.ImportTool: Encountered IOException running import job: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://hadoop000:8020/user/hadoop/staff already exists
成功日志:


RDBMS到Hbase
启动HBase之前要把HDFS、YARN、zookeeper开启
$ bin/sqoop import \
--connect jdbc:mysql://hadoop000:3306/company \
--username root \
--password root \
--table staff \
--columns "id,name,sex" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_company" \
--num-mappers 1 \
--split-by id
提示:sqoop1.4.6只支持HBase1.0.1之前的版本的自动创建HBase表的功能
不过我用的sqoop-1.4.6-cdh5.7.0、hbase-1.2.0-cdh5.7.0是可以自动创建的 !!
解决方案:手动创建HBase表
hbase> create 'hbase_company,'info'
(5) 在HBase中scan这张表得到如下内容
hbase> scan ‘hbase_company’
